







今天两道 删除排序链表中的重复元素 的题哦
题目1
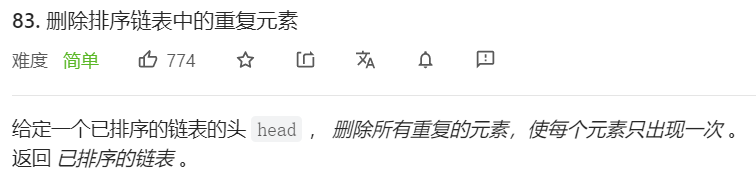
题解
自己的做法:一次遍历,哈希表存结点值,找到重复的就删
思路挺简单,细节还挺多,交了三次才成功…
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null)
return head;
Set<Integer>hashSet=new HashSet<>();
hashSet.add(head.val);
ListNode p=head;
while(p!=null&&p.next!=null){
if(hashSet.contains(p.next.val)){
ListNode r=p.next;
p.next=r.next;
r=null;
}
else{
hashSet.add(p.next.val);
p=p.next;
}
}
return head;
}
}
时间复杂度: O ( n ) O(n) O(n)
空间复杂度: O ( n ) O(n) O(n)
but! 题目中说了链表是升序的,所以重复元素都是相邻的,因此其实可以不用哈希表,直接判断前后两个结点值是否相同,然后删除就行!
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null)
return head;
ListNode p=head;
while(p!=null&&p.next!=null){
if(p.val==p.next.val){
ListNode r=p.next;
p.next=r.next;
r=null;
}
else
p=p.next;
}
return head;
}
}
时间复杂度: O ( n ) O(n) O(n)
空间复杂度: O ( 1 ) O(1) O(1)
题目2
题目1的升级款:
82. 删除排序链表中的重复元素 II【中等】
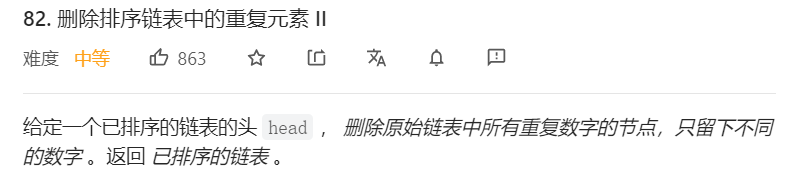
题解
这题只要你有重复元素,一个都不留,包括你自己,而上一题你自己是可以留下的
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if(head==null||head.next==null)
return head;
ListNode dummyHead=new ListNode(0,head);//可能删除头结点时,需要用虚拟头结点
ListNode pre=dummyHead,p=head;
while(p!=null&&p.next!=null){
if(p.val==p.next.val){
int x=p.val;
while(p.next!=null&&p.next.val==x)
p=p.next;
pre.next=p.next;
}
else
pre=p;
p=p.next;
}
return dummyHead.next;
}
}
有了上一题的基础,这题就是秒过~
时间复杂度: O ( n ) O(n) O(n)
空间复杂度: O ( 1 ) O(1) O(1)















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









