






Chapter 1
- Software Verification(软件验证) + Software Validation(软件确认) = Software Testing
- Verification 和 Validation区别
- Verification 内部过程,比喻:Are we building the product right ?
- Validation 外部过程,比喻: Are we building the right product ?
测试覆盖的类型
- graph coverage
- logic coverage
- input partition coverage
- syntax coverage
Chapter 2
faults & Errors & Failuers
- Fault(故障): A static defect in the software
- Error(错误): An incorrect internal state that is the manifestation(表现) of some fault
- Failure(失败): External, incorrect behavior with respect to the requirementxs or other description of the expected behaviour
- Faults in software are equivalent to design mistakes in hardware
- 做个比喻:有个病人去看病,病人的症状为failure,诊断出的病根为fault(根源),而之间做的一些检测(比如不正常的血压,不正常的心跳等)为error
- 实际代码例子
对于软件测试来说,有源代码,有测试用例,而Fault是问题的根源,所以肯定是和源代码有关而不和测试用例有关的;而当我们将测试用例跑起来的时候,可能在设计上的失误会导致运行过程中的异常状态,这就是Error;测试用例的预期结果是否和实际运行结果相符,这里就说的是Failure

其实三个概念,正好分别对应了测试源代码,测试用例,测试结果。
RIPR
如何设计测试用揭示程序错误?使用RIPR模型,设计测试用例的时候需要满足四个条件
- Reachability(可达性): 测试用例必须能够到达程序包含fault的地方
- Infection(传染性):必须导致内部状态错误出现
- Propagation(传播性):错误的内部状态必须导致外部或者最终程序状态错误
- Revealability():断言是否与错误的结果有交集?测试者必须能够观察到不正确的状态
Testing & Debugging
- testing: 通过观察一个软件的执行来评估这个软件,有可能某一个测试用例的执行会导致一个failure
- debugging: 通过一个给定的可以观测的failure来寻找程序的一个fault,并不是所有的输入都会触发failure从而触发fault
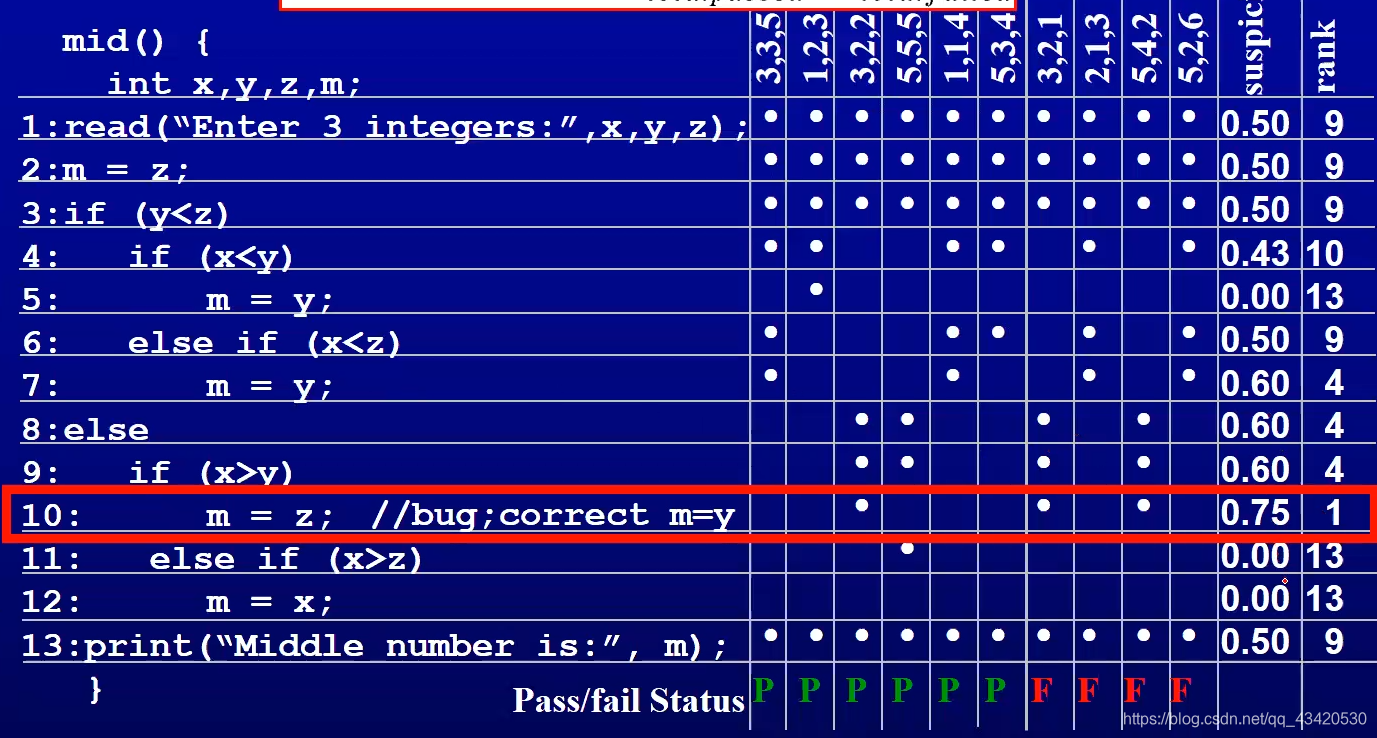
Tarantula
计算每一个代码单元的可疑值(suspicious value)越高的话可能出错可能性越大
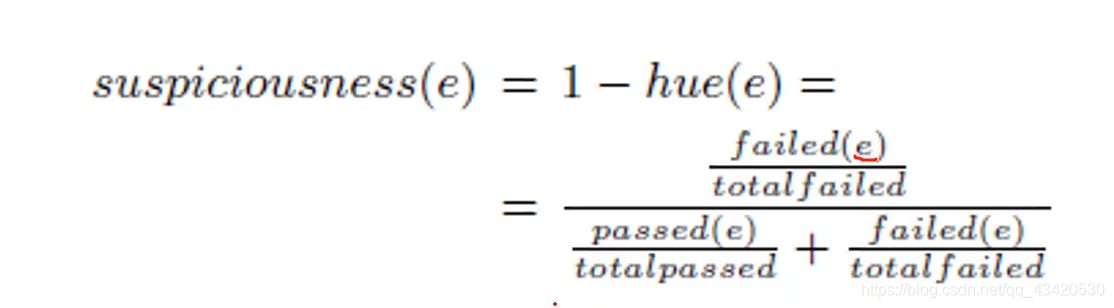
所有相关的量
- 所有通过的测试用例数
- 所有失败的测试用例数
- 经过这行成功的测试用例数
- 经过这行失败的测试用例数
测试活动的分类
- test design
- criteria-based
- human-based
- test automation
- test execution
- test evaluation
测试过程的安排MDTD(Model-Driven Test Design)
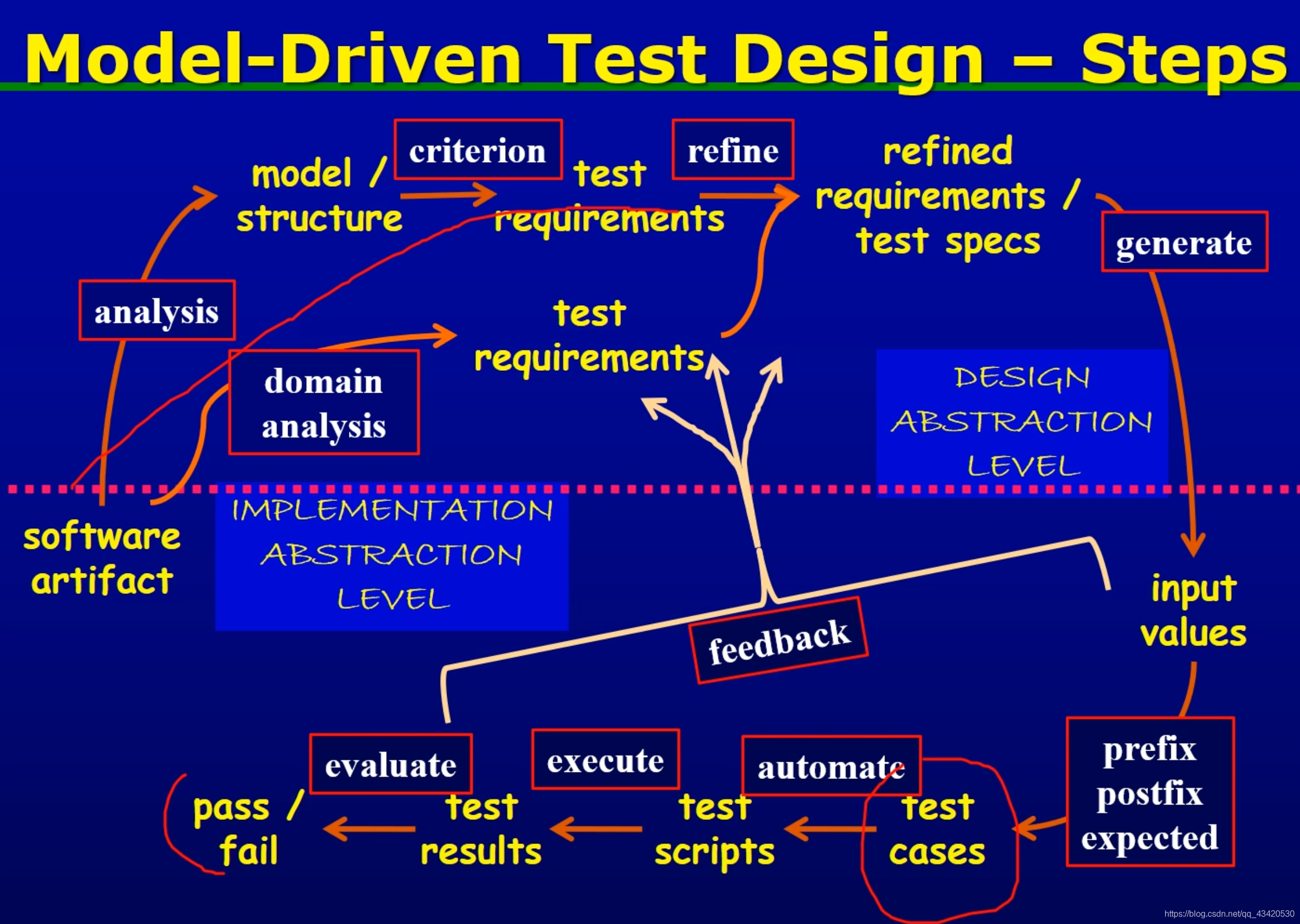
与四个测试活动的关系
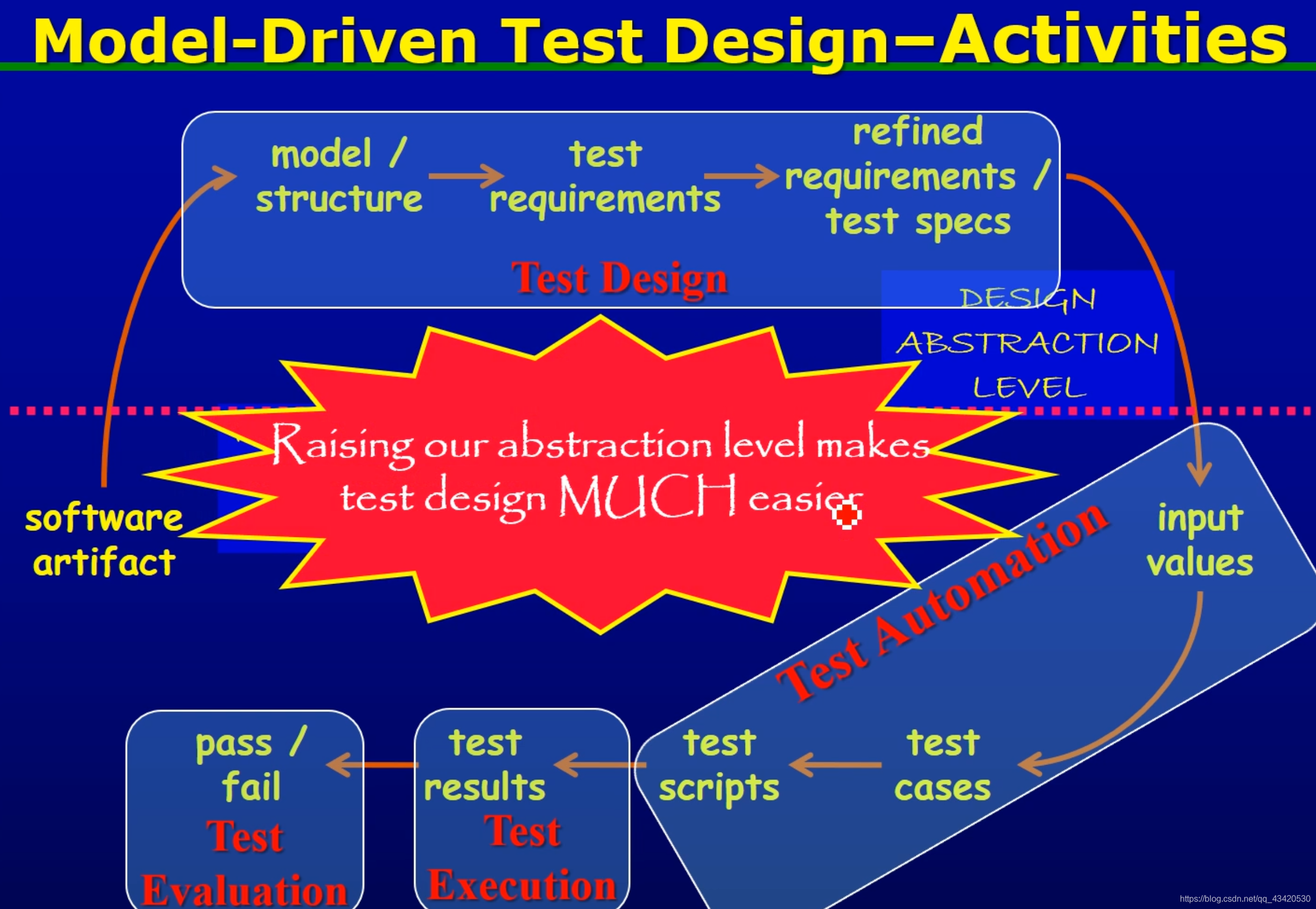
Chapter 3
测试用例的几个部分
- Test case values
满足RIPR中的Infection - Expected results
满足RIPR中的revealability - Prefix values
满足RIPR中的Reachability - Postfix values
满足RIPR中的propagation
Junit
注解
@Runwith
- Suite.class 多个,可以不是一类的测试方法,比如同时运行TestA和TestB(一般的测试只能一次运行一个测试类,而这种方法建造一个公共类,使用注解引入要测试的类即可)

- Parameterized.class 多条值,一个测试方法,比如你就一个测试类,这个测试类里面有一个测试方法,但是你要是测试的值有几百个输入会很麻烦

- 在类的开头写好@注解
- 定义好静态方法,返回值为Collection<Object[]>
- 构造函数,初始化私有变量
- 私有变量的定义
- 创建一个测试方法即可
工作流程
对每一个测试用例,都会重新构造一个这样的测试类,测试类的各种参数(测试用例的输入值,期望值)通过调用这个静态方法得到每一行的数据,借助构造函数进行初始化,之后统一都使用@Test注解的测试方法
Hamcrest
相当于提供了更自然的匹配规则,使用assertThat()

举例
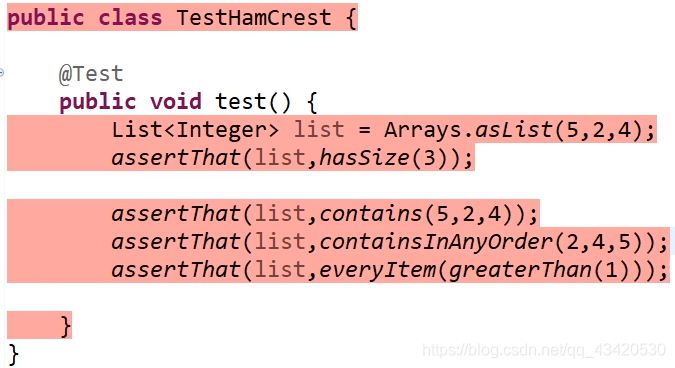
测试覆盖 test coverage
测试覆盖率:覆盖的/总的
如:n个测试用例共四个口味,然而所有糖豆共6个口味,覆盖率为4/6
测试蕴含 criteria with Subsumption
如果C1蕴含C2准则,那么就是说对于每个满足C1测试用例的集合,也满足C2
如:糖豆的口味有6种,颜色有4种,口味准则蕴含了颜色准则
Chapter4 图覆盖 Graph Coverage
基本概念
- 初始节点:predecessor(得有进入的一条边)
- 终止节点:successor
- 路径:node的序列sequence
- 路径长度:单个节点长度为0
- reach(n): subgraph that can be reached from n
- 测试路径:一个路径,从开始节点到终止节点(有些测试路径无法被任何测试用例执行)
- 单入单出路径:
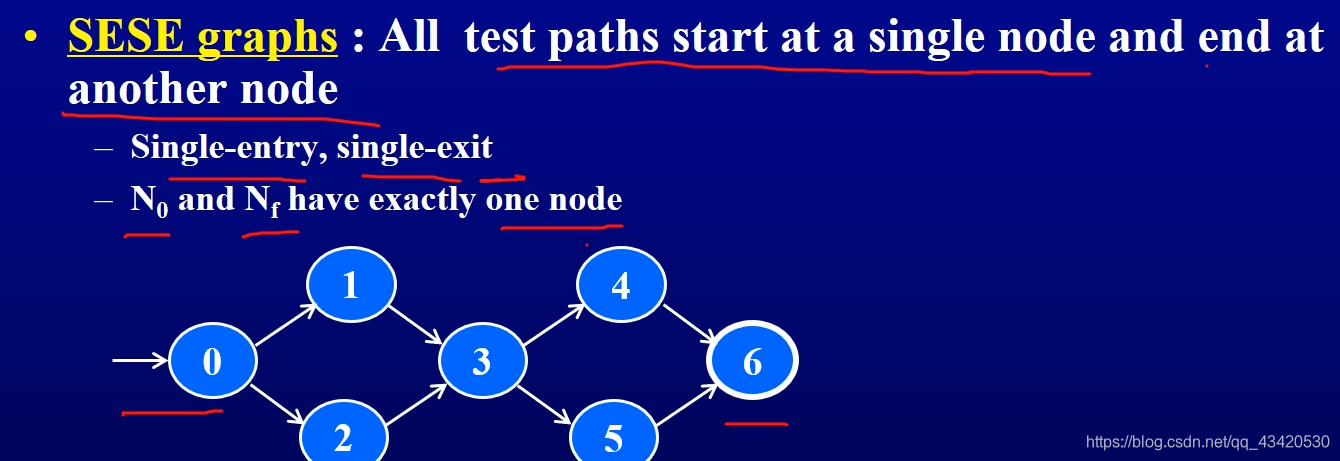
- visit/tour:相对于路径来说的,路径visit node和路径visit edge;如果是路径visit路径肯定不合适,所以应该是路径tour路径,代表路径的一种包含关系

- 语法到达和语义到达

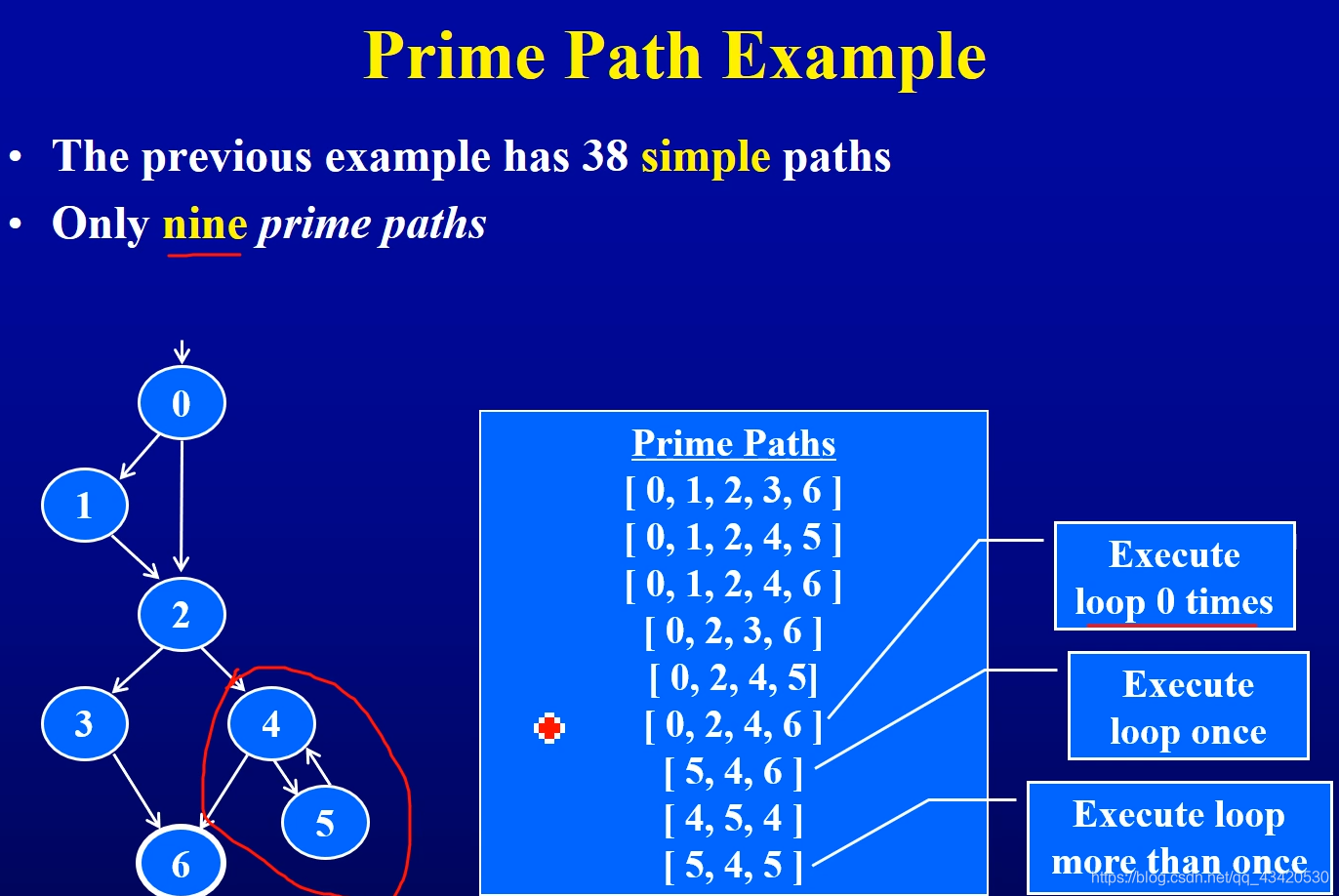
- Simple Path 和 Prime Path
simple path:没有内部的loop,或者本身是一个简单的loop
prime path:这样一个简单路径,满足不是其它简单路径的子路径(最大长度简单路径)
主路径覆盖不蕴含边对覆盖
主路径举例如下
- sidetrips/detours

结构流覆盖标准&数据流覆盖标准
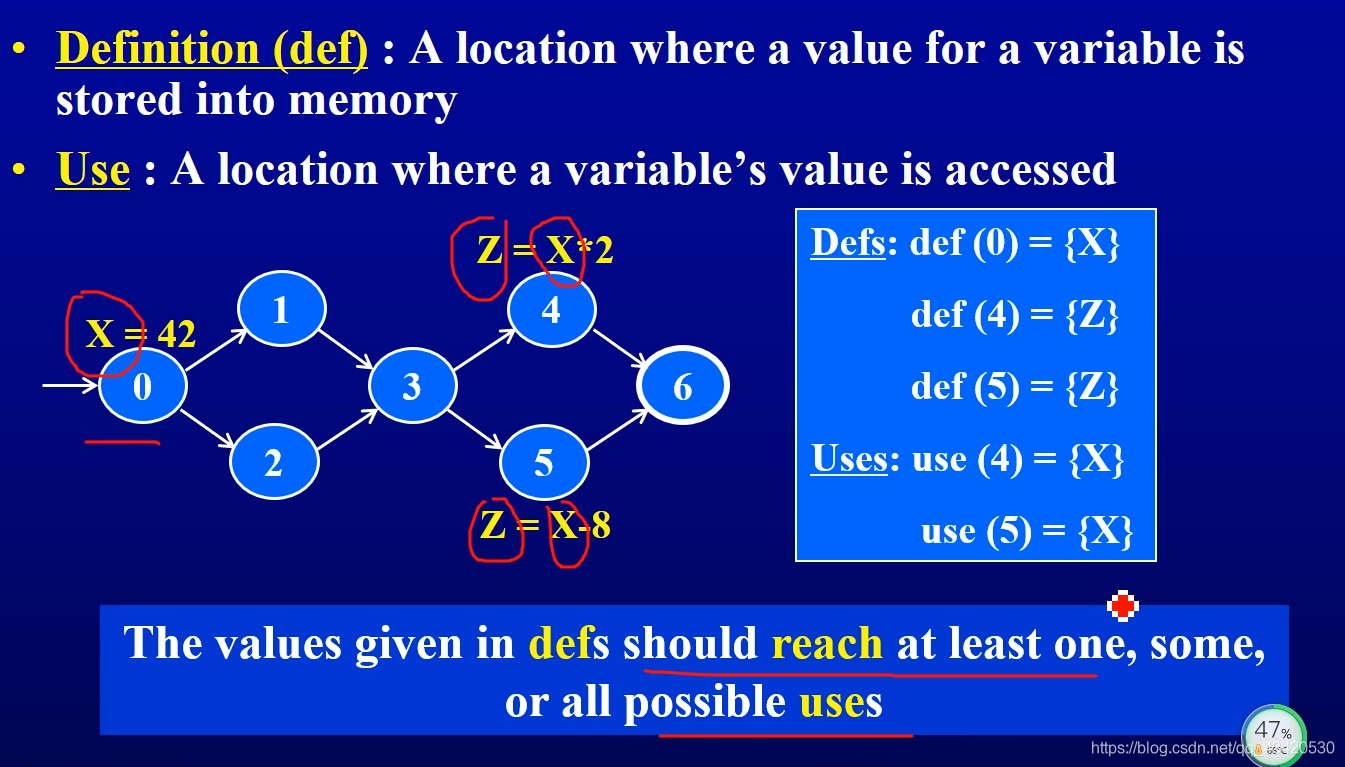
数据流覆盖概念
- Definition
- Use
- 举例

控制流
将代码转换为图结构的时候,每一个节点代表某行代码,有判断条件的时候,边代表判断条件;
有时候循环的判断条件需要加上伪节点(即并不代表某行代码的节点)
Chapter 5 Logic Coverage 逻辑覆盖
基本定义
- predicates/clauses 谓词/子句
谓词predicate:结果为布尔值的表达式,可能包含逻辑操作符号如与或非,有>=,>等
子句clause:不包含逻辑操作符号的谓词
Decision Coverage & Condition Coverage 判定覆盖和条件覆盖
- DC 相当于对整个if、while等圆括号内部的谓词做一个整体的覆盖,只有对错两种结果
- CC 相当于谓词中的子句,无论多少个condition,只需要2个测试用例即可满足100%覆盖
- DC和CC之间并不相互蕴含
MC/DC Coverage

- 条件判定覆盖肯定也是不完全的,举个例子A&B,我只用两个测试用例就能满足C/D C 即A=true,B=true和A=false,B=false显然覆盖并不是那么好
- 条件组合覆盖也就是考虑了所有条件的可能性,测试用例数目指数性增长,下面是测试用例的书写举例
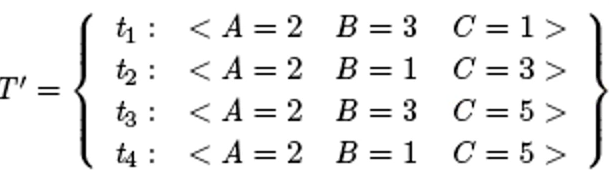
- MC/DC 的核心思想也就是每一个子句的取值都能独立影响最终的结果
Chapter 6 Blackbox Testing
之前讲的都是白盒测试,因为知道具体实现
单输入黑盒测试
Equivalence Class Partition 等价类 ECP
比如一个求绝对值的函数可以划分成负数,0,正数 这3个等价类(还得加上无效值)
举例:上面是有效等价类,下面是无效等价类,参数abc为三角形三条边
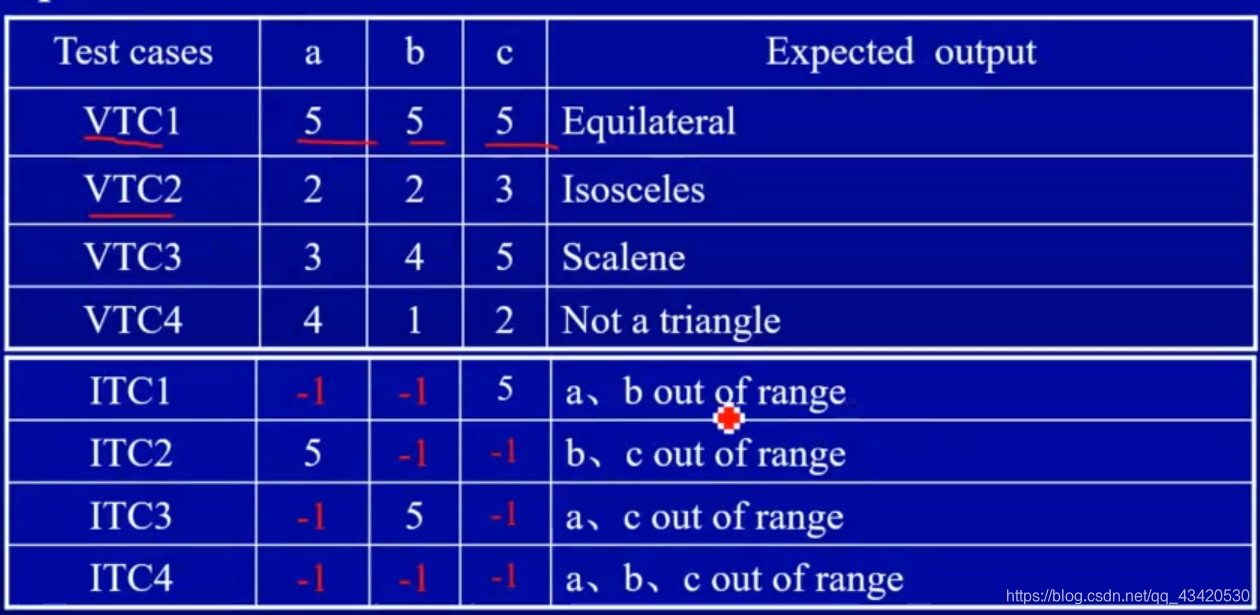
Boundary Value Analysis 边界值
- [X…Y] 需要4个值,X-MIN,X,Y,Y+MIN
- (X…Y) 需要4个值,X,X+MIN,Y-MIN,Y,因为X,Y是开区间,本身可以算作一个最大最小值了,取边界只好往里面取
多输入黑盒测试
决策表DT
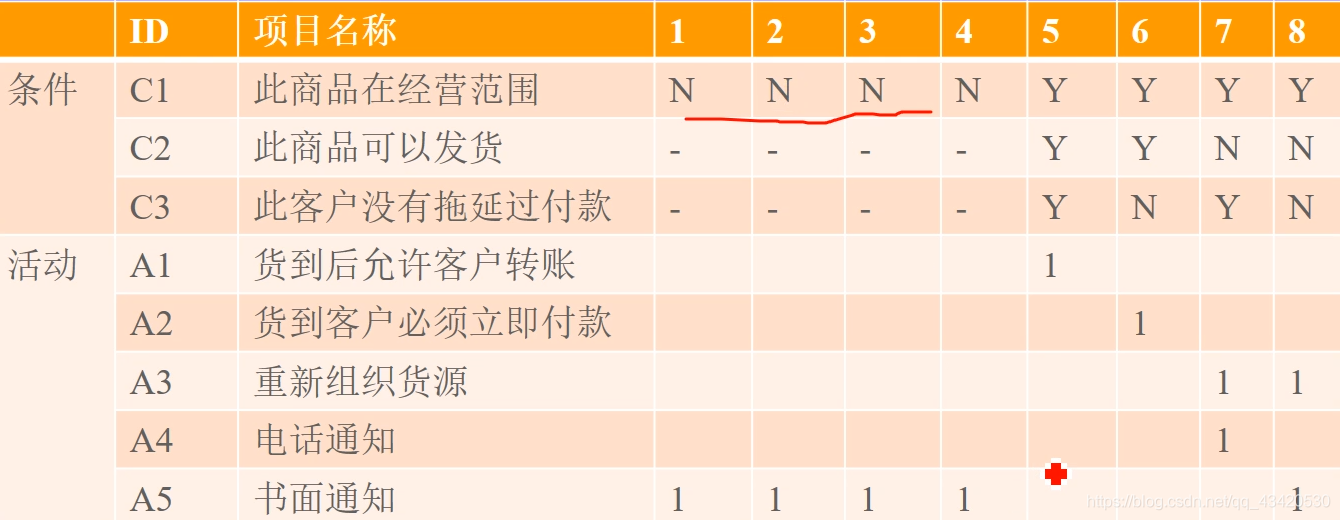
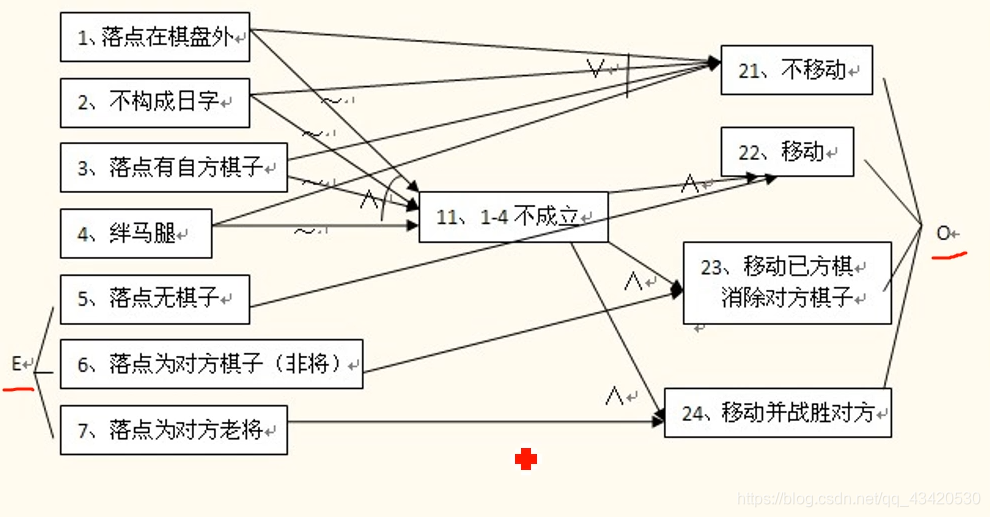
因果图CEG
因果图需要转换成决策表
Pairwise 两两组合
Chapter 8
Chapter 9 性能测试
Performance Testing 性能测试
- 判断系统在特定工作负载下的响应性和稳定性的表现
- 从用户的角度揭示整个程序的响应时间
- 目的是不仅找到bug,而且消除系统的性能瓶颈
Load Testing 负载测试
- 是性能测试的一种,检查系统不断增加对系统的负荷,直到负荷达到其阈值
- 主要目的是,当系统在高负载下运行良好时,监视应用程序的响应时间和持久力
- 只有在指定的测试用例在分配的时间内没有任何错误的情况下,才能算是成功执行负载测试
- Think time taken
Stress Testing 压力测试
- 性能测试的一种,当硬件资源如CPU、内存、磁盘空间等不足时,检查软件的稳定性
- 确定或验证应用程序在超过正常或峰值负载条件时的行为
- Think time ignored
性能评价的三个循环过程
- Measure - determine current performance levels
- Estimate - required/best case performance levels
- Tune system - to meet requirements/best case levels
linux相关命令
- sar -u 查看cpu利用率
- sar -r 查看内存利用率
- sar -d 查看磁盘IO

- sar -n DEV 查看网络流量
Jmeter

Chapter 10 变异测试
变异测试主要用来针对测试集合进行优化的,可以评估测试集的充分性,并且还可以进行测试集的增强
用来测试集充分性adequacy
- 创建变异体集合
- 对于每一个变异体均进行测试,如果有一个测试集中的测试用例使得此变异体无法通过测试,那么杀掉他(因为你既然这么轻易给被测试集区分开了,那么你就没啥意义了)
- 假若最终由k1个变异体活了下来,而原先有k个变异体
- 如果k-k1=0,那么意味着测试集太强了,是充分的
- 如果k-k1>0,使用MS=k1/(k-e)来查看变异的指标,e是等价变异体,因为等价变异体就相当于充数的,所以去掉
用来测试集增强enhancement
- 如果MS=1,说明测试集太菜了,并且菜的离谱,所以需要放弃本次实验,选择其他技术
- 如果MS<1,说明有突变体存活,因此需要设计一个新的测试用例,至少区分一个本体与变异体,如果区分不了重新设计
- 设计好了之后扩展测试集,这样测试集便更有能力杀死变异体了,下面重新计算MS
- 以此类推
- (所谓的等价变异体可以看做和源程序一样的变异体)
用来错误预测error detection
使用变异来进行错误预测:
- 设计好了变异体,并进行了测试
- 发现存活的变异体之后,我们便首先进行等价变异体的排除
- 设计新的测试用例,进行变异体杀害
- 在设计新的测试用例之后,发现原程序中的bug
关于等价变异体Equivalent mutants
- 等价变异体是无法决断的,也无法使用自动化工具
- 经验表明5%的变异体会是等价变异体
- 识别手工变异体通常得人工!非常沮丧
关于多级突变体
变了几处,就叫做n级突变体,比如
second order mutant 可以是这样的
源程序:z=x+y
变异体:x=z+y
上面其实就相当于使用了两次变量替换运算符
实际的实践中,只有1阶突变体会产生,原因为
- 降低测试成本
- 大多数高阶突变体是通过对一阶突变体足够的测试来杀死的
Chapter 12 回归测试
回归测试:
- 程序是不断的迭代开发的,当前版本的程序,进行测试之后,就可以形成一个版本
- 当为程序添加新的功能之后,首先进行新功能的测试,之后还需要测试旧版本的功能是否依旧生效
- 这里需要选择旧版本测试用例集合中的一个子集进行新版本的测试,选择方法有二:test minimization、test prioritization
- 其实为什么进行这样的测试呢,目的是为了保证新添加的代码没有破坏源代码的功能
- 注意我们要去除源代码测试用例中的一些测试用例,因为他们可能不再生效,因此说需要取源测试用例中的一个子集,寻找淘汰的测试用例的任务叫test revalidation(生效)














 1687
1687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









