







1. 概述
提出了一种称之为Generative Latent Optimization(GLO)的方法,与GAN相比,免去了生成对抗训练的策略,取得了类似GAN的效果
2. GAN的介绍
GAN有三个明显的泛化性的迹象:
- 不同图像在latent code空间对应着不同的值,如果把两张图片的值进行插值,那么再经过GAN的生成器,就能生成新的融合两张图像的新的图像,即所谓的:从线性插值到语义插值的转换
- 在latent code空间可以进行线性运算,对应着对图像的各种可能的属性的改变,这意味着我们可以把自然图像的非线性属性转换为线性的运算与统计
- 生成器可以生成新的符合训练数据集分布的图像
虽然GAN的效果令人惊艳,但是GAN的训练却是出了名的难,尽管有很多优化方法被提出,但是与其说是科学,不如说是艺术,文中原话:
While several advances have been made to stabilize the training of GANs (Salimans et al., 2016), this task remains more art than science
并且,该如何评估GAN也是一个棘手的问题,最好的方式反而是直接定性的观察生成器生成的样本质量如何,但是这根本无法给生成器的优化提供什么指导,使得mode dropping问题难以去衡量;关于鉴别器的评估也比较困难,因为本质上来说这是一个视觉上的特征,到监督任务的转化不是很好;GAN的应用也大多局限于图像类的生成任务
总的来说,GAN的成功来源于两个方面:
- 因为用深度卷积网络表示生成器和鉴别器,它的强大的归纳学习能力是关键因素
- 生成对抗训练的策略
本文提出的GLO方法是尽量依赖第一条而去尽量避免第二条,最终取得了和GAN有竞争力的结果
3. GLO
- 首先,对于N张数据集里的图像x,我们用正态分布随机初始化N个d维的latent code,记为z之,后将z和图像x进行配对,没错,就是这样随机配对
- 为了与GAN做对比,以证明本文没有用到GAN的鉴别器与生成对抗训练策略便能取得与GAN相似的效果,作者选择了DCGAN的生成器作为本方法的decoder,也是本方法唯一的网络架构
- 将z丢入decoder,会得到一张图像,这张图像和之前与z配对的图像作loss,反向传播,优化z和decoder,为加深理解,分析如下:
这里与我们传统训练网络的认知不太一样,反而和可微分渲染是有一定的相似之处的。拿pytorch框架举个例子,我们训练一个手写体识别的网络时,输入的图像是tensor,中间的网络结构参数也是tensor,输出的分类结果也是tensor,这些tensor在计算过程中保留了梯度,因此在计算出loss之后能够通过反向传播,计算这整个过程每个tensor的梯度是多少,但是计算出来梯度是不够的,我们还得根据梯度去更新tensor的具体数值,具体该如何更新呢,是得提前将想要更新的tensor放进optimizer里面,然后设置好学习率,每当loss.backward()之后,紧跟着optimizer.step(),这样就算是迭代完一次了,下一次迭代的时候,用的tensor是新的更新完之后的tensor,而到底是哪些tensor被更新了呢?其实只有神经网络的tensor被更新了,输入的图像的tensor因为我们没有放进optimizer里面,所以还是保持原样。
而可微分渲染是做的啥?是将整个渲染管线写成了神经网络的形式,原始的三维物体各种属性是tensor,光照参数是tensor,相机参数是tensor,渲染管线的每一步骤也是tensor,最终渲染出的图像也是tensor,用可微分渲染,做的工作目的便是进行三维重建,比如根据一张随便的二维图像(如人脸一寸照)去得到整个人脸的三维模型,现在有了一个人脸一寸照的tensor了,我直接把人脸一寸照tensor和渲染出的图像的tensor作一个loss,然后进行loss.backward(),这样整个渲染流程的梯度就都有了,那现在问题来了,我到底需要更新哪些tensor呢?我到底需要把哪些tensor放进optimizer里面呢?这里就不是渲染管线的tensor了,而是作为输入的tensor,比如输入的三维物体属性(对于一般的物体重建,一般会初始化成为一个球体,对于人脸重建,就是随机初始化的3DMM系数),光照属性,相机属性等。于是,我们可以发现对于可微分渲染,当整个迭代完成之后,我们其实就可以直接拿到三维重建结果,根本就不存在什么保存网络模型,加载网络模型之类的概念。
在GLO的这一步骤,既不像是传统的训练神经网络一样单纯优化decoder,也不像是可微渲染一样单纯优化latent code,而是把俩都丢进optimizer同时优化
- 损失函数的选择:一般而言直接进行图像像素的l2损失即可,但是考虑到GAN是用了卷积神经网络结构的鉴别器来充当损失函数,因此或许多考虑一下图像的“抽象”层面的特征会更好,因此还引入了Laplacian pyramid loss:
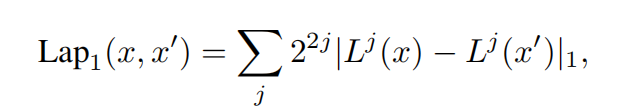
- 在每次的z更新之后,再将其投影回单位球,通过除以 m a x ( ∣ ∣ z ∣ ∣ 2 , 1 ) max(||z||_2,1) max(∣∣z∣∣2,1)来进行实现(猜测:这样,原先在单位球内正态分布的一些点,经过训练之后,逐渐在单位球内满足了某种分布)
- 从宏观上来说,GLO更像是个encoder-less的autoencoder,也像是个discriminator-less的GAN
4. 实验结果
4.1 对latent code性质的探索
以下的GLO的实验结果都表明了这样一个结论:理想的线性化特征其实可能是取决于你的这个生成器的网络结构,而非训练过程(像GAN的生成对抗训练策略一样),因为我用GLO同样取得了类似于GAN的效果:
- 在两张图像的latent code之间进行线性插值实现图像的语义插值:

对于每一行来说,最左边与最右边都是数据集里的图像,二者的latent code进行插值处理得到中间的一系列过渡图像,实现由线性插值到语义插值的转变 - 这种插值并不会坍缩为图像的平均表示,也就是说插值过程中所对应的图像语义时刻是有意义的,而并非是图像的像素层面的简单平均叠加:

选取了三张图像,每一行代表着三张图像彼此之间的插值处理,可以看出每张图像都是个人脸,每张图像都是有语义的 - 对图像的latent code进行线性运算也具有可行性:

比如我在latent code层面上,进行戴墨镜的男人-男人+女人这样一个运算,最终得到的便是右边这张戴墨镜的女人的图像
4.2 对生成新样本的探索
GAN的一大性质便是“无中生有”产生新的数据,因此GLO也在这方面与之做了对比,而具体是如何取样的呢?为了从GLO模型中取样,本文将一个全协方差高斯拟合到训练过程中发现的Z值上,之后从高斯分布中采样,得到z值,再丢入生成器

可以看到VAE比GLO生成的图像更加模糊,或许可以证明一点:VAE学到的latent code的分布是有局限性的,而GLO因为在训练过程中latent code可以自由地根据梯度方向随意优化,因此能够去探索更广阔的空间,因此最终能得到更好的结果

可以看到在卧室的数据集上,GAN的效果是比GLO与VAE要好的,结合文章与个人理解,可能的解释是:因为loss的不同,GAN的loss是个由神经网络组成的鉴别器,而GLO与VAE的loss是简单的损失函数,导致GLO与VAE强迫地学习整个数据集的特征,而GAN的loss因为是个神经网络,是可以进行优化的,所以导致GAN能够去学习特定的某个特征,因此在卧室这种较为复杂的数据集上GAN的效果比较好(但是这样的方式也导致了GAN中的mode dropping问题)















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









