







在我们的目标体系结构中,所有与外部世界的通信都通过适配器进行的。所以,让我们来讨论如何实现一个提供这样一个web界面的适配器
依赖性反转
网络适配器 - 适配器本身以及它与我们的应用核心进行交互的端口
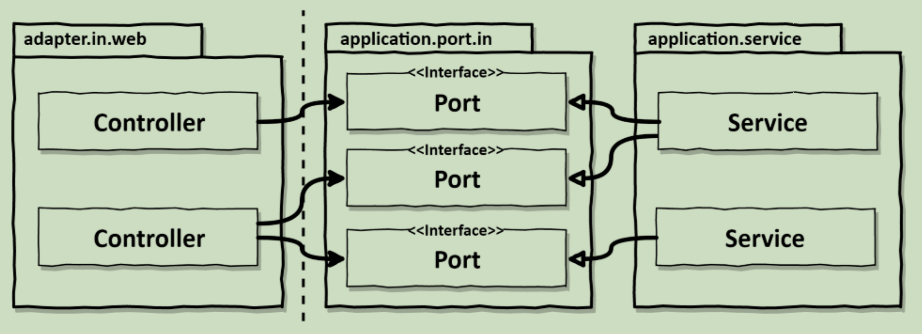
传入的适配器通过专用的传入端口与应用程序层对话,这些端口是由应用程序服务实现的接口。
web适配器是一个“驱动”或“传入”适配器。它从外部接收请求,并将它们转换为对我们的应用程序核心的调用,并告诉它该做什么。控制流从 web适配器中的控制器到应用程序层中的服务。
应用程序层提供了特定的端口,web适配器可以通过这些端口进行通信。这些服务实现了这些端口,web适配器可以调用这些端口。
如果我们仔细观察,就会发现这是依赖性反转原则在发挥作用。由于控制流从左到右,我们也可以让网络适配器直接调用用例,如图14所示。
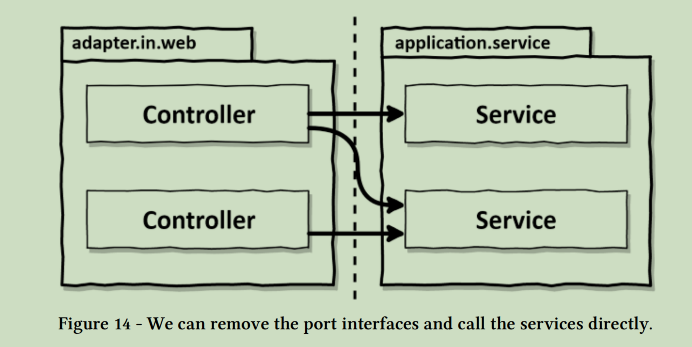
那么,为什么我们要在适配器和用例之间再增加一层间接性?原因是,端口是外部世界可以与我们的应用核心互动的地方。
有了端口,我们就能准确地知道与外界的通信是如何进行的。的通信,这对任何在你的传统代码库上工作的维护工程师来说都是一个有价值的信息。
然而,仍然存在一个问题,它与高度交互式的应用程序有关。想象一下,有一个应用程序通过web套接字向用户的浏览器发送实时数据。应用程序核心如何将这些实时数据发送到web适配器,然后再将其发送到用户的浏览器?
对于这个场景,我们肯定需要一个端口。这个端口必须由web适配器实现,并由应用程序核心调用,如图15所示。
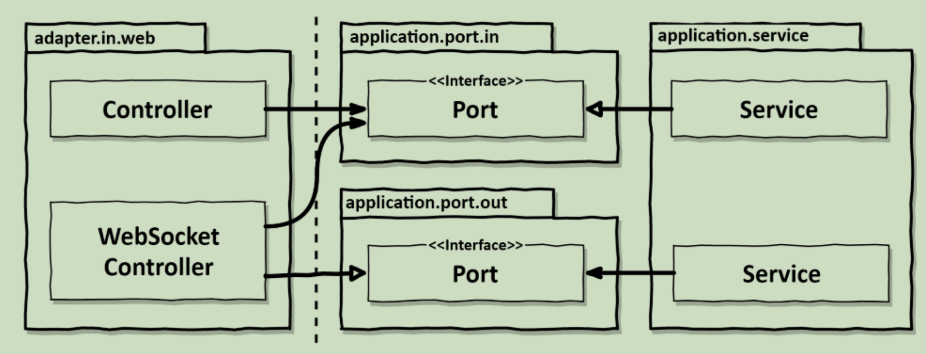
如果应用程序必须主动通知web适配器,我们需要通过一个传出端口来保持正确的方向
从技术上讲,这将是一个传出端口,并使web适配器成为一个传入和传出适配器。但是没有理由说同一个适配器不能同时存在。
在本章的其余部分中,我们将假设web适配器仅是一个传入的适配器,因为这是最常见的情况。
Web适配器的职责
网络适配器到底是做什么的?假设我们想为我们的BuckPal应用程序提供一个REST API。web适配器的职责从哪里开始,它们从哪里结束?
一个web适配器通常会做以下事情:
-
Map HTTP request to Java objects 将HTTP请求映射到Java对象
-
Perform authorization checks 执行授权检查
-
Validate input 验证输入
-
Map input to the input model of the use case 将输入映射到用例的输入模型
-
Call the use case 调用用例
-
Map output of the use case back to HTTP 将用例的输出映射回HTTP
-
Return HTTP response 返回HTTP响应
首先,web适配器必须侦听符合特定条件的HTTP请求,如特定的URL路径、HTTP方法和内容类型。然后,匹配的HTTP请求的参数和内容必须被反序列化为我们可以处理的对象。
通常,web适配器会进行身份验证和授权检查,如果失败,则返回一个错误。
然后可以验证传入对象的状态。但我们不是已经讨论过输入验证是用例的输入模型的责任吗?是的,用例的输入模型应该只允许输入在用例的上下文中是有效的。但在这里,我们谈论的是网络适配器的输入模型。它可能有一个完全不同的结构和语义。它的结构和语义可能与用例的输入模型完全不同,所以我们可能必须执行不同的验证。
我不提倡在web适配器中实现与我们在用例的输入模型中所做的相同的验证。相反,我们应该验证我们是否可以将web适配器的输入模型转换为用例的输入模型。任何阻止我们进行这种转化,就是一个验证错误。
这就让我们想到了web适配器的下一个责任:用转换后的输入模型调用某个用例。然后适配器获取用例的输出并将其序列化为HTTP响应,该响应发送给调用者。
如果在途中发生了任何问题,并且抛出了异常,web适配器必须将错误转换为发送回调用者的消息。
这是我们的web适配器所要承担的很多责任。但是,它也有很多应用程序层不应该关心的责任。任何与HTTP有关的东西都不能泄漏到应用层。如果应用核心知道我们是在处理 HTTP,我们基本上就失去了从其他不使用HTTP的输入适配器执行同样的域逻辑的选择。其他不使用HTTP的传入适配器执行相同的域逻辑。在一个好的架构中,我们希望保持选项 开放。
请注意,如果我们从domain和 application layers开始开发,而不是从网络层开始,那么网络适配器和应用层之间的界限就会自然而然地出现。而不是从Web层开始。如果我们首先实现用例,而不考虑任何特定的传入适配器,我们就不会试图模糊边界
分割Controllers
在大多数web框架中——比如Java世界中的SpringMVC——我们创建了控制器类来执行我们上面讨论过的职责。那么,我们是否构建一个单一的控制器来回答针对应用程序的所有请求呢?我们不必这么做。一个web适配器当然可以由多个类组成。
然而,我们应该小心地将这些类放入相同的包层次结构中,以将它们标记为属于一起,正如在第3章“组织代码”中所讨论的那样。那么,我们要建多少个控制器?我说,我们应该宁可建太多也不要建太少。我们应该确保每个控制器实现的网络适配器的范围尽可能的窄、尽可能少地与其他控制器共享。
让我们来看看在我们的BuckPal应用程序中的一个帐户实体上的操作。 一个流行的方法是创建一个单一的AccountController,接受所有与账户相关的操作请求。一个提供REST API的Spring控制器可能看起来像下面的代码片段。
同样的论点也适用于测试代码。如果控制器本身有大量的代码,就会有大量的 测试代码。通常,测试代码甚至比生产性代码更难掌握,因为它往往是 更加抽象。我们也想让某段生产代码的测试很容易 找到,这在小类中比较容易。
在上面的代码例子中,许多操作都共享AccountResource模型 类。它作为一个桶,用于存放任何操作中需要的一切。AccountResource 可能有一个id字段。这在创建操作中是不需要的,而且在这里可能会造成混乱而不是帮助。想象一下,一个账户与用户对象有一对多的关系。当我们创建或更新一本书时,我们是否包括这些用户对象?这些用户是否会被 列表操作返回吗?这只是一个简单的例子,但在任何超过游戏规模的项目中,我们都会在某个时候问这些 问题。
因此,我提倡为每个操作创建一个单独的控制器,可能是在一个单独的包中。此外,我们应该将方法和类命名为尽可能接近我们的用例:
另外,每个控制器可以有自己的模型,比如CreateAccountResource或UpdateAccountResource。或者使用基元作为输入,就像上面的例子。这些专门的模型类甚至可以是控制器包的私有类,这样它们就不会意外地被其他地方重复使用。 控制器仍然可以共享模型,但是使用来自另一个包的共享类会让我们更多的考虑 也许我们会发现,我们不需要一半的字段,毕竟我们要创建自己的字段。
另外,我们应该认真思考控制器和服务的名称。例如,与其说是CreateAccount, RegisterAccount不是一个更好的名字吗?在我们的BuckPal应用程序中,创建一个账户的唯一方法就是让用户注册它。所以我们在类名中使用 "register "这个词来更好地 传达它们的意思。
当然,在有些情况下,常见的创建…、更新…和删除…足以描述一个用例,但在实际使用之前,我们可能要三思而后行。它们。
这种切分方式的另一个好处是,它使不同操作的并行工作变得轻而易举。如果两个开发人员在不同的操作上工作,我们就不会有合并冲突。
这对我构建可维护的软件有什么帮助?
当构建一个应用程序的web适配器时,我们应该记住,我们正在构建一个适配器,将HTTP翻译成我们应用程序的用例的方法调用,并将结果结果转回HTTP,而不做任何domain逻辑。
另一方面,应用程序层不应该做HTTP,所以我们应该确保不泄露HTTP的详细信息。这使得web适配器在需要时可以被另一个适配器替换。
在对web控制器进行切片时,我们不应该害怕构建许多不共享模型的小类。它们更容易掌握,容易测试和支持并行工作。最初设置这种细粒度控制器需要更多的工作,但在维护期间会得到回报。
一句话就是说:将控制类尽可能的细分,这样有助于以后的维护,并且大家并行开发的时候不会冲突。















 2539
2539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









