






需求背景: 帮 为知识付费的 热心网友 处理数据
1、原始数据
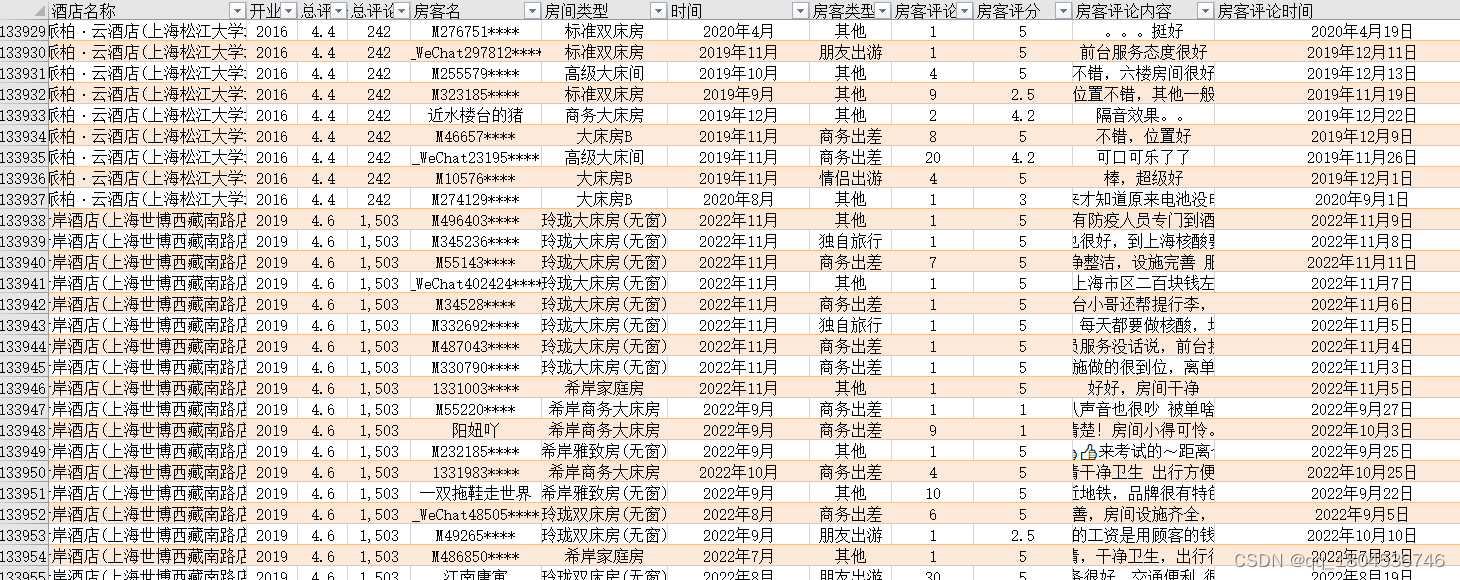
2、需求
热心网友需求根据原始数据Excel做数据分析,故有对每个酒店的以下需求:
demands:
1. 截止T时间段的最新10条评论的房客平均评分
2. 截止T时间段的累计房客平均评分
3. 酒店近期评分差(1-2)
4. 截止到T时间段的最新10条评论文本
5. 截止到T时间段的评论数量
tips:
1. 时间T从2020年1月1日开始,每月每季度
2. 季度的评论数量为当前季度数量非截止到当前时间
3. 10条最新评论文本需拆分为多个单元格数据
3、数据处理
- 技术选型:python pandas模块读写excel,灵活方便
- 需求分析:
读取数据然后按时间排序即可解决大半需求
读取酒店名称、评论时间、评论文本、评分四列数据即可
pandas读取excel文件:
df = DataFrame(pd.read_excel("demand.xlsx", usecols='J:L,A', index_col='酒店名称'))
发现文件读取速度过慢,优化:
df = DataFrame(pd.read_excel("demand.xlsx", usecols='J:L,A', index_col='酒店名称'))
df.to_csv("demand.csv")
df = DataFrame(pd.read_csv('demand.csv'))
读取日期排序,先打印读取的日期:
dates = df.房客评论时间
print(dates)
然而结果有点不尽人意:
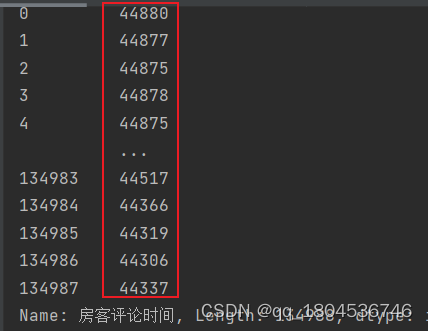
很好,愉快的百度一下:
参考文章: link
没有使用系统内置的日期单元格格式,自定义格式没有对负数格式进行定义,pandas读取时无法识别出是日期格式,而是读取出单元格实际存储的数值。
那么我们已经知道了缘由,尝试解决方案,根据需求:
- 把读取到的数字变更为正常日期,方便把结果写入excel
- 把正常日期改为读取到的数字类型,方便参与运算
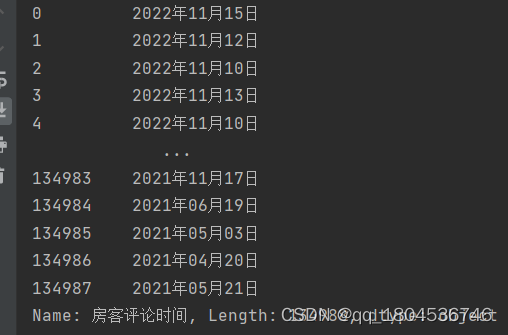
数字转日期:
baseTime = pd.to_datetime("1899/12/30")
df.房客评论时间 = df.房客评论时间.apply(lambda x: baseTime + Day(x))
df.房客评论时间 = df.房客评论时间.dt.strftime('%Y年%m月%d日')
print(df.房客评论时间)
日期转数字:
def get_days(a, b, c):
date1 = date(a, b, c)
date2 = date(1899, 12, 30)
return (date1 - date2).days
print(get_days(2022, 12, 2)) # 44897
我们直接利用读取的日期数字作排序做数据处理,最后再把日期数字转为日期即可
后来发现直接此需求其实输出表头给定字符串就可以了
表头T根据需求应是2020年1月1日到当前月份1日,季度同理。
我们把表头时间转为日期数字参与比较运算:
def get_days(a, b, c):
date1 = date(a, b, c)
date2 = date(1899, 12, 30)
return (date1 - date2).days
def get_dates():
ds = []
today = datetime.datetime.today()
this_year = today.year
this_month = today.month
for y in range(2020, this_year + 1):
for m in range(1, 13):
if y == this_year and m > this_month:
continue
ds.append(get_days(y, m, 1))
month_comment.append(get_days(y, m, 1))
count_month.append(0)
date_header.append(f"{y}年{m}月1日")
ms = [4, 7, 10, 1]
quarter_comment.append(month_comment[0])
for y in range(2020, this_year + 1):
quarter = 0
for m in ms:
if m == 1:
y += 1
if (y == this_year and m > this_month) or y > this_year:
continue
ds.append(get_days(y, m, 1))
quarter_comment.append(get_days(y, m, 1))
count_quarter.append(0)
quarter += 1
if quarter == 4:
y -= 1
date_header.append(f"{y}年Q{quarter}季度")
return ds
现在已经有了T时间的日期数字,我们需要找出离T时间的最近10条评论。
很自然想到,拿到每个酒店的评论列表,按照评论时间升序。
这样我们只需要找到T时间在日期列表的偏移量,偏移量左边的10位即为截止T时间最新评论。
利用二分法算偏移量:
def get_offset(da, vs):
start = 0
end = vs.__len__() - 1
while start <= end:
m = math.floor((start + end) / 2)
v = vs[m][3]
if v == da:
return m
if v < da:
start = m + 1
if v > da:
end = m - 1
return start
到这里我们已经找到了截止T时间的最新10条数据,那么评分的要求都完成了。
这里评论文本按照评分的做法是,酒店T时间的文本为一个列表。
我们需要拆分开来,注意赋空值:
for hotel in hotels:
dd = df.loc[df['酒店名称'] == hotel]
# dd = df.loc[df['酒店名称'] == '美豪丽致酒店(上海嘉定新城中心店)']
vs = dd.values
vs = sorted(vs, key=lambda x: x[3])
form1 = [hotel]
form2 = [hotel]
form3 = [hotel]
form4 = []
for i in range(10):
form4.append([hotel])
form5 = [hotel]
c_month = count_month.copy()
c_quarter = count_quarter.copy()
for the_date in dates:
offset = get_offset(the_date, vs)
total_scores = []
last_scores = []
reviews = []
if offset < 1:
form1.append("")
form2.append("")
form3.append("")
for i in range(form4.__len__()):
form4[i].append("")
# form4.append("")
continue
for i in range(0, offset):
total_scores.append(vs[i][1])
for i in range(max([offset - 10, 0]), offset):
last_scores.append(vs[i][1])
reviews.append(vs[i][2])
total_average = np.around(np.mean(total_scores), 3)
last_average = np.around(np.mean(last_scores), 3)
difference_average = last_average - total_average
form1.append(last_average)
form2.append(total_average)
form3.append(difference_average)
# form4.append(";".join(reviews))
for i in range(reviews.__len__()):
form4[i].append(reviews[i])
form_first.append(form1)
form_second.append(form2)
form_third.append(form3)
# form_fourth.append(form4)
form_fourth.extend(form4)
那么到这里就只剩下评论数量了。
表头T作为时间列表,遍历每个酒店评论列表数据,判断其在哪个T时间段,其T评论数量++
因为表头T列表我们可以按时间排序,即可用下标代替T,一维数组可以满足要求:
def get_comment_count(the_date, c_month, c_quarter):
if the_date < month_comment[0] or the_date > month_comment[-1]:
return
for i in range(1, month_comment.__len__()):
if month_comment[i] > the_date >= month_comment[i - 1]:
c_month[i - 1] += 1
for i in range(1, quarter_comment.__len__()):
if quarter_comment[i] > the_date >= quarter_comment[i - 1]:
c_quarter[i - 1] += 1
for hotel in hotels:
dd = df.loc[df['酒店名称'] == hotel]
# dd = df.loc[df['酒店名称'] == '美豪丽致酒店(上海嘉定新城中心店)']
vs = dd.values
vs = sorted(vs, key=lambda x: x[3])
form5 = [hotel]
c_month = count_month.copy()
c_quarter = count_quarter.copy()
for v in vs:
get_comment_count(v[3], c_month, c_quarter)
form5.extend(c_month)
form5.extend(c_quarter)
很好,现在我们已经完成了需求了,完结撒花,周末愉快。
ps:
这是一个我做之前以为很简单,实际上有点操作难度,并是工作时间用来摸鱼很nice的需求。
近期由于工作原因,最近在学nebula graph,随着深入一点学习,慢慢的...
我开始认识了更多技术的新名词,我真的很开心呢~
点开一个文档,相关技术很多没学(听)过,还好有些贴心的附上了英文文档链接。逐步迈向绝望之谷,真的会谢啊
学习(money)使我快乐
过去虽不沉迷,当下仍旧迷惘。我相信我可以,早日走上开悟之坡,加油!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









