









前言:
某机型每次出报告的时候都需要按照指定格式发给运营商和客户,一开始数量不多的时候,随便写了两三个脚本来处理,也还能应付过来,后续报告数量增多,PASL增加这些因素都对出报告造成了不小的困扰。
且后续没有办法很好的把转报告的工作转出去,遂编写了一个python脚本输入内容为工厂给到的xlsx文件。
可以自动完成:
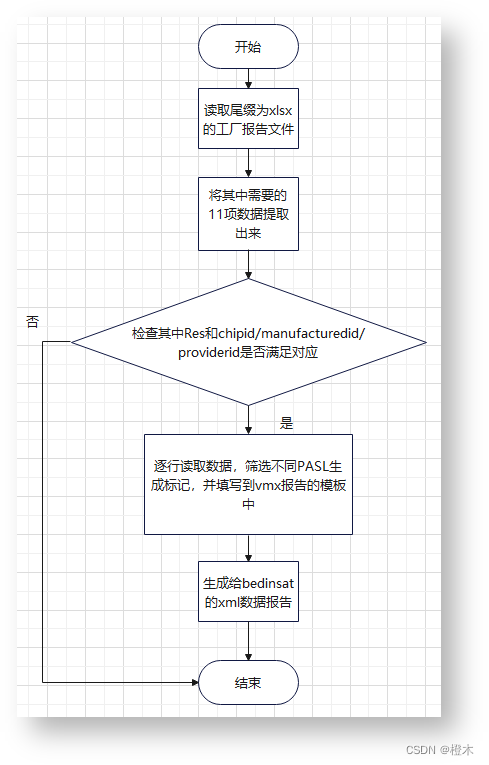
①检查工厂给到的文件数据准确性
②将不同PASL的数据进行分离,并将多余数据剔除,只填需要的数据到vmx的报告模板(日期、PASL编号、必要生成报告中机顶盒数据)
③将bedinsat需要的xml格式的文件所需要的数据title重新命名然后生成xml格式文件
流程图:
代码:
#!/usr/bin/python
#CSVtoXML.py
#encoding:utf-8
import csv, os
from xml.dom.minidom import Document
from shutil import copyfile
from xml.dom.minidom import Document
import numpy as np
import pandas as pd
import openpyxl
from openpyxl import load_workbook
from datetime import datetime
import numpy as np
import time
list_name = ["ChipId","OperatorName","ManfacturerId","ProviderId","CardlessSmartcardNumber","Res","ModelNumber","SerialNumber","CAID","PIN","case_code"]
to_bedinsat_list = ["CAID","CardlessSmartcardNumber","SerialNumber","case_code"]
modify_list = ["CAID","SCUA","FinalProdSN","case_code"]
vmx_template_name = "./template/xlsx_to_vmx.xlsx"
#prfixFile = "creature_data"
def check_NSC_Res(NSC_ID,Res):
flag = True
i = 0
for i in range(10):
if(NSC_ID[i+1] != Res[16*3 + i*2 + 1]):
flag = False
#print(flag)
return flag
def check_data(Chipid,NSC_ID,Res):
if(Chipid in Res and check_NSC_Res(NSC_ID,Res)):
return True
else:
return False
def createXMLFile(filePrefix):
csvFile = open(filePrefix + '.csv')
headLine = csvFile.readline()
typeList = headLine.split(',')
doc = Document()
dataRoot = doc.createElement('ProdLogs')
dataRoot.setAttribute('xmlns:xsi', "http://www.w3.org/2001/XMLSchema-instance")
dataRoot.setAttribute('xsi:noNamespaceSchemaLocation', filePrefix + '.xsd')
doc.appendChild(dataRoot)
dataHeader = doc.createElement('Header')
dataHeader.setAttribute('STBManufacturerName', 'NONE1')
dataHeader.setAttribute('STBTechnicalModelName', 'NONE2')
dataHeader.setAttribute('STBDistributorName', 'NONE3')
dataHeader.setAttribute('STBDistributorModelName', 'NONE4')
dataHeader.setAttribute('FormatVersion', '01.00.00')
dataRoot.appendChild(dataHeader)
dataLog = doc.createElement('Logs')
dataLog.setAttribute('CreationDate', time.strftime('%Y/%m/%d %H:%M', time.localtime()))
total = 0
csvReader = csv.reader(csvFile)
for line in csvReader:
if line[1] in (None, "", " "):
continue
total += 1
dataElt = doc.createElement('LogRecord')
for i in range(len(typeList)):
typeList[i] = typeList[i].strip("\n")
if typeList[i] == ("SCUA"):
line[i] = line[i].replace(" ", "")
dataElt.setAttribute(typeList[i], line[i])
dataLog.appendChild(dataElt)
dataLog.setAttribute('NumberOfRecords', str(total))
dataRoot.appendChild(dataLog)
xmlFile = open(filePrefix + '.xml', 'w')
xmlFile.write(doc.toprettyxml(indent='\t'))
xmlFile.close()
#os.remove(filePrefix + '.csv')
def modify_csv_title_name(filename):
print("modify title name")
data = pd.read_csv(filename + '.csv')
try:
data.rename(columns={"CardlessSmartcardNumber": "SCUA"}, inplace=True)
data.rename(columns={"SerialNumber" : "FinalProdSN"},inplace=True)
data = pd.DataFrame(data,columns=modify_list)
data.to_csv(filename + '.csv',index=False)
createXMLFile(filename)
except:
print("modify title name failed")
def checkXMLFile(filePrefix):
print("check the file:" + filePrefix)
csvFile = open(filePrefix+'.csv')
headLine = csvFile.readline()
typeList = headLine.split(',')
doc = Document()
dataRoot = doc.createElement('ProdLogs')
dataRoot.setAttribute('xmlns:xsi', "http://www.w3.org/2001/XMLSchema-instance")
dataRoot.setAttribute('xsi:noNamespaceSchemaLocation', filePrefix+'.xsd')
doc.appendChild(dataRoot)
dataHeader = doc.createElement('Header')
dataHeader.setAttribute('STBManufacturerName','Bedinsat')
dataHeader.setAttribute('FormatVersion','01.00.00')
dataRoot.appendChild(dataHeader)
dataLog = doc.createElement('Logs')
dataLog.setAttribute('CreationDate','2021/03/30 10:51')
total = 0
csvReader = csv.reader(csvFile)
#print(len(csvReader))
for line in csvReader:
#print(line[0])
if line[0] in (None,""," "):
continue
#print line
#total+=1
dataElt = doc.createElement('LogRecord')
for i in range(len(typeList)):
typeList[i] = typeList[i].strip("\n")
#print(typeList[i])
if typeList[i] == ("ChipId"):
#line[i] = line[i].replace(" ","")
chipid = line[i]
#print(line[i])
if typeList[i] == ("CardlessSmartcardNumber"):
line[i] = line[i].replace(" ","")
NSC_ID = line[i]
#print(line[i])
if typeList[i] == ("Res"):
res = line[i]
#print(line[i])
dataElt.setAttribute(typeList[i], line[i])
if(check_data(chipid,NSC_ID,res) == False):
total+=1
print("not ok")
dataLog.appendChild(dataElt)
dataLog.setAttribute('NumberOfRecords',str(total))
dataRoot.appendChild(dataLog)
xmlFile = open(filePrefix+'_check_report.xml','w')
xmlFile.write(doc.toprettyxml(indent = '\t'))
xmlFile.close()
if total == 0:
return True;
else:
return False;
def change_csv_to_vmx_bedinsat_template(filename):
vmx_out_put_name = filename + "_vmx_template.xlsx"
try:
copyfile(vmx_template_name,vmx_out_put_name)
except:
print("copy template error")
wb_40 = openpyxl.load_workbook(vmx_out_put_name)
sheet_introduction_40 = wb_40['Introduction']
sheet_DATA_40 = wb_40['DATA']
ce_ManufacturerId_40 = sheet_introduction_40.cell(6,2)
ce_Date_40 = sheet_introduction_40.cell(8,2)
ce_operator_name_40 = sheet_introduction_40.cell(5,2)
ce_Model_number_40 = sheet_introduction_40.cell(7,2)
ce_ManufacturerId_40.value = "0000000000000001"
ce_Date_40.value = datetime.now().strftime("%m-%d-%Y")
#########################################################
wb_169 = openpyxl.load_workbook(vmx_out_put_name)
sheet_introduction_169 = wb_169['Introduction']
sheet_DATA_169 = wb_169['DATA']
ce_ManufacturerId_169 = sheet_introduction_169.cell(6,2)
ce_Date_169 = sheet_introduction_169.cell(8,2)
ce_operator_name_169 = sheet_introduction_169.cell(5,2)
ce_Model_number_169 = sheet_introduction_169.cell(7,2)
ce_ManufacturerId_169.value = "0000000000000002"
ce_Date_169.value = datetime.now().strftime("%m-%d-%Y")
count_of_40 = 0
count_of_169 = 0
with open(filename+'.csv', 'r') as f:
reader = csv.reader(f)
result = list(reader)
length = len(result)
for i in range(length):
if i == 0:
continue#skip the title
if "40" in result[i][2]:
count_of_40 += 1
sheet_DATA_40.cell(i + 1, 1).value = result[i][0]
sheet_DATA_40.cell(i + 1, 2).value = ce_operator_name_40.value#result[i][1]#operator name
sheet_DATA_40.cell(i + 1, 3).value = result[i][2]
sheet_DATA_40.cell(i + 1, 4).value = result[i][3]
sheet_DATA_40.cell(i + 1, 5).value = result[i][4]
sheet_DATA_40.cell(i + 1, 6).value = result[i][5]
sheet_DATA_40.cell(i + 1, 9).value = ce_Model_number_40.value#model_number
sheet_DATA_40.cell(i + 1, 10).value = result[i][7]
elif "169" in result[i][2]:
count_of_169 += 1
sheet_DATA_169.cell(i + 1, 1).value = result[i][0]
sheet_DATA_169.cell(i + 1, 2).value = ce_operator_name_169.value # result[i][1]#operator name
sheet_DATA_169.cell(i + 1, 3).value = result[i][2]
sheet_DATA_169.cell(i + 1, 4).value = result[i][3]
sheet_DATA_169.cell(i + 1, 5).value = result[i][4]
sheet_DATA_169.cell(i + 1, 6).value = result[i][5]
sheet_DATA_169.cell(i + 1, 9).value = ce_Model_number_169.value # model_number
sheet_DATA_169.cell(i + 1, 10).value = result[i][7]
if count_of_40 != 0:
wb_40.save(filename + "_40_template_%d.xlsx"%(count_of_40))
if count_of_169 != 0:
wb_169.save(filename + "_169_template_%d.xlsx"%(count_of_169))
return True
def xlsx_to_csv_pd(xls_file):
if xls_file == "xlsx_to_vmx":
return;
try:
xls_file+='.xlsx'
print(xls_file)
data_xls = pd.read_excel(xls_file,index_col=0,usecols=list_name)
data_to_bedinsat = pd.read_excel(xls_file,index_col=0,usecols=to_bedinsat_list)
csv_file = xls_file.split('.')[0]
data_xls.to_csv(csv_file + '.csv', encoding='utf-8')
data_to_bedinsat.to_csv(csv_file + "_to_bed.csv",encoding = 'utf-8')
if checkXMLFile(csv_file):
change_csv_to_vmx_bedinsat_template(csv_file)
modify_csv_title_name(csv_file + "_to_bed")
else:
print("check report fail\n")
except:
print(xls_file," err")
def main():
#change_csv_to_vmx_bedinsat_template("Production_Report_BS9900S_TV_Globo_20220901_1")
for root, dirs, files in os.walk(os.getcwd()):
for fname in files:
index = fname.find('.xlsx')
if index > 0:
#print index, fname[:index]
xlsx_to_csv_pd(fname[:index])
print("Transform " + fname + " OK!")
if __name__ == '__main__':
main()
input("Game Over!")
















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









