






 本文概述了对推荐系统实践的学习进展,包括改进用户相似度计算方法,引入物品相似度的归一化处理,以及深入理解传统模型如协同过滤、矩阵分解和逻辑回归。通过实例展示了如何通过惩罚热门物品影响,优化用户兴趣相似度评估,以及如何利用多种模型解决信息过载和数据稀疏问题。
本文概述了对推荐系统实践的学习进展,包括改进用户相似度计算方法,引入物品相似度的归一化处理,以及深入理解传统模型如协同过滤、矩阵分解和逻辑回归。通过实例展示了如何通过惩罚热门物品影响,优化用户兴趣相似度评估,以及如何利用多种模型解决信息过载和数据稀疏问题。
本周学习内容汇报
学习内容总览:
- 学习项亮推荐系统实践第一章第二章内容。
- 总结王喆深度学习推荐系统第二章 传统推荐模型相关知识
- 对Python实现的基于用户的CF,用户相似度计算的改进
- 对于Python实现的基于item的CF,引入物品相似度的归一化
详细学习内容总结:
- 学习项亮推荐系统实践第一章第二章内容
主要科普了到底什么是推荐系统,以及什么是一个好的推荐系统。
其次向我们介绍了一些日常生活中常见的推荐系统。
推荐系统设计出来之后,怎么评判“好”呢,于是介绍了推荐系统的评测指标及维度。
1.1 在信息过载的背景下,人们有三种方式进行信息查找:
1 按照目录进行分类 2. 搜索引擎 3. 推荐系统
但是1在信息越来越多的现在也变得不再使用,2需要用户有明确需求的时候进行查找,3是当用户没有明确需求时所使用的工具,所以2和3是相辅相成的。
推荐系统不需要用户提供明确的需求,而是通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息。
名词:【长尾效应】热门的东西越来越热门,冷门的东西越来越冷门。
为什么会这样呢? 当信息很多的时候,我们无法判断物品的好坏,于是我们为了省事可能会更倾向于选择热门或者是大多数人认为“好”的东西。那么如果有了推荐系统,会根据你自己的喜好对你进行推荐,推荐的东西是适合于自己的,就不用只能挑选热门的东西啦,就可以一定程度的避免长尾效应,使得冷门商品也可以增加销售量点击率等等。
1.2 How to 推荐?
1 社会化推荐(问好友)
2 基于内容的推荐(根据用户自己的历史观影记录进行推荐)
3 基于协同过滤的推荐(根据找与这个用户兴趣相似的用户所观看的历史观影进行推荐)。
推荐系统就是自动联系用户和物品的一种工具,它能够在信息过载的环境中帮助用户发现令他们感兴趣的信息,也能将信息推送给对它们感兴趣的用户。
好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣,但却不那么容易发现的东西
- 总结王喆深度学习推荐系统第二章 传统推荐模型相关知识
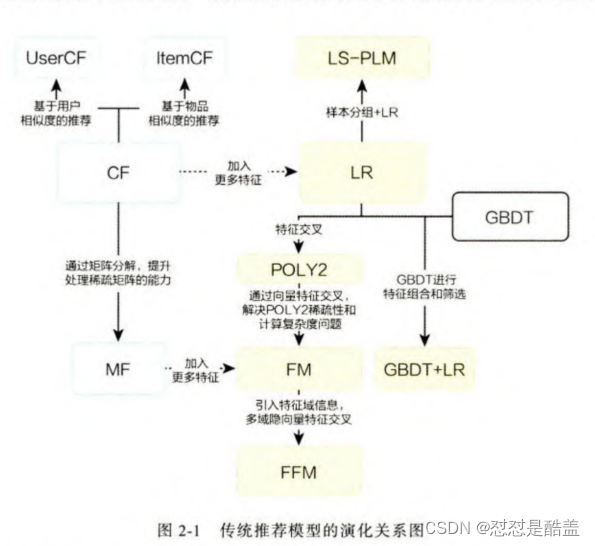
2.1 协同过滤
《Amazon.com Recommenders Item-to-Item Collaborative Filtering》
“协同过滤”就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。下面介绍基于用户的UserCF:
生成共现矩阵。假设有m个用户,n个物品,每个用户会对n个物品中的一个或者几个进行评分,未评分的物品分值就用问号表示,则所有m个用户对物品的评分可形成一个m ∗ n m*nm∗n的评分矩阵,也就是协同过滤中的共现矩阵。
生成共现矩阵后,推荐问题就转换成了预测矩阵中问号的值的过程。
通过每个用户对所有物品的评分向量,利用余弦相似度、皮尔逊相关系数(可以引入物品平均分的方式减少物品评分)等,找到与需要推荐用户X最相似的Top n用户
利用用户相似度和相似用户评分的加权平均偶的目标用户的评价预测。下式中,w u , s 是物品u和用户s的相似度,U s,p是用户s对物品p的评分。
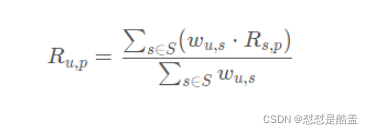
userCF主要有量大缺点,(1) 在互联网场景下,用户数量远大于商品数量,而且还会持续增加,这导致用户相似度矩阵的存储开销很大;(2) 用户的历史数据很稀疏,找到相似用户的准确度很低。
由于上面两大缺点,Amazon最终没有采用该方法,而是采用了ItemCF。ItemCF的计算过程和UserCF类似,但是在应用场景上有所不同。UserCT具备强社交属性,并且更适合发现热点以及跟踪热点的趋势。ItemCF更适用于兴趣变化较为稳定的应用。
协同过滤有两大缺点,(1) 热门的物品具有很强的头部效应,容易跟大量物品产生相似性,而尾部物品则完全相反;(2) 协同过滤仅仅利用用户和物品的交互信息,造成了信息遗漏。
2.2 矩阵分解
协同过滤是基于用户的观看历史,找到与目标用户看过同样视频的相似用户,然后找到这些相似用户喜欢看的其他视频,推荐给目标用户。矩阵分解算法则期望为每一位用户和视频生成一个隐向量,将用户和视频定位到隐向量的表示空间上,距离相近的用户和视频表明兴趣特点接近,在推荐过程中,就把距离相近的视频推荐给目标用户。
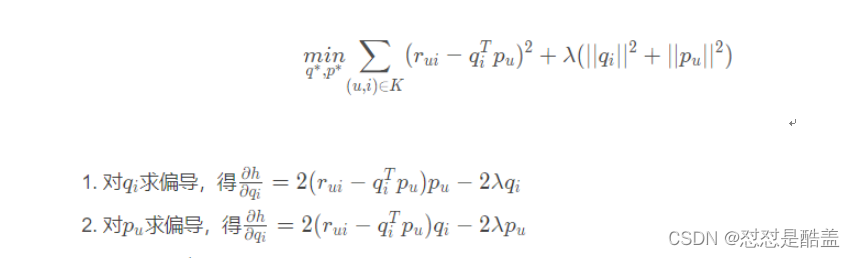
在矩阵分解的算法框架下,用户和物品的隐向量是通过分解共现矩阵得到的。对矩阵进行矩阵分解的方法主要有三种,特征值分解、奇异值分解、梯度下降。其中,特征值分解只能作用于方阵,故排除。奇异值分解要求原始的共现矩阵是稠密的,所以必须对确实的元素值进行填充,并且计算复杂度为O ( m n 2 ) 所以也不合适。因此,梯度下降成了进行矩阵分解的主要方法,目标函数是让原始评分r u i与用户向量和物品向量之积q i T p u的差尽量小,同时为了减少过拟合现象,加入正则化项。下式中,K是所有用户评分样本的集合。
矩阵分解相比协同过滤有三个优点:(1) 泛化能力强,一定程度上解决了数据稀疏问题;(2) 空间复杂度低;(3)更好的扩展性和灵活性
2.3 逻辑回归
相比协同过滤模型仅利用用户与物品的相互行为信息进行推荐,逻辑回归模型能够综合利用用户、物品、上下文等多种不同的特征。相比协同过滤和矩阵分解利用用户和物品的相似度进行推荐,逻辑回归将推荐问题看成一个分类问题,通过预测正样本的概率对物品进行排序 。
要点:
逻辑回归为什么要用sigmoid函数?
逻辑回归的目标函数是什么?利用的什么原理?
逻辑回归假设因变量y服从什么分布?
逻辑回归主要有两大优点:(1)可解释性强;(2)模型训练开销小。所以,一般在没有明显击败逻辑回归模型前,公司不会贸然加大计算资源的投入。
2.4 POLY2
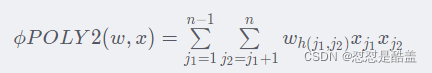
逻辑回归表达能力不强,会不可避免地造成有效信息的损失。在仅利用单一特征而非交叉特征进行判断的情况下,有时不仅是信息损失的问题,甚至会得出错误的结论。所以,我们就需要多维度特征交叉。
POLY2模型对所有特征进行了两两交叉(特征x j 1 和x j 2),并对所有的特征组合赋予权重(w h ( j 1 , j 2 )POLY2通过暴力组合特征的方式,在一定程度上解决了特征组合的问题。POLY2模型本质上仍是线性模型,其训练方法与逻辑回归并无区别,因此便于工程上的兼容。
POLY2模型有两大缺点:(1)常用的onehot编码方式太过稀疏,POLY2进行无选择的特征交叉使其更加稀疏,导致大部分交叉特征的权重缺乏有效的数据进行训练,无法收敛;(2)权重参数的数量由n nn上升到n 2 极大增加了训练复杂度。
2.5 FM
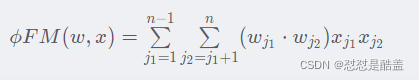
FM的提出,弥补了POLY2的缺点。常见的线性表达式如下:
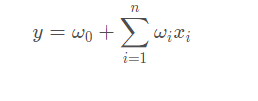
其中ω0为初始权值,或者理解为偏置项,ωi为每个特征x i 对应的权值。可以看到,这种线性表达式只描述了每个特征与输出的关系。FM的表达式如下,可观察到,只是在线性表达式后面加入了新的交叉项特征及对应的权值。
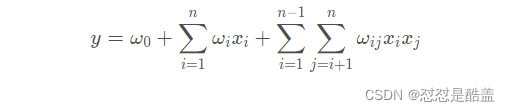
上面公式中,n代表特征数量,x i是第i个特征得值,ω是模型权重,从公式来看,模型得前半部分就是普通得LR线性组合,后半部分是交叉项:特征得组合。单单从模型的能力上讲,FM的表达能力强于LR,当交叉项参数全部为0得时候退化为普通得LR模型。
组合特征得参数一共有1/(2n(n-100))个,任意两个参数都是独立的。然而在数据稀疏性普遍存在的实际场景中,二次项参数的训练是很困难的。原因是:每个参数ω i j 的训练都需要大量xi和x j 都非零的样本;由于样本数据本来就比较稀疏,满足x i,x j 都非零的样本将会非常的少。训练样本不足,很容易导致参数w i j 不准确,最终将严重影响模型的性能。
2.6 GBDT+LR
FFM模型采用引入特征域的方式增强了模型的特征交叉能力,但无论如何,FMM智能做到2阶的特征交叉,如果继续提高特征交叉的维度,会不可避免的产生组合爆炸和计算复杂度过高的问题。GBDT+LR组合模型能有效地处理高维特征组合和筛选的问题,即GBDT构建特征工程+LR预估CTR,两步独立训练。
2.7 LS-PLM
LS-PLM又叫“大规模分段线性模型”,是阿里巴巴在前深度学习时代主流的推荐模型。如果CTR模型要预估的是女性受众点击女装广告的CTR,那么显然,我们不希望把男性用户点击数码类产品的样本数据也考虑进来,因为这样的样本不仅与女性购买女装的广告场景无关,甚至会在模型训练过程中扰乱相关特征的权重。
LS-PLM有两个优势:(1) 端到端的非线性学习能力;(2)建模时引入了L1和L2 范数,1范数使其模型稀疏性强;(3) 可分布式并行;(4) 在很多含有大量categorical特征场景中的效果确实比lr, fm, ffm要好不少。LS-PLM本质上是一个加入了注意力机制的三层神经网络模型,其中输入层是样本的特征向量,中间层是由m个神经元组成的隐层,m是分片的个数,对于一个CTR预估问题,该模型最后一层自然是由单一神经元组成的输出层。注意力机制应用在隐层和输出层之间,神经元之间的权重是由分片函数得出的注意力得分来确定的。
- 对Python实现的基于用户的CF,用户相似度计算的改进
上周实现的算法是利用余弦相似度公式来计算用户相似度 这周使用改进的公式计算用户相似度:
首先,以图书为例,如果两个用户都曾经买过《新华字典》,这丝毫不能说明他们兴趣相似,
因为绝大多数中国人小时候都买过《新华字典》。但如果两个用户都买过《数据挖掘导论》,那可以认为他们的兴趣比较相似,因为只有研究数据挖掘的人才会买这本书。换句话说,两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。因此,John S. Breese在论文①中提出了如下公式,根据用户行为计算用户的兴趣相似度:
惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
代码实现:
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1 / math.log(1 + len(users))
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W
- 对于Python实现的基于item的CF,引入物品相似度的归一化
总结:
本周由于有考试,所以知识阅读了相关书籍,侧重于理论知识的学习,对于推荐系统的传统模型的优缺点有了清晰地认识。
下周学习计划:
下周有三门考试下周还是阅读书籍 等到这两周考试考完在进行理论知识的代码实践部分。

















 6840
6840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









