







 该论文提出了一种新的Transformer辅助视觉跟踪框架,首次将Transformer引入到视觉跟踪领域。通过特征和注意力的转换,以及对经典Transformer的适应性修改,该框架能更好地利用连续帧间的时间背景信息,提高跟踪的鲁棒性。Transformer编码器强化目标模板,解码器则将跟踪线索从历史模板传递到当前帧,增强了目标搜索。实验表明,这种方法即使在简单的Siamese框架下也能表现出色,且能进一步提升基于DCF的跟踪器如DiMP的性能。
该论文提出了一种新的Transformer辅助视觉跟踪框架,首次将Transformer引入到视觉跟踪领域。通过特征和注意力的转换,以及对经典Transformer的适应性修改,该框架能更好地利用连续帧间的时间背景信息,提高跟踪的鲁棒性。Transformer编码器强化目标模板,解码器则将跟踪线索从历史模板传递到当前帧,增强了目标搜索。实验表明,这种方法即使在简单的Siamese框架下也能表现出色,且能进一步提升基于DCF的跟踪器如DiMP的性能。
Transformer Meets Tracker: Exploiting Temporal Context for Robust Visual Tracking
论文地址:https://arxiv.org/pdf/2103.11681
贡献:
我们提出了一个简洁新颖的Transformer辅助跟踪框架。据我们所知,是第一次尝试在视觉跟踪中涉及Transformer 。
我们同时考虑特征和注意转换,以更好地探索Transformer 的潜力。我们还修改了经典的Transformer,使其更适合跟踪任务。
动机:
在视频目标跟踪中,连续帧之间存在着丰富的时间背景,这在很大程度上被现有的跟踪器所忽视。在这项工作中,我们将单个视频帧桥接起来,并通过一个用于鲁棒对象跟踪的Transformer架构探索它们之间的时间上下文。Transformer 编码器通过基于注意力的特征强化来促进目标模板,这有利于高质量的跟踪模型生成。Transformer 解码器将跟踪线索从以前的模板传播到当前帧,这有助于对象搜索过程。
1、Revisting Tracking Frameworks
如图 3 所示,Siamese 网络或判别相关滤波器 (DCF) 等主流跟踪方法可以表述为类似孪生的管道,其中顶部分支使用模板学习跟踪模型,底部分支侧重于目标定位。

孪生匹配架构以样本补丁 z z z和搜索补丁 x x x作为输入,其中 z z z表示目标对象,而 x x x是后续视频帧中的大搜索区域。它们都被馈送到权重共享 CNN 网络 Ψ ( ⋅ ) Ψ(·) Ψ(⋅)。他们的输出特征图交叉相关,如下所示以生成响应图:
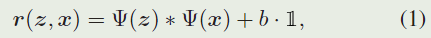
Siamese 跟踪器依赖于目标模型,即卷积核 Ψ ( z ) Ψ(z) Ψ(z),用于模板匹配。
作为另一个流行的框架,基于深度学习的DCF方法在岭回归公式下优化了跟踪模型 f f f,如下所示:
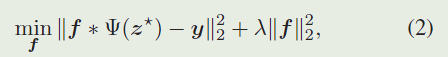
DCF 公式同时考虑了目标匹配和背景判别。在得到跟踪模型f后,响应通过 r = f ∗ Ψ ( x ) r = f * Ψ(x) r=f∗Ψ(x)生成.
传统的 DCF 方法通过傅里叶域中的封闭形式解使用循环生成的样本来解决岭回归。相比之下,最近的基于深度学习的DCF方法使用随机梯度下降或共轭梯度方法求解Eq. 2,以避免边界效应。最近的DiMP以端到端的方式通过元学习器优化上述岭回归,显示了最先进的性能。
2、Transformer for Visual Tracking
我们的目标是通过框架关系建模和时间上下文传播来改进这样一个通用跟踪框架,而无需修改它们的原始跟踪方式,例如模板匹配。
2.1、Transformer Overview

我们的Transformer 器的概述如图4所示。类似于经典的Transformer 架构,编码器利用自注意力块相互加强多个模板特征。在解码过程中,交叉注意力块连接模板和搜索分支以传播时间上下文(例如,特征和注意力)。
为了适应视觉跟踪任务,我们通过以下方式修改经典Transformer:
(1)编码器-解码器分离。如图1所示,我们没有在NLP任务中级联编码器和解码器,而是将编码器和解码器分成两个分支,以适应类似孪生的跟踪方法。

(2)块权重共享。编码器和解码器中的自注意力块(图 4 中的黄色框)共享权重,该权重在同一特征空间中转换模板和搜索嵌入,以促进进一步的交叉注意力计算。
(3)实例归一化。在 NLP 任务中,词嵌入使用层归一化单独归一化。由于我们的Transformer接收图像特征嵌入,我们在实例(图像补丁)级别对这些嵌入进行联合归一化,以保留有价值的图像幅度信息。
(4) Slimming 设计。效率对于视觉跟踪场景至关重要。为了在速度和性能方面取得良好的平衡,我们通过省略全连接的前馈层来缩小经典的Transformer。
2.2、Transformer Encoder
经典Transformer中的基本块是注意机制,它接收查询 Q ∈ R N q × C Q∈R^{N_q×C} Q∈RNq×C、密钥 K ∈ R N k × C K∈R^{N_k×C} K∈RNk×C和值 V ∈ R N k × C V∈{R^{N_k×C}} V∈RNk×C作为输入。我们采用点积计算查询和键之间的相似度矩阵 A K → Q ∈ R N q × N k A_{K→Q}∈R^{N_q×N_k} AK→Q∈RNq×Nk,如下所示:
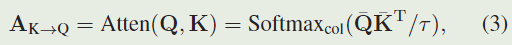
其中 Q ‾ \overline{Q} Q和 K ‾ \overline{K} K是 Q 和 K 在通道维度上的 l 2 l_2 l2归一化特征,$τ 是控制 S o f t m a x 分布的温度参数,受模型蒸馏和对比学习技术的启发。有了键到查询的传播矩阵 是控制 Softmax 分布的温度参数,受模型蒸馏和对比学习技术的启发。有了键到查询的传播矩阵 是控制Softmax分布的温度参数,受模型蒸馏和对比学习技术的启发。有了键到查询的传播矩阵A_{K→Q} ,我们可以通过 ,我们可以通过 ,我们可以通过A_{K→Q}V∈R^{N_q×C}$对值进行变换。
在我们的框架中,Transformer编码器接收一组空间大小为 H × W H×W H×W、维数为 C C C的模板特征 T i ∈ R C × H × W T_i∈R^{C×H×W} Ti∈RC×H×W,将这些模板特征进一步串联形成模板特征集合 T = C o n c a t ( T 1 , . . . , T n ) ∈ R n × C × H × W T =Concat(T_1,...,T_n)∈R^{n×C×H×W} T=Concat(T1,...,Tn)∈Rn×C×H×W。为了方便注意力计算,我们将 T T T重塑为 T ′ ∈ R N T × C T^{'}∈R^{N_T×C} T′∈RNT×C,其中 N t = n × H × W N_t = n × H × W Nt=n×H×W。为此,我们首先计算自注意图 A T → T = A t t e n ( φ ( T ′ ) , φ ( T ′ ) ) ∈ R N T × N T A_{T→T} = Atten(\varphi(T'),\varphi(T'))∈R^{N_T×N_T} AT→T=Atten(φ(T′),φ(T′))∈RNT×NT,其中 φ ( ⋅ ) φ(·) φ(⋅)是一个1 × 1的线性变换,将嵌入通道从C减小到C/4。
基于自相似矩阵 A T → T A_{T→T} AT→T,我们通过 A T → T T ′ A_{T→T}T' AT→TT′对模板特征进行变换,并将其作为残差项加入到原始特征 T ′ T' T′中,如下所示:

其中, T ^ ∈ R N T × C \hat{T}\in{R^{N_T\times C}} T^∈RNT×C是编码的模板特征和INS。 N o r m ( ⋅ ) Norm(·) Norm(⋅)表示联合 ℓ 2 ℓ_2 ℓ2归一化来自图像块的所有嵌入的实例归一化,即特征映射级 ( T i ∈ R C × H × W ) (T_i∈R^{C×H×W}) (Ti∈RC×H×W)归一化。
由于自关注,多个时间上不同的模板特征相互聚合以生成高质量的 T ^ \hat{T} T^,该值被进一步馈送到解码块以加强搜索补丁特征。此外,该编码模板表示 T ^ \hat{T} T^也被重塑回 T e n d ∈ R n × C × H × W T_{end}∈R^{n×C×H×W} Tend∈Rn×C×H×W,用于跟踪模型生成。
2.3、Transformer Decoder
Transformer解码器以搜索补丁特征 S ∈ R C × H × W S∈R^{C×H×W} S∈RC×H×W 作为输入。与编码器类似,我们首先将此特征重塑为 S ′ ∈ R N s × C S'\in{R^{N_s\times C}} S′∈RNs×C,其中 N S = H × W N_S=H×W NS=H×W。然后, S ′ S' S′被馈送到自我注意块,如下所示:
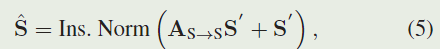
其中 A S → S = A t t e n ( φ ( S ′ ) , φ ( S ′ ) ) ∈ R N S × N S A_{S→S}=Atten(\varphi(S'),\varphi(S'))∈R_{N_S×N_S} AS→S=Atten(φ(S′),φ(S′))∈RNS×NS为搜索特征的自注意矩阵。
Mask Transformation
基于Eq. 5的搜索特征 S ^ \hat{S} S^和前面Eq. 4提到的编码模板特征 T ^ \hat{T} T^ ,我们通过 A T → S = ∈ ( ϕ ( S ^ ) , ϕ ( T ^ ) ) ∈ R N S × N T A_{T→S}=∈(\phi(\hat{S}),\phi(\hat{T}))\in R^{N_S×N_T} AT→S=∈(ϕ(S^),ϕ(T^))∈RNS×NT来计算它们之间的交叉注意矩阵, ϕ ( ⋅ ) \phi(·) ϕ(⋅)是类似于φ(·)的1×1线性变换块。这种交叉注意力图$ A_{T→S}$建立了帧之间的像素到像素的对应关系,支持时间上下文传播。
在视觉跟踪中,我们知道模板中的目标位置。为了传播时间运动先验,我们通过 m ( y ) = e x p ( − ∣ ∣ y − c ∣ ∣ 2 2 σ 2 ) m(y)=exp(-\frac{||y-c||^2}{2\sigma^2}) m(y)=exp(−2σ2∣∣y−c∣∣2)构造了模板特征的高斯形掩模,其中 c 是真实目标位置。与特征集成 T 类似,我们还将这些掩码 m i ∈ R H × W m_i ∈ R^{H×W} mi∈RH×W 连接起来形成掩码集成 M = C o n c a t ( m 1 , . . . , m n ) ∈ R n × H × W M = Concat(m_1,...,m_n)∈R^{n×H×W} M=Concat(m1,...,mn)∈Rn×H×W,它进一步展平为 M ′ ∈ R N T × 1 M'∈ R^{N_T×1} M′∈RNT×1。基于交叉注意力图 A T → S A_{T→S} AT→S,我们可以通过 A T → S M ′ ∈ R N S × 1 A_{T→S}M'∈R^{N_S×1} AT→SM′∈RNS×1 轻松地将先前的掩码传播到搜索补丁。转换后的掩码有资格作为搜索特征 S ^ \hat{S} S^ 的注意权重,如下所示:
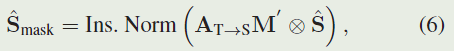
Feature Transformation
除了空间注意力外,将上下文信息从模板特征 T ^ \hat{T} T^传播到搜索特征 S ^ \hat{S} S^也是可行的。在视频中,背景场景往往变化剧烈,而临时传播是不合理的,这有利于目标表征的传达。因此,在进行特征变换之前,我们首先通过 T ⊗ M ’ T⊗M’ T⊗M’对模板特征进行掩膜,抑制背景区域。然后,通过交叉注意矩阵 A T → S A_{T→S} AT→S,可以通过 A T → S ( T ^ ⊗ M ′ ) ∈ R N S × C A_{T→S}(\hat{T}⊗M')∈R^{N_S×C} AT→S(T^⊗M′)∈RNS×C计算变换后的特征,并将其作为残差项加入到 S ^ \hat{S} S^中:
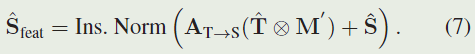
与原始 S ^ \hat{S} S^相比,特征级增强型 S ^ f e a t \hat{S}_{feat} S^feat从一系列模板特征 T ^ \hat{T} T^中聚合了时间上不同的目标表示,以提升自身。
最后,我们将前面提到的空间掩码特征 S ^ m a s k \hat{S}_{mask} S^mask和特征级增强特征 S ^ f e a t \hat{S}_{feat} S^feat等同地组合在一起,并进一步按如下方式进行归一化:

最终的输出特征 S ^ f i n a l ∈ R N S × C \hat{S}_{final}∈R^{N_S×C} S^final∈RNS×C被重塑回原始大小以用于视觉跟踪。我们将重构后的 S f i n a l S_{final} Sfinal表示为 S d e c o d e d ∈ R C × H × W S_{decoded}\in R^{C×H×W} Sdecoded∈RC×H×W。
2.4、Tracking with Transformer-enhanced Features
Transformer结构通过生成高质量的模板特征 T e n c o d e d T_{encoded} Tencoded和搜索特征 S d e c o d e d S_{decoded} Sdecoded来简化跟踪过程。我们使用 T e n c o d e d T_{encoded} Tencoded学习跟踪模型,下面是两个流行的范例:
- 孪生管道。在这种情况下,我们只需将 T e n c o d e d T_{encoded} Tencoded中的目标特征裁剪为模板CNN内核,与 S d e c o d e d S_{decoded} Sdecoded进行卷积以生成响应,这与SiamFC中的相互关系相同。
- DCF管道。遵循DiMP方法中的端到端DCF优化,我们使用 T e n c o d e d T_{encoded} Tencoded与 S d e c o d e d S_{decoded} Sdecoded进行卷积来生成响应,从而生成一个判别式CNN内核。
在获得跟踪响应后,我们利用DiMP中提出的分类损失,以端到端的方式对骨干网、Transformer和跟踪模型进行联合训练。
在在线跟踪过程中,为了更好地利用时间线索并适应目标的外观变化,我们对模板集合 T T T进行了动态更新。具体来说,我们在 T T T中删除最旧的模板,并每5帧将当前收集的模板特征添加到T中。
人们普遍认为DiMP中的DCF公式优于Siamese跟踪器中的简单相互关联。然而,在实验中,我们证明了在我们的Transformer体系结构的帮助下,一个经典的Siamese管道能够对抗最近的DiMP。同时,通过我们的变压器,DiMP跟踪器获得了进一步的性能改进。
如图五所示,尽管强基线DiMP已经显示出令人印象深刻的干扰辨别能力,但我们设计的Transformer进一步帮助它抑制背景置信度以实现鲁棒跟踪。
















 1327
1327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









