







运维监控系统
监控系统是实现自动化运维的基础,在一个IT环境中会存在各种各样的设备,例如,硬件基础设施需要监控;软件运行状态需要监控;程序中的API需要监控;程序执行脚本需要监控;以及数据库的慢查询需要监控等等。
包含组件
一个完整的运维监控平台,应该包含以下功能:
- 指标数据采集(抓取)
- 指标数据存储
- 指标数据趋势分析及可视化
- 告警
监控体系(自底向上)
- 系统层监控
- 系统监控:CPU、Load. Memory、 Swap、Disk IO、 Processes. Kernel Parameters
- 网络监控:网络设备、工作负载、网络延迟、丢包率等
- 中间件及基础设施类系统监控
- 消息中间件:Kafka、RocketMQ和RabbitMQ等
- Web服务容器:Tomcat和Jetty等
- 数据库及缓存系统:MySQL、PostgreSQL、 MogoDB、ElasticSearch和Redis等
- 数据库连接池:ShardingSpere等
- 存储系统:Ceph、minIO、FastDFS等
- 应用层监控
- 用于衡量应用程序代码的状态和性能
- 业务层监控
- 用于衡量应用程序的价值,例如电子商务网站上的销售量
- QPS、DAU日活、转化率
- 业务接口:登录数、注册数、订单量、搜索量和支付量等
云原生时代可观测性
在云原生时代,基础设施与应用的部署构建都发生了极大变化,传统的监控方式已经无法适应云原生的场景。在这个背景下,社区引入了云原生可观测性这一理念。可观测性概念最早由Apple 的工程师 Cindy Sridharan 提出,作为监控的进一步延伸,可观测性与监控的区别可以总结为:“监控告诉我们系统的哪些部分是工作的。可观测性告诉我们哪里为什么不工作了”。
当前,主流可观测性系统主要基于Metrics、Traces、Logs三大数据类型构建,围绕着这三种数据类型,开源社区构建了多种多样的开源产品,像Prometheus, Cortex, Fluentd, ELK, Loki, Jaeger等。这些开源产品极大的丰富了人们在云原生可观测性实践中的选择。然而,这些开源组件大多专注于解决某个特定场景的可观测性问题,应对复杂业务场景往往会让开发运维人员陷入困境。
可观测性系统:
- 指标监控(Metics):随时间推移产生的一些与监控相关的可聚合数据点;
- 日志监控(Logging):离散式的日志或事件;
- 链路跟踪(Tracing):分布式应用调用链跟踪;
CNCF将可观测性和数据分析归类一个单独的类别,且划分成了4个子类
- 监控系统:以Prometheus等为代表;
- 日志系统:以ElasticStack和PLG Stack等为代表;
- 分布式调用链跟踪系统:以Zipkin.Jacger.SkyWalking.Pinpoint等为代表;
- 混沌工程系统:以ChaosMonkey和ChaosBlade等为代表;
可观测性业界动态
AWS
从CloudWatch到AMP/AMG,全面拥抱开源。
CloudWatch一直以来都是AWS最主要的监控服务,包含了监控、告警、日志、事件等功能。为了应对云原生可观测性场景,CloudWatch推出了Container Insights功能,并支持Prometheus指标接入。Container Insights为用户构建了Prometheus指标面板,应用性能监控、集群拓扑图等功能。
阿里云ARMS
以应用监控为核心,构建全链路监控能力。
阿里云ARMS主要能力围绕应用监控构建,包括前端监控、后端监控、移动端监控、业务监控,云拨测等。整体功能如下图:
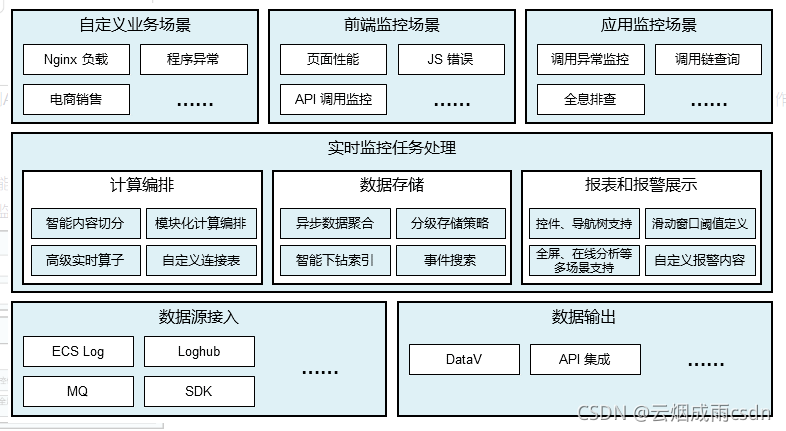
为了补足云原生可观测性能力,ARMS又陆续发布了Prometheus监控、容器监控(Container Insights)等功能。
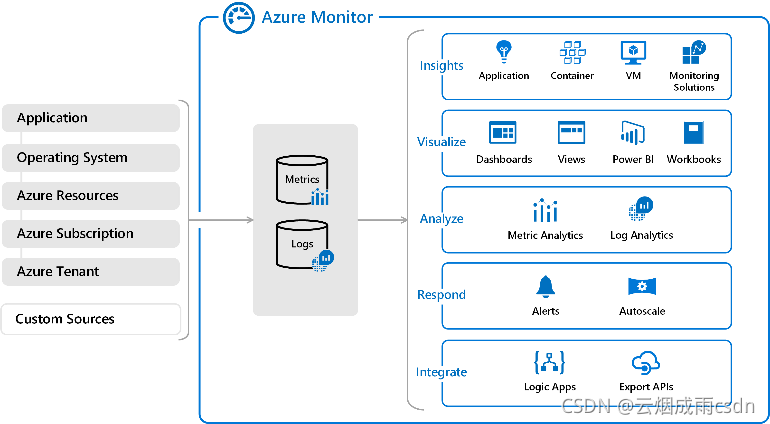
Azure Monitor
Azure Monitor是Azure统一的监控服务,支持Metrics, Logs, Traces等多种数据类型接入,为客户提供可视化、分析、告警、洞察等功能。总体功能如下图:
Vmware Tanzu
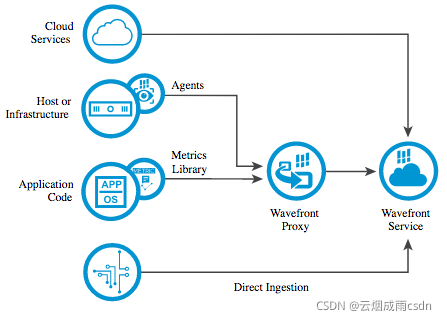
Wavefront是Vmware收购的云计算监控初创公司,以满足VMware将其监控功能扩展到云和容器应用程序的愿景。收购Wavefront也给Vmware带来大量的用户,包括Box、思杰、Clover、Groupon、Intuit、Lyft、SpaceApe、Snowflake和Yammer等。
Wavefront定位为高性能流式分析平台,支持metrics, histograms, traces/spans等多种数据类型,同时也对容器洞察做了专门支持。Wavefront架构图如下:
著名的监控方法论
Google的四个黄金指标
常用于在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题
,适用于应用及服务监控。
主要关注与以下四种类型的指标:延迟,通讯量,错误以及饱和度:
1、延迟:服务请求所需时间。
记录用户所有请求所需的时间,重点是要区分成功请求的延迟时间和失败请求的延迟时间。 例如在数据库或者其他关键祸端服务异常触发HTTP 500的情况下,用户也可能会很快得到请求失败的响应内容,如果不加区分计算这些请求的延迟,可能导致计算结果与实际结果产生巨大的差异。除此以外,在微服务中通常提倡“快速失败”,开发人员需要特别注意这些延迟较大的错误,因为这些缓慢的错误会明显影响系统的性能,因此追踪这些错误的延迟也是非常重要的。
2、通讯量:监控当前系统的流量,用于衡量服务的容量需求。
流量对于不同类型的系统而言可能代表不同的含义。例如,在HTTP REST API中, 流量通常是每秒HTTP请求数;
3、错误:监控当前系统所有发生的错误请求,衡量当前系统错误发生的速率。
对于失败而言有些是显式的(比如, HTTP 500错误),而有些是隐式(比如,HTTP响应200,单实际业务流程依然是失败的)。
对于一些显式的错误如HTTP 500可以通过在负载均衡器(如Nginx)上进行捕获,而对于一些系统内部的异常,则可能需要直接从服务中添加钩子统计并进行获取。
4、饱和度:衡量当前服务的饱和度。
主要强调最能影响服务状态的受限制的资源。 例如,如果系统主要受内存影响,那就主要关注系统的内存状态,如果系统主要受限与磁盘I/O,那就主要观测磁盘I/O的状态。因为通常情况下,当这些资源达到饱和后,服务的性能会明显下降。同时还可以利用饱和度对系统做出预测,比如,“磁盘是否可能在4个小时候就满了”。
Netflix的USE方法
USE方法由Netflix的内核和性能工程师Rendan Gregg提出,主要用于分析系统性能问题。
1、使用率(Utilization)
关注系统资源的使用情况。这里的资源主要包括但不限于:CPU,内存,网络,磁盘等等100%的使用率通常是系统性能瓶颈的标志。
2、饱和度(Saturation)
例如CPU的平均运行排队长度,这里主要是针对资源的饱和度(注意,不同于4大黄金信号),任何资源在某种程度上的饱和都可能导致系统性能的下降。
3、错误(Errors)
错误计数
例如:“网卡在数据包传输过程中检测到的以太网网络冲突了14次”。
RED方法
RED方法是Weave Cloud在基于Google的4个黄金指标的原则下结合。
Prometheus以及Kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用以及微服务架构应用的监控和度量。
在四大黄金指标的原则下,RED方法可以有效地帮助用户衡量云原生以及微服务应用下的用户体验问题。
RED方法主要关注以下3种关键指标:
- (Request)Rate:每秒钟接收的请求数;
- (Request)Errors:每秒失败的请求数;
- (Request)Duration:每个请求所花费的时长;
开源解决方案
1. zabbix
Zabbix 是一个企业级分布式开源监控解决方案。
Zabbix 软件能够监控众多网络参数和服务器的健康度、完整性。Zabbix 使用灵活的告警机制,允许用户为几乎任何事件配置基于邮件的告警。这样用户可以快速响应服务器问题。Zabbix 基于存储的数据提供出色的报表和数据可视化能。这些功能使得 Zabbix 成为容量规划的理想选择。
2. Prometheus
Prometheus是一个开源监控系统,它前身是SoundCloud的警告工具包。从2012年开始,许多公司和组织开始使用Prometheus。该项目的开发人员和用户社区非常活跃,越来越多的开发人员和用户参与到该项目中。目前它是一个独立的开源项目,且不依赖与任何公司。为了强调这点和明确该项目治理结构,Prometheus在2016年继Kurberntes之后,加入了Cloud Native Computing Foundation。
3. Nagios
Nagios是一款开源的企业级监控系统,能够实现对系统CPU、磁盘、网络等方面参数的基本系统监控,以及 SMTP,POP3,HTTP,NNTP等各种基本的服务类型。另外通过安装插件和编写监控脚本,用户可以实现应用监控,并针对大量的监控主机和多个对象 部署层次化监控架构。
4. anglia
Ganglia是加州大学伯克利分校发起的一个开源集群监控项目,设计之初是用于监控数以千计的网络节点。Ganglia是一个跨平台可扩展的,高性能计算系统下的分布式监控系统。它已被广泛移植到各种操作系统和处理器架构上。
5. Open-falcon
Open-falcon是小米运维团队从互联网公司的需求出发,根据多年的运维经验,结合SRE、SA、DEVS的使用经验和反馈,开发的一套面向互联网的企业级开源监控产品。















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











