







Muduo 概述
Muduo 是一个用 C++ 编写的高性能网络库,由陈硕开发,主要用于开发 Linux 环境下的高性能网络应用程序。以下从几个方面对其进行详细介绍:
特点
- 事件驱动与非阻塞 I/O:Muduo 基于 Reactor 模式实现,使用了 Linux 的 epoll 作为 I/O 多路复用机制,结合非阻塞 I/O 操作,能高效处理大量并发连接。这使得它在处理高并发场景时表现出色,可轻松应对成千上万的并发连接。
- 线程安全:在多线程环境下,Muduo 对共享资源的访问进行了细致的处理,确保线程安全。它使用了线程局部存储(Thread Local Storage,TLS)和互斥锁等机制,避免了多线程访问共享资源时可能出现的竞态条件问题。
- 易于使用:Muduo 提供了简洁且一致的接口,使得开发者能够快速上手。它将复杂的网络编程细节封装起来,让开发者只需关注业务逻辑的实现。例如,开发者可以方便地创建 TCP 服务器和客户端,处理网络连接、数据收发等操作。
- 高性能:通过优化数据结构和算法,减少不必要的内存拷贝和系统调用,Muduo 实现了高性能的网络通信。它采用了零拷贝技术,避免了数据在用户空间和内核空间之间的多次拷贝,提高了数据传输效率。
- 跨平台性:虽然 Muduo 主要针对 Linux 平台进行开发和优化,但由于其基于标准 C++ 和 POSIX 标准库,经过一定的修改和适配,也可以在其他类 Unix 系统上使用。
核心组件
- EventLoop:事件循环是 Muduo 的核心组件之一,负责监听 I/O 事件和定时事件。每个线程可以有一个 EventLoop 对象,它会不断地循环调用 epoll_wait 来获取就绪的 I/O 事件,并将事件分发给相应的事件处理器进行处理。
- Channel:通道是对 I/O 事件的抽象,每个 Channel 对象对应一个文件描述符(如套接字),负责处理该文件描述符上的读写事件。Channel 对象会将事件的处理逻辑封装在回调函数中,当事件发生时,调用相应的回调函数进行处理。
- TcpServer 和 TcpClient:这两个类分别用于创建 TCP 服务器和客户端。TcpServer 可以监听指定的端口,接受客户端的连接请求,并为每个连接创建一个 TcpConnection 对象进行管理;TcpClient 则可以连接到指定的服务器,并处理与服务器之间的通信。
- TcpConnection:表示一个 TCP 连接,负责处理连接的建立、数据的读写和连接的关闭等操作。TcpConnection 对象会维护连接的状态信息,并在连接状态发生变化时调用相应的回调函数通知上层应用程序。
应用场景
- 网络服务器开发:由于其高性能和高并发处理能力,Muduo 非常适合开发各种类型的网络服务器,如 Web 服务器、游戏服务器、即时通讯服务器等。
- 分布式系统:在分布式系统中,节点之间的通信需要高效可靠的网络库支持。Muduo 可以用于实现分布式系统中的节点通信模块,确保节点之间的数据传输快速、稳定。
下载路径
环境准备
- linux kernel version5.15.0-113-generic (ubuntu 22.04.6)
- gcc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
- cmake version 3.22
安装基本工具
sudo apt-get update
sudo apt-get install -y wget cmake build-essential unzip git
sudo
sudo 并非安装的软件包,而是一个命令,其作用是让普通用户以超级用户(root)的权限去执行后续命令。由于安装软件通常需要管理员权限,所以要使用 sudo。
apt-get
apt-get 是基于 Debian 系统的包管理工具,负责处理软件包的安装、更新、删除等操作。install 是 apt-get 的一个子命令,用于安装指定的软件包。
-y
这是 apt-get 的一个选项,意思是在安装过程中自动回答所有询问为 “是”,从而避免手动确认安装过程中的提示信息,实现自动化安装。
wget
功能:wget 是一个用于从网络上下载文件的命令行工具。它支持 HTTP、HTTPS 和 FTP 等多种协议,能够通过 URL 下载文件,还可以进行断点续传、递归下载等操作。
cmake
功能:cmake 是一个跨平台的自动化构建工具,用于生成不同平台和编译器所需的构建文件,如 Unix/Linux 下的 Makefile、Windows 下的 Visual Studio 项目文件等。它通过读取 CMakeLists.txt 文件中的配置信息,生成适合当前平台的构建文件,方便项目的编译和构建。
build-essential
功能:build-essential 是一个元包,它包含了编译 C 和 C++ 程序所需的基本工具和库,例如 gcc(GNU C 编译器)、g++(GNU C++ 编译器)、make(自动化编译工具)等。安装这个包可以确保系统具备编译 C/C++ 项目的基本环境。
编译指令
git clone https://github.com/youngyangyang04/muduo-core.git
进入到muduo-core文件后,创建build文件夹,并且进入build文件:
mkdir build && cd build
生成可执行程序文件:
cmake .. && make -j${nproc}
make:它是一个基于依赖关系的自动化编译工具,会依据 cmake 生成的 Makefile 文件来编译项目。Makefile 中定义了项目的编译规则、依赖关系以及编译命令。
-j:此选项用于开启并行编译,后面需要跟上一个数字,表示同时运行的编译任务数量。并行编译能够显著提升项目的编译速度,尤其是在多核处理器的系统上。
${nproc}:这是一个 shell 变量,其值为当前系统的 CPU 核心数。使用 ${nproc} 可以让 make 命令依据系统的 CPU 核心数来确定并行编译的任务数量,从而充分利用系统资源。
运行程序
cd example && ./testserver
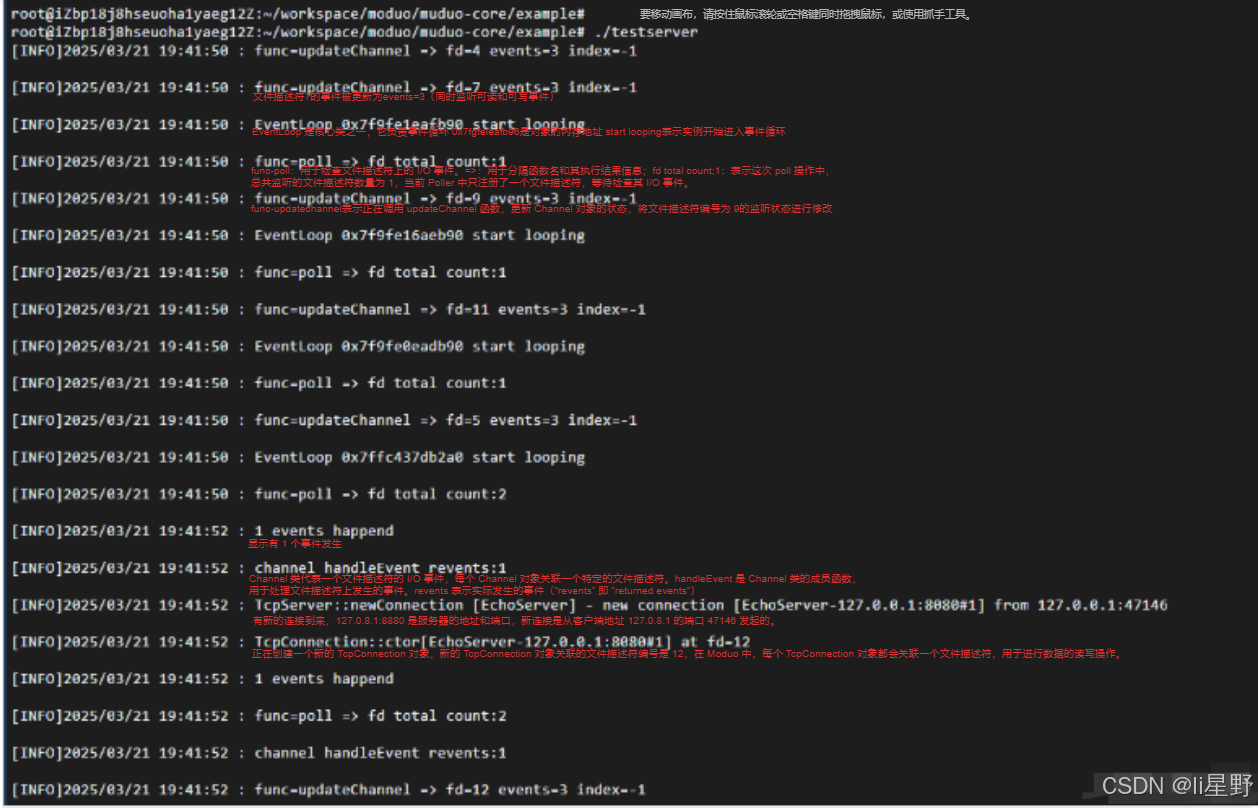
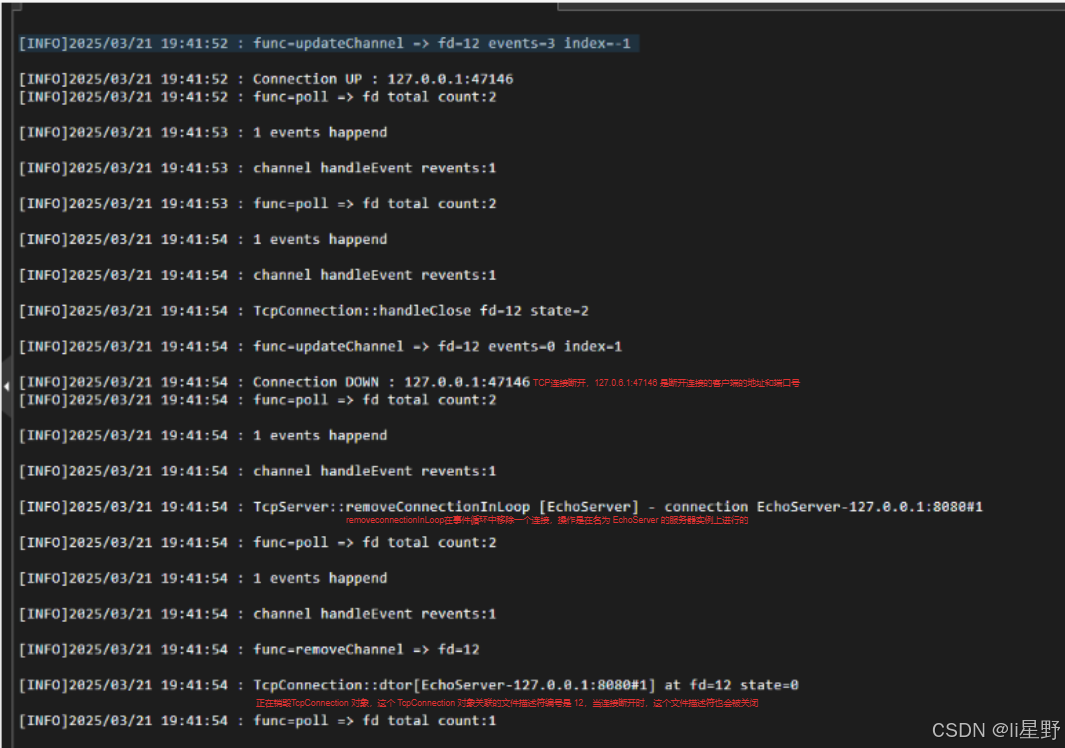
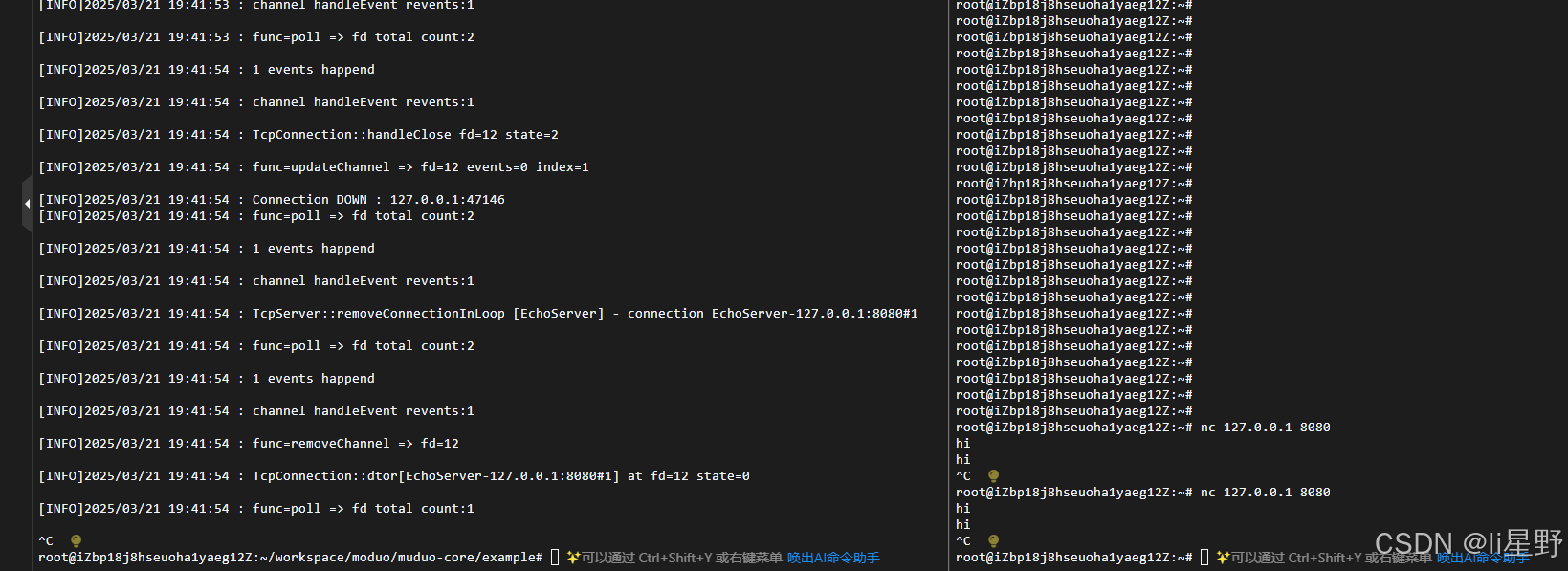
nc 127.0.0.1 8080
该命令的主要功能是尝试与 IP 地址为 127.0.0.1、端口号为 8080 的目标主机和端口建立网络连接。
nc:也就是 netcat,这是一款功能强大的网络工具,能在网络中读写数据,常被用于网络调试、端口扫描、文件传输以及创建简单的网络服务等场景。
127.0.0.1:这是一个特殊的 IP 地址,代表本地主机(localhost)。当你在某台计算机上使用这个地址时,就意味着是在与这台计算机自身进行通信。
8080:它是目标端口号。在网络通信里,端口号用于区分同一台主机上的不同网络服务。8080 是一个常用的非标准 HTTP 端口,很多 Web 服务器会默认使用这个端口。
Reactor和Proactor 分别是什么 区别是什么
概念
- Reactor 模式:Reactor 模式是一种同步的 I/O 多路复用模型。在该模式里,有一个专门的事件分离器(多路复用器,如 select、poll、epoll 等)负责监听所有的 I/O 事件,当某个 I/O 事件就绪(例如套接字有数据可读或可写)时,事件分离器会将事件分发到对应的事件处理器进行处理。事件处理器通常是预先注册好的回调函数,负责实际的 I/O 操作和业务逻辑处理。
- Proactor 模式:Proactor 模式是一种异步 I/O 模型。在这种模式下,应用程序将 I/O 操作请求发送给操作系统内核,内核会在后台完成实际的 I/O 操作,当操作完成后,内核会通知应用程序。应用程序只需提供一个完成回调函数,当 I/O 操作完成时,该回调函数会被调用,应用程序可以在回调函数中处理操作结果。
区别
- I/O 操作方式
- Reactor 模式:是同步的 I/O 多路复用,应用程序需要主动从内核缓冲区读取数据或写入数据到内核缓冲区,I/O 操作由应用程序在事件处理器中完成。
- Proactor 模式:是异步 I/O,内核会自动完成数据的读写操作,将数据从内核缓冲区复制到用户缓冲区或从用户缓冲区复制到内核缓冲区,应用程序只需在操作完成后处理结果。
- 事件处理时机
- Reactor 模式:事件分离器在检测到 I/O 事件就绪时通知事件处理器,事件处理器在此时开始进行 I/O 操作。
- Proactor 模式:应用程序发起 I/O 操作请求后,继续执行其他任务,当 I/O 操作完成时,内核通知应用程序,应用程序才处理操作结果。
- 实现复杂度
- Reactor 模式:实现相对简单,因为它基于同步 I/O 多路复用技术,许多操作系统都提供了相应的支持。
- Proactor 模式:实现较为复杂,需要操作系统提供异步 I/O 的支持,不同操作系统的异步 I/O 接口可能不同。
- 性能特点
- Reactor 模式:在处理大量并发连接时,由于需要应用程序主动进行 I/O 操作,可能会导致一定的性能开销。
- Proactor 模式:由于内核自动完成 I/O 操作,应用程序可以在 I/O 操作期间处理其他任务,因此在高并发、大流量的场景下,性能可能更好。
适用场景
- Reactor 模式:适用于对响应时间要求较高、并发连接数不是特别大的场景,如 Web 服务器、聊天服务器等。
- Proactor 模式:适用于对吞吐量要求较高、I/O 操作比较耗时的场景,如文件服务器、数据库服务器等。
大白话解释一下
这两个都是处理网络请求的模式,好比餐厅的两种上菜方式:
👉 Reactor(反应器模式):就像餐厅的服务员(事件分离器)站在门口,盯着所有桌子(连接)。当某桌客人(I/O 事件)举手说 “可以点菜了”(就绪),服务员就喊对应的厨师(事件处理器)来处理。但厨师得自己去厨房(内核缓冲区)端菜(读写数据),处理完业务逻辑。(举例子)比如 Java 的 NIO 就是典型的 Reactor,用 Selector 监听事件,然后自己读数据。
👉 Proactor(主动器模式):更像外卖平台。你(应用程序)下单(发起 I/O 请求)后继续干别的,外卖员(内核)直接把餐做好(完成 I/O)送到你家(用户缓冲区),然后打电话(回调)通知你 “菜到了直接吃”。(对比)比如 Windows 的 IOCP 就是 Proactor,内核负责读写,完成后回调通知。
它们的区别主要在四个方面:
❶ 干活方式:
Reactor 是 “你喊我我才动”—— 事件就绪了我(应用)自己读写;
Proactor 是 “你全包了告诉我结果”—— 我(应用)只下单,内核全包读写,完了通知我。
❷ 通知时机:
Reactor:“客人举手了,快来处理”(就绪通知);
Proactor:“菜做好了,快来吃”(完成通知)。
❸ 难度系数:
Reactor:用 select/epoll 这些现成工具,像拼乐高,容易上手;
Proactor:得内核支持异步 IO(比如 Linux 的 aio_系列函数),不同系统接口不一样,像组装定制家具,麻烦点。
❹ 适合场景:
Reactor:适合需要快速响应的场景,比如小饭馆(Web 服务器),同时接待几十桌,每桌处理快;
Proactor:适合处理重体力活,比如中央厨房(文件服务器),一次处理大量耗时任务,内核帮忙分担压力。
(总结举例)举个生活中的例子:
Reactor 像奶茶店 —— 店员盯着排队的人,谁到了就现做奶茶;
Proactor 像自助咖啡机 —— 你按按钮(发起请求),机器自己煮(内核处理),煮好了叮咚提醒(回调)。
所以简单说,Reactor 是 “事件驱动,自己干活”,Proactor 是 “异步委托,内核兜底”。实际项目中,Netty 用的是 Reactor(基于 NIO),而 Windows 的高性能服务器更倾向 Proactor。根据业务需要选择:需要低延迟用 Reactor,需要高吞吐量(比如海量文件传输)用 Proactor。
可能有些比喻不够严谨,但核心区别应该抓住了:I/O 操作谁负责(应用 vs 内核),通知的是就绪还是完成,以及适用的场景特性。



















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











