







1.作用场景
在学习深度学习模型的过程中,我们经常需要做模型对比,看看模型大小和计算量是否相比他人的模型有进一步的优化,此外,模型的结构是否合理,每个部分的输入输出是什么样的?这些都需要清楚的了解才能进一步进行网络优化。
2. talk is easy, show me the code
import torch # 如果前面已经导入过torch,这里就可以删除
from torchinfo import summary # 使用 torchinfo 替代 pytorch_model_summary
from thop import profile, clever_format
# 假设已经定义了 `model` 并加载到设备上,如果没有定义请在此处定义
model = ...
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
# 定义输入张量
input_x = torch.randn(1, 4, 128, 128, 128).to(device)
# 使用 torchinfo 打印模型摘要
print(summary(model, input_size=(1, 4, 128, 128, 128), device=device.type))
# 使用 thop 计算 FLOPs 和参数量
flops, params = profile(model, inputs=(input_x,))
flops, params = clever_format([flops, params], "%.2f")
print(f"FLOPs: {flops}, Params: {params}")
3. 输出内容展示
3.1 首先会打印出模型的整体结构,以及每一层的名字,输出的tensor的形状,最右边是参数量
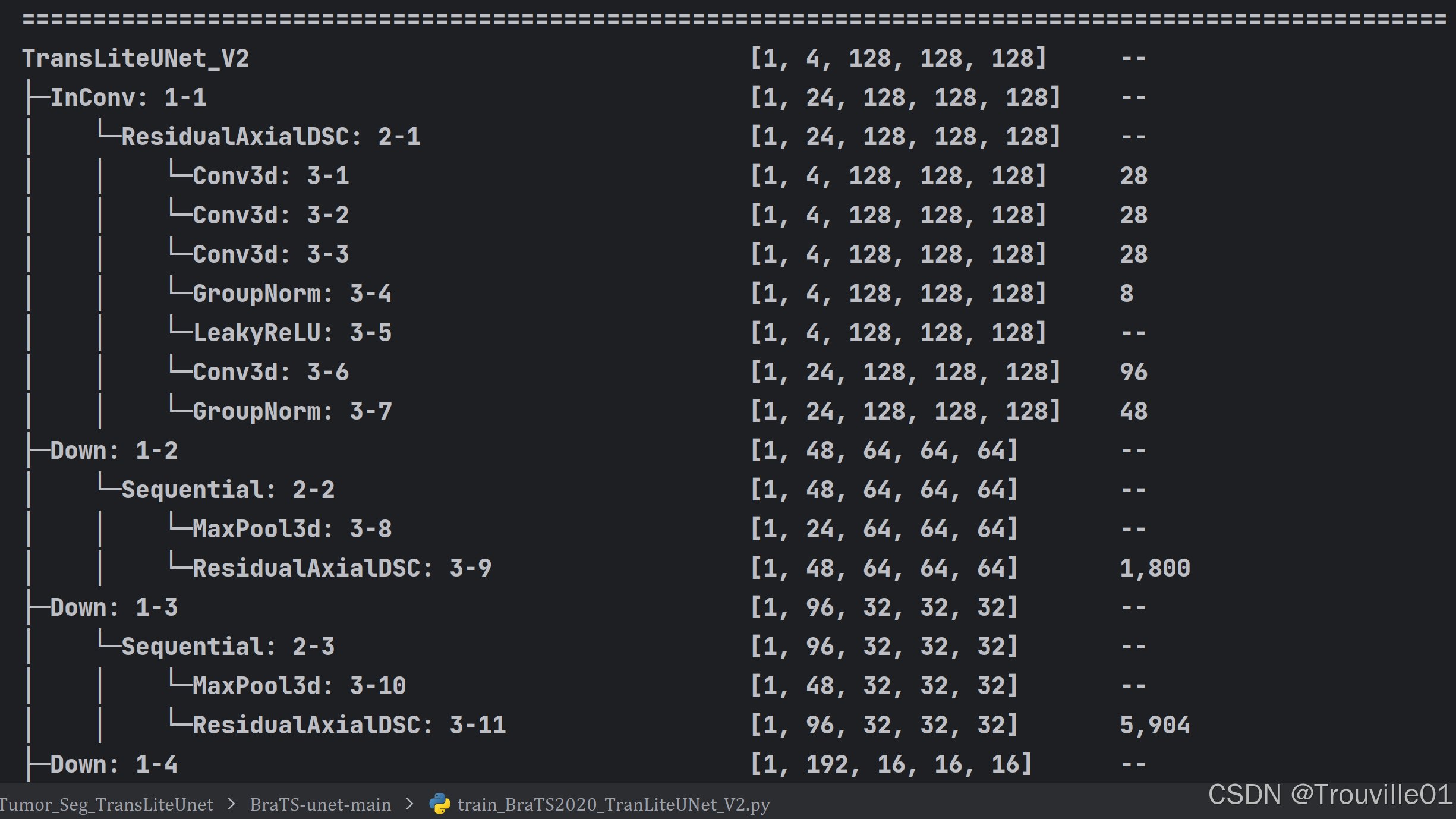
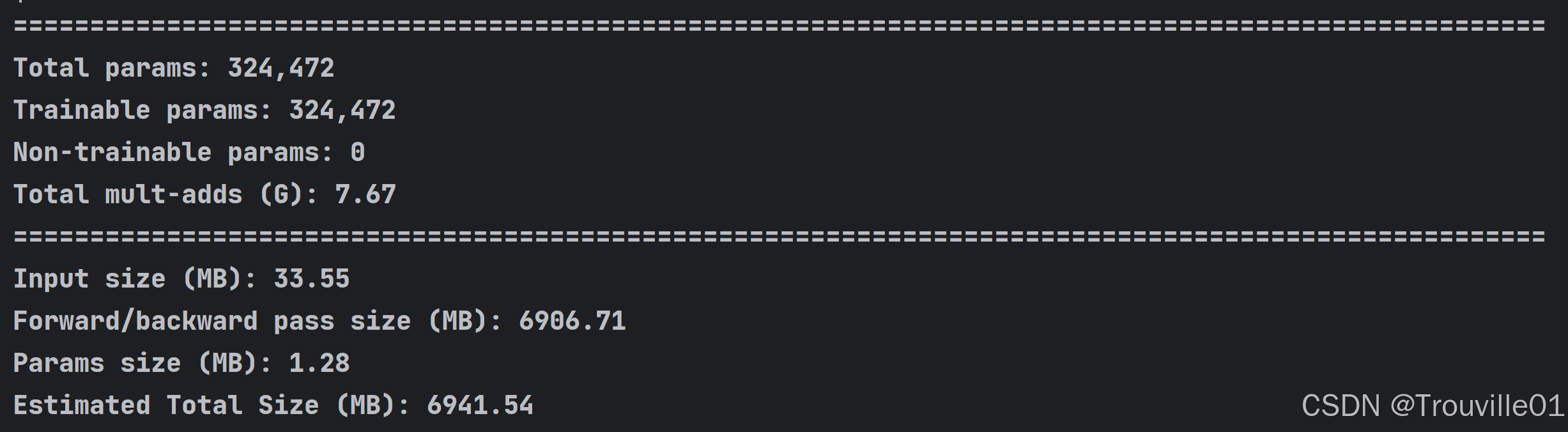
3.2 其次会打印模型的总参数量,参与训练的参数量以及不参与训练的参数量,以及总得计算量。
 下面详细解释一下上述指标的含义:
下面详细解释一下上述指标的含义:
1. 参数量
-
Total params: 324,472
模型中所有参数的总数,包括可训练参数和不可训练参数。 -
Trainable params: 324,472
模型中可参与梯度更新的参数(可以通过优化器更新)。 -
Non-trainable params: 0
模型中不参与梯度更新的参数,例如某些固定的权重或者冻结的层。
2. 计算量
- Total mult-adds (G): 7.67
总的乘加操作数量(即浮点运算次数,FLOPs)。这里的单位是 GFLOPs,表示 7.67×10⁹ 次运算。
计算量越大,模型推理和训练时间通常也会更长。
3. 内存占用
-
Input size (MB): 33.55
输入数据占用的显存大小,单位是 MB。这里根据输入张量的大小和数据类型(如float32)计算得出。 -
Forward/backward pass size (MB): 6906.71
在一次前向传播和反向传播过程中,中间激活值占用的显存大小。
这通常是显存消耗的主要部分,尤其是深层模型。 -
Params size (MB): 1.28
存储模型参数所需的显存大小,单位是 MB。
通常较小,因为参数数量有限。 -
Estimated Total Size (MB): 6941.54
模型运行时总的显存占用大小,等于以下三者的总和:Input size+Forward/backward pass size+Params sizeInput size+Forward/backward pass size+Params size
tips:所以可以根据Estimated Total Size来确定训练该网络所需要的最低显存,如果显存不够,最好减少batchsize或者减小输入tensor的大小,获取对网络模型进行精简。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











