







 OSTrack是2022年ECCV上提出的一种新的单流跟踪框架,它通过结合特征学习和关系建模,解决了传统两流跟踪器的局限。文章介绍了早期候选消除模块,该模块提高了模型的推理速度并提升了跟踪性能。与双流跟踪器相比,OSTrack能更好地提取面向目标的特征,并且由于使用预训练的ViT模型,收敛速度更快。
OSTrack是2022年ECCV上提出的一种新的单流跟踪框架,它通过结合特征学习和关系建模,解决了传统两流跟踪器的局限。文章介绍了早期候选消除模块,该模块提高了模型的推理速度并提升了跟踪性能。与双流跟踪器相比,OSTrack能更好地提取面向目标的特征,并且由于使用预训练的ViT模型,收敛速度更快。
论文链接
代码链接
发表在2022年 ECCV上的一篇文章
动机
目前流行的两流两阶段跟踪框架分别提取模板和搜索区域特征,然后进行关系建模,因此提取的特征缺乏对目标的感知,目标-背景辨别能力有限。为了解决上述问题,我们提出了一种新的单流跟踪(OSTrack)框架,通过将模板搜索图像对与双向信息流连接起来,将特征学习和关系建模统一起来。这样,通过相互引导,可以动态地提取具有鉴别性的面向目标的特征。
贡献
- 提出了一个简洁高效的单流的跟踪框架;
- 在Transformer的多头注意力机制中加入了,早期候选消除模块(Early Candidate
Elimination),从而加快了模型的推理速度 - 在许多基准上的大量实验结果表明,该跟踪器的性能明显优于最先进的算法。
跟踪pipeline
这里的pipeline的中文意思翻译成了管道,但是看了网上的帖子,这里翻译成主要解决方案
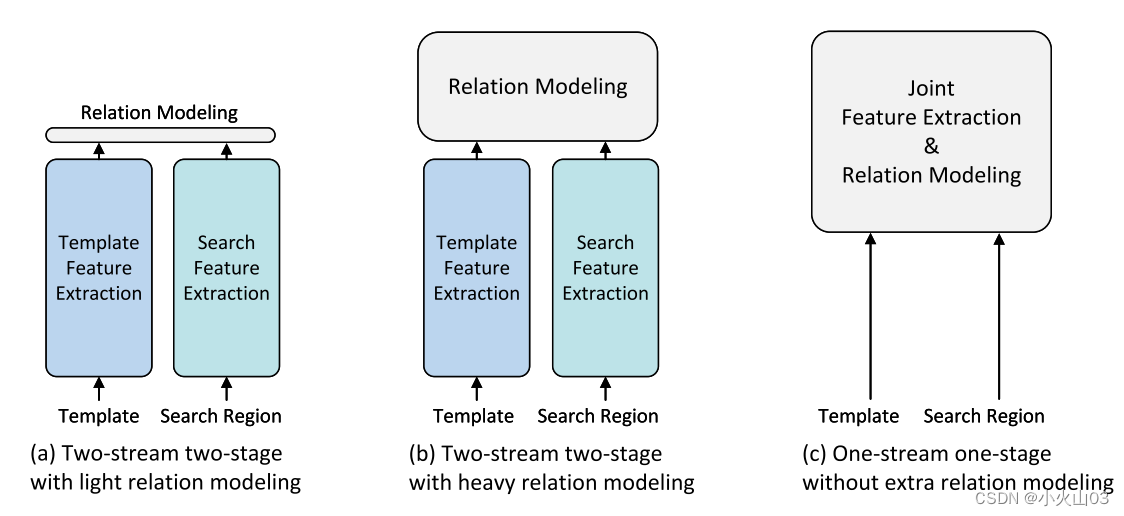
其中每个矩形高度表示模型的相对大小/尺寸
| 跟踪器 | 描述 |
|---|---|
| a | 早期的孪生跟踪器(SiamFC、SiamRPN)和鉴别跟踪器(DIMP、ATOM)属于这种类型,首先通过CNN提取模板和搜索区域的特征,然后再通过后续的关系建模网络来融合这些特征用于后续的任务 |
| b | 近几年为了更好的进行关系建模,提出了Transformer层,这个关系建模模块模型较大,支持双向的信息交互,代表论文有TransT、STARK。双重结构带来了性能的提升,但不可避免的降低了推理速度 |
| c | 我们首次将特征提取和关系建模无缝地结合成一个统一的pipeline。该方法在模板和搜索区域之间提供了自由的信息流,且计算量较小。它不仅通过相互引导生成面向目标的特征,而且在训练和测试时间上都是有效的。 |
网络结构
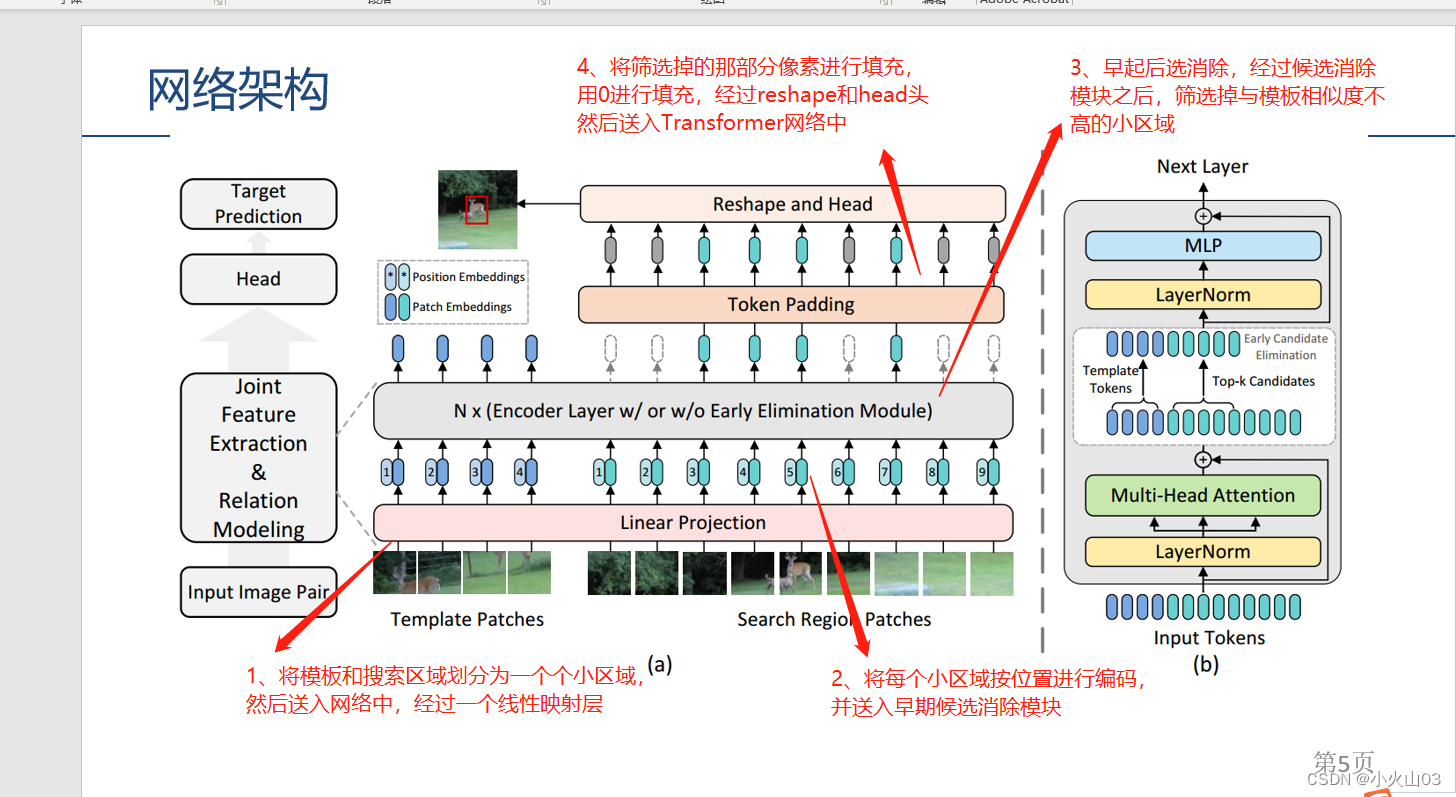 如有错误,请留言
如有错误,请留言
与双流跟踪器比较
- 以往的双流Transformer融合跟踪器均采用孪生框架,先分别提取模板和搜索区域的特征,只采用Transformer层对提取的特征进行融合。因此,这些方法提取的特征是不自适应的,可能会丢失一些判别信息,这是无法弥补的。相比之下,OSTrack在第一阶段直接将线性投影的模板和搜索区域图像拼接起来,将特征提取和关系建模无缝地结合在一起,通过模板和搜索区域的相互引导,可以提取出面向目标的特征。
- 以往的Transformer融合跟踪器只采用ImageNet预训练骨干网,Transformer层随机初始化,收敛速度变慢,而OSTrack得益于预训练的ViT模型,收敛速度更快。
- 单流框架为进一步提高模型性能和推理速度提供了识别和丢弃无用背景区域的可能性。
候选消除模块
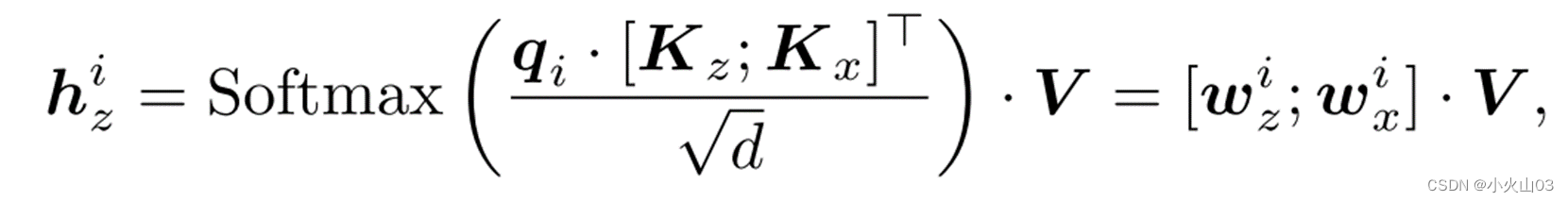
其中qi、Kz、Kx、V表示令牌hi z的查询向量,表示模板对应的键矩阵,表示搜索区域对应的键矩阵,表示值矩阵。注意权重
w
i
x
w^x_ {i}
wix决定了模板部分
h
z
i
h^i_ {z}
hzi与所有搜索区域标记(候选)之间的相似度。
w
i
x
w^x_ {i}
wix的第j个项(1≤j≤n, n为输入搜索区域令牌数)决定了
h
z
i
h^i_ {z}
hzi与第j个候选项的相似度。然而,当计算目标和每个候选对象之间的相似度时,输入模板通常包含引入噪声的背景区域。因此,与其将每个候选部件与所有模板部件的相似度相加,i = 1,…,Nz,我们取
w
x
φ
w^φ_ {x}
wxφ,其中φ =⌊Wz/ 2⌋+Wz·⌊Hz 2⌋(其中φ−th的token对应于原始模板图像的中间部分)为代表的相似度。这是相当合理的,因为中心模板部分已经通过自我注意聚合了足够的信息来表示目标。

在编码器层进行多头注意操作后,插入所提出的候选消除模块,如图网络结构中的 b所示。此外,记录所有剩余候选的原始顺序,以便在最后阶段恢复。候选恢复阶段,前面提到的候选剔除模块打乱了候选序列的原始顺序,使得候选序列不可能重新塑造为之前的feature map,因此我们将剩余的候选序列恢复到原始顺序,然后填充缺失的位置。由于丢弃的候选对象属于不相关的背景区域,因此不会影响分类和回归任务。换句话说,它们只是作为重塑操作的占位符。因此,我们首先恢复剩余候选项的顺序,然后在它们之间加零。
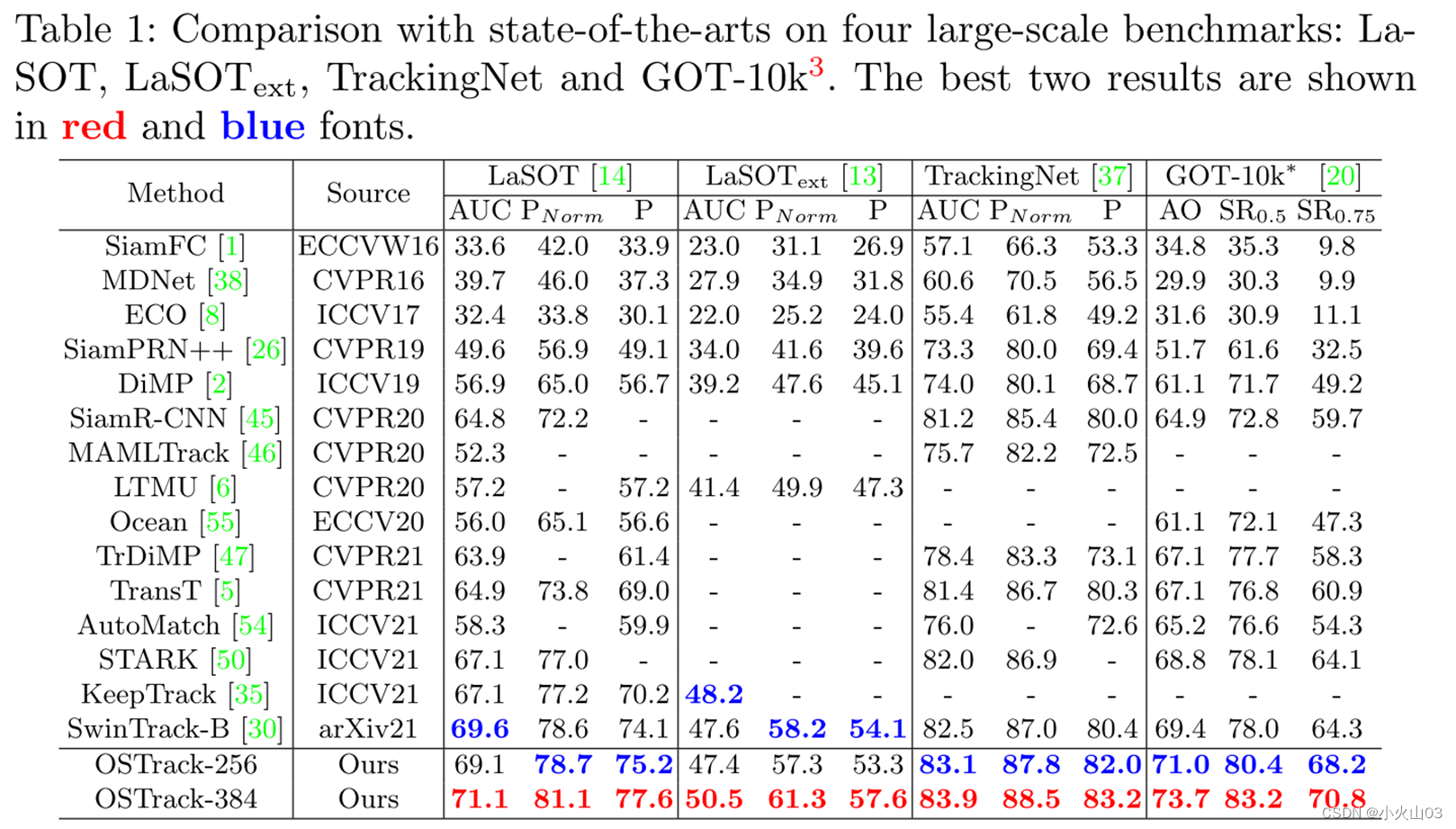
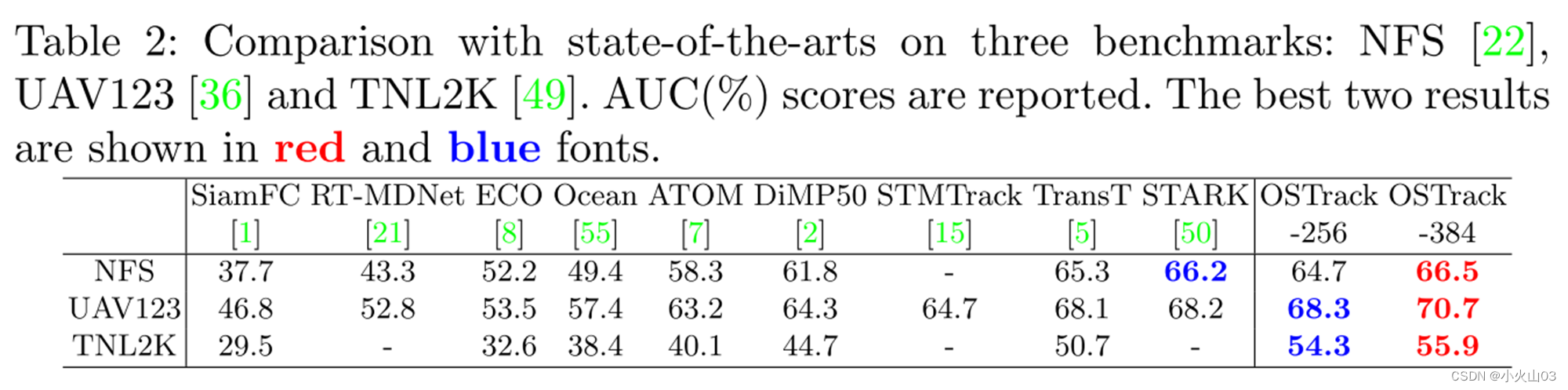
实验(简略)

















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









