







正则的三个应用场景
360前端星计划-第八课
主讲:王峰老师
正则表达式的创建和使用
- 创建正则表达式的两种方式
- 使用正则表达式字面量
const reg = /[a-z]\d+[a-z]/i;
优点:
简单方便
不需要考虑二次转义
缺点:
子内容无法重复使用
过长的正则导致可读性差
- 使用 RegExp 构造函数
const alphabet = '[a-z]';
const reg = new RegExp(`${alphabet}\\d+${alphabet}`, 'i');
优点:
子内容可以重复使用
可以通过控制子内容的粒度提高可读性
缺点:
二次转义的问题非常容易导致 bug
- 正则表达式的常见用法
RegExp.prototype.test()
const reg = /[a-z]\d+[a-z]/i;
reg.test('a1a'); // true
reg.test('1a1'); // false
reg.test(Symbol('a1a')); // TypeError
输出
要求输入字符串,如果输入的不是字符串类型,会尝试进行类型转换,转换失败会抛出 TypeError
输出
true 或者 false,表示匹配成功或失败
RegExp.prototype.source 和 RegExp.prototype.flags
const reg = /[a-z]\d+[a-z]/ig;
reg.source; // "[a-z]\d+[a-z]"返回当前正则表达式的模式文本的字符串
reg.flags; // "gi"es2015新增,返回当前正则表达式的修饰符的字符串,会对修饰符按照字母升序进行排序(gimsuy)
RegExp.prototype.exec() 和 String.prototype.match()
const reg = /[a-z]\d+[a-z]/i;
reg.exec('a1a'); // ["a1a", index: 0, input: "a1a", groups: undefined]
reg.exec('1a1'); // null
'a1a'.match(reg); // ["a1a", index: 0, input: "a1a", groups: undefined]
'1a1'.match(reg); // null
输入
RegExp.prototype.exec 要求输入字符串,遇到非字符串类型会尝试转换
String.prototype.match 要求输入正则表达式,遇到其它类型会先尝试转成字符串,再以字符串为 source 创建正则表达式
输出
匹配成功,返回匹配结果
匹配失败,返回 nul
const reg = /(a)/g;
reg.exec('a1a'); // ["a", "a", index: 0, input: "a1a", groups: undefined]
'a1a'.match(reg); // ["a", "a"]
当正则表达式含有 g 修饰符时,RegExp.prototype.exec 每次只返回一个匹配结果,数据格式和不含 g 修饰符相同。
String.prototype.match 会返回所有的匹配结果,数据格式会变为字符串数组。
注:由于 String.prototype.match 返回的数据格式不固定,因此大多数情况都建议使用 RegExp.prototype.exec
RegExp.prototype.lastIndex
const reg = /(a)/g;
const str = 'a1a';
reg.lastIndex; // 0
reg.exec('a1a'); // ["a", "a", index: 0, input: "a1a", groups: undefined]
reg.lastIndex; // 1
reg.exec('a1a'); // ["a", "a", index: 2, input: "a1a", groups: undefined]
reg.lastIndex; // 3
reg.exec('a1a'); // null
reg.lastIndex; // 0
当前正则表达式最后一次匹配成功的结束位置(也就是下一次匹配的开始位置)
注意:lastIndex 不会自己重置,只有当上一次匹配失败才会重置为 0 ,因此,当你需要反复使用同一个正则表达式的时候,请在每次匹配新的字符串之前重置 lastIndex!
String.prototype.replace()、String.prototype.search()、String.prototype.split()
'a1a'.replace(/a/, 'b'); // 'b1a'
'a1a'.replace(/a/g, 'b'); // 'b1b'
'a1a'.search(/a/); // 0
'a1a'.search(/a/g); // 0
'a1a'.split(/a/); // ["", "1", ""]
'a1a'.split(/a/g); // ["", "1", ""]
三个应用场景
- 正则与数值
1、数值判断不简单?
/[0-9]+/
缺点
不是全字符匹配,存在误判,如 /[0-9]+/.test(‘a1’) === true
[ ] 字符集,使用连字符 - 表示指定的字符范围,如果想要匹配连字符,需要挨着方括号放置,或进行转义 0-9 表示匹配从 0 到 9 的数字字符,常用的还有 a-z 匹配小写字母,\u4e00-\u9fa5 匹配汉字等 如果只是匹配数字,还可以使用字符集缩写 \d
+ 限定符,匹配一个或多个
/^\d+$/
缺点
不能匹配带符号的数值,如 +1,-2
不能匹配小数,如 3.14159
^ 匹配字符串开始位置,当结合 m 修饰符时,匹配某一行开始位置
$ 匹配字符串结束位置,当结合 m 修饰符时,匹配某一行结束位置
/^[+-]?\d+(\.\d+)?$/
缺点
不能匹配无整数部分的小数,如 .123
捕获组会带来额外的开销
() 圆括号内是一个子表达式,当圆括号不带任何修饰符时,表示同时创建一个捕获组
? 在正则中有多种含义,作为限定符时,表示匹配零到一个
\. 可以匹配除换行符之外的任意字符,当结合 s 修饰符时,可以匹配包括换行符在内的任意字符,当匹配小数点字符时需要转义
/^[+-]?(?:\d*\.)?\d+$/
缺点
不能匹配无小数部分的数值,如 2.
不能匹配科学计数法,如 1e2、3e-1、-2.e+4
**(? : )**不能匹配无小数部分的数值,如 2.
不能匹配科学计数法,如 1e2、3e-1、-2.e+4
创建一个非捕获组
* 限定符,匹配零个或多个
2、 完整的数值正则怎么写?
完整的数值token(这个 token 是 CSS 的 token)
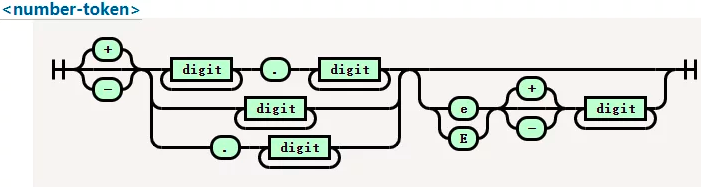
/^[+-]?(?:\d+\.?|\d*\.\d+)(?: e[+-]?\d+)?$/i
缺点
不能覆盖到16进制8进制等情况
| 用来创建分支,当位于圆括号内时,表示子表达式的分支条件,当位于圆括号外时,表示整个正则表达式的分支条件
i 表示匹配时忽略大小写,在这个例子中用于匹配科学计数法的 e,去掉 i 修饰符需要把 e 改为 [eE]
3、 用正则处理数值?
数值的解析
const reg = /[+-]?(?:\d*\.)?\d+(?:e[+-]?\d+)?(?=px|\s|$)/gi;
function execNumberList(str) {
reg.lastIndex = 0;
let exec = reg.exec(str);
const result = [];
while (exec) {
result.push(parseFloat(exec[0]));
exec = reg.exec(str);
}
return result;
}
console.log(execNumberList('1.0px .2px -3px +4e1px')); // [1, 0.2, -3, 40]
console.log(execNumberList('+1.0px -0.2px 3e-1px')); // [1, -0.2, 0.3]
console.log(execNumberList('1px 0')); // [1, 0]
console.log(execNumberList('-1e+1px')); // [-10]
(?=expression) 正向肯定环视 / 顺序肯定环视 / 先行断言,用于匹配符合条件的位置
类似的语法还有:
(?!expression) 正向否定环视 / 顺序否定环视 / 先行否定断言
(?<=expression) 反向肯定环视 / 逆序肯定环视 / 后行断言,es2018 新增
(?<!expression) 反向否定环视 / 逆序否定环视 / 后行否定断言,es2018 新增
g修饰符,表示全局匹配,用于取出目标字符串中所有符合条件的结果
需要注意的点
按照 CSS 规范,只有数值为 0 才可以省略单位,这种情况没有必要靠正则来过滤
这个例子中只验证了 px 单位,实际还存在 pt、em、vw 等单位,并且没有考虑百分比的情况
实际工作中,要根据需求追加处理逻辑
数值转货币格式
const reg = /(\d)(?=(\d{3})+(,|$))/g;
function formatCurrency(str) {
return str.replace(reg, '$1,');
}
console.log(formatCurrency('1')); // 1
console.log(formatCurrency('123')); // 123
console.log(formatCurrency('12345678')); // 12,345,678
{n} 限定符,表示重复 n 次,n 必须是非负整数
类似的语法还有:
{n, m} 表示重复 n 到 m 次,n 和 m 都必须是非负整数,且 n <= m
{n,} 表示重复 n 次以上
$n 用于 replace 的字符串中,表示第 n 个捕获组,n 可以从 1 到 9
$& 表示本次完整的匹配,所以这段代码还可以改写为:
const reg = /\d(?=(?:\d{3})+(?:,|$))/g;
function formatCurrency(str) {
return str.replace(reg, '$&,');
}
在 es2018 以上的环境,还可以使用反向环视
const reg = /(?<=\d)(?=(?:\d{3})+(?:,|$))/g;
function formatCurrency(str) {
return str.replace(reg, ',');
}
其它注意事项
环视中的圆括号也会生成捕获组,所以都要采用 (? : ) 的非捕获组形式
- 正则与颜色
1、颜色有多少种表示方式
16进制表示法
const hex = '[0-9a-fA-F]';
const reg = new RegExp(`^(?:#${hex}{6}|#${hex}{8}|#${hex}{3,4})$`);
其它注意事项
也可以使用 i 修饰符来匹配大小写,i 修饰符和 a-fA-F 要根据实际需求来做取舍
rgb/rgba 表示法
const num = '[+-]?(?:\\d*\\.)?\\d+(?:e[+-]?\\d+)?';
const comma = '\\s*,\\s*';
const reg = new RegExp(`rgba?\\(\\s*${num}(%?)(?:${comma}${num}\\1){2}(?:${comma}${num}%?)?\\s*\\)`);
\n 反向引用,表示引用第 n 个捕获组,由于 r/g/b 必须同时为数值或百分比,所以 %? 只需要捕获一次,用 \1 来引用
\s 字符集缩写,用于匹配空白
注意
按照规范,rgb(r,g,b,a) 和 rgba(r,g,b) 也是合法的
r/g/b 的值应该是 0~255 的整数,但是溢出或小数并不会报错
当捕获组内的内容是可选的时候,一定要把问号写在捕获组内
如果可选内容的圆括号不可省略,如(a|b|c)?,应该多嵌套一层:((?:a|b|c)?)
2、用正则处理颜色
16进制颜色的优化
const hex = '[0-9a-z]';
const hexReg = new RegExp(`^#(?<r>${hex})\\k<r>(?<g>${hex})\\k<g>(?<b>${hex})\\k<b>(?<a>${hex}?)\\k<a>$`, 'i');
function shortenColor(str) {
return str.replace(hexReg, '#$<r>$<g>$<b>$<a>');
}
console.log(shortenColor('#336600')); // '#360'
console.log(shortenColor('#19b955')); // '#19b955'
console.log(shortenColor('#33660000')); // '#3600'
(?< key>)es2018 新增,具名捕获组反向引用时的语法为 \k< key>
在 replace 中,使用 $ 来访问具名捕获组;当应用 exec 时,具名捕获组可以通过 execResult.groups[key] 访问
- 正则与URL
1、完整的 URL 规范(scheme 我们只匹配 http 和 https ,忽略 userinfo 部分)

const protocol = '(?<protocol>https?:)';
const host = '(?<host>(?<hostname>[^/#?:]+)(?::(?<port>\\d+))?)';
const path = '(?<pathname>(?:\\/[^/#?]+)*\\/?)';
const search = '(?<search>(?:\\?[^#]*)?)';
const hash = '(?<hash>(?:#.*)?)';
const reg = new RegExp(`^${protocol}\/\/${host}${path}${search}${hash}$`);
function execURL(url) {
const result = reg.exec(url);
if (result) {
result.groups.port = result.groups.port || '';
return result.groups;
}
return {
protocol: '', host: '', hostname: '', port: '',
pathname: '', search: '', hash: '',
};
}
console.log(execURL('https://www.360.cn'));
console.log(execURL('http://localhost:8080/?#'));
console.log(execURL('https://image.so.com/view?q=360&src=srp#id=9e17bd&sn=0'));
console.log(execURL('this is not a url'));
注意事项
port 捕获组可能为 undefined
要考虑解析失败的情形
2、用正则解析 search 和 hash
function execUrlParams(str) {
str = str.replace(/^[#?&]/, '');
const result = {};
//重要:正则表达式如果可能匹配到空字符串,极有可能造成死循环
if (!str) {
return result;
}
const reg = /(?:^|&)([^&=]*)=?([^&]*?)(?=&|$)/y;
let exec = reg.exec(str);
while (exec) {
result[exec[1]] = exec[2];
exec = reg.exec(str);
}
return result;
}
console.log(execUrlParams('#')); // { }
console.log(execUrlParams('##')); // { '#': '' }
console.log(execUrlParams('?q=360&src=srp')); // { q: '360', src: 'srp' }
console.log(execUrlParams('test=a=b=c&&==&a=')); // { test: 'a=b=c', '': '=', a: '' }
*? ? 可以跟在任何限定符之后,表示非贪婪模式(注意:这个例子其实不太恰当,使用贪婪模式效果是一样的)
y es6 新增,粘连修饰符,和 g 修饰符类似,也是全局匹配。区别在于:1.y 修饰符每次匹配的结果必须是连续的 ;2.y 修饰符在 match 时只会返回第一个匹配结果
怎样用好正则表达式?
明确需求
考虑全面
反复测试















 940
940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









