









Zookeeper
一、定义
1、官网
2、简介
ZooKeeper允许分布式进程通过数据寄存器(我们称这些寄存器为znodes)的共享分层名称空间相互协调,就像文件系统一样。与普通文件系统不同,ZooKeeper向其客户端提供高吞吐量,低延迟,高可用性,对znode的严格有序访问。可靠性方面阻止了它成为大型系统中的单点故障。它严格的排序允许在客户端实现复杂的同步原语。
ZooKeeper提供的名称空间与标准文件系统的名称空间非常相似。名称是由斜杠(“ /”)分隔的一系列路径元素。ZooKeeper名称空间中的每个znode均由路径标识。每个znode都有一个父对象,其路径是znode的前缀,元素少一个;此规则的例外是root(“ /”),它没有父项。此外,与标准文件系统完全一样,如果znode有子节点,则无法删除它。
有四种类型的znode:
-
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
-
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
ZooKeeper与标准文件系统之间的主要区别在于,每个znode都可以与之关联数据(每个文件也可以是目录,反之亦然),而znode则限于它们可以拥有的数据量。ZooKeeper旨在存储协调数据:状态信息,配置,位置信息等。ZooKeeper具有1M的内置完整性检查,以防止将其用作大型数据存储,但通常用于存储小得多的数据。
3、原理
服务本身是在组成该服务的一组计算机上复制的。这些机器在持久性存储中维护数据树的内存中映像以及事务日志和快照。因为数据保存在内存中,所以ZooKeeper能够获得很高的吞吐量和较低的等待时间。内存数据库的缺点是ZooKeeper可以管理的数据库大小受内存限制。此限制是保持znodes中存储的数据量较小的另一个原因。
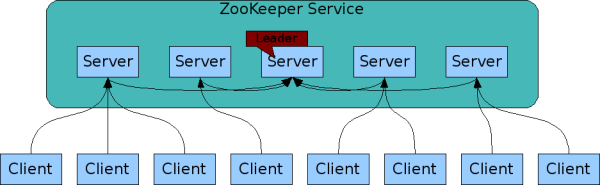
组成ZooKeeper服务的服务器都必须彼此了解。只要大多数服务器可用,ZooKeeper服务将可用。客户端还必须知道服务器列表。
客户端仅连接到单个ZooKeeper服务器。**客户端维护一个TCP连接,通过该连接可以发送请求,获取响应,获取监视事件以及发送心跳。**如果与服务器的TCP连接断开,则客户端将连接到其他服务器。当客户端首次连接到ZooKeeper服务时,第一台ZooKeeper服务器将为该客户端设置会话。如果客户端需要连接到另一台服务器,则该会话将与新服务器重新建立。
ZooKeeper客户端发送的读取请求在客户端连接到的ZooKeeper服务器上本地处理。如果读取请求在znode上注册了一个监视,则该监视也会在ZooKeeper服务器上本地跟踪。写请求被转发到其他ZooKeeper服务器,并在产生响应之前经过共识。同步请求也会转发到另一台服务器,但实际上并没有达成共识。因此,读取请求的吞吐量随服务器数量成比例增加,而写入请求的吞吐量随服务器数量而减小。
订单对ZooKeeper非常重要;几乎与强迫症有关。所有更新均已全部订购。ZooKeeper实际上会为每个更新标记一个可反映此顺序的数字。我们将此数字称为zxid(ZooKeeper交易ID)。每个更新将具有唯一的zxid。阅读(和观看)的顺序与更新有关。读取响应将标记有为读取服务的服务器处理的最后zxid。
4、leader选举
1、Zookeeper 节点状态
- LOOKING:寻找 Leader 状态,处于该状态需要进入选举流程
- LEADING:领导者状态,处于该状态的节点说明是角色已经是 Leader
- FOLLOWING:跟随者状态,表示 Leader 已经选举出来,当前节点角色是 follower
- OBSERVER:观察者状态,表明当前节点角色是 observer
2、事务ID
ZooKeeper 状态的每次变化都接收一个 ZXID(ZooKeeper 事务 id)形式的标记。ZXID 是一个 64 位的数字,由 Leader 统一分配,全局唯一,不断递增。ZXID 展示了所有的ZooKeeper 的变更顺序。每次变更会有一个唯一的 zxid,如果 zxid1 小于 zxid2 说明 zxid1 在 zxid2 之前发生。
3、Zookeeper 集群初始化启动时 Leader 选举
若进行 Leader 选举,则至少需要两台机器,这里选取 3 台机器组成的服务器集群为例。初始化启动期间 Leader 选举流程如下图所示。

在集群初始化阶段,当有一台服务器 ZK1 启动时,其单独无法进行和完成 Leader 选举,当第二台服务器 ZK2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader 选举过程。选举过程开始,过程如下:
(1) 每个Server发出一个投票。由于是初始情况,ZK1 和 ZK2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID,使用(myid, ZXID)来表示,此时 ZK1 的投票为(1, 0),ZK2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自 LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下
-
优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
-
如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader服务器。
对于 ZK1 而言,它的投票是(1, 0),接收 ZK2 的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 myid,此时 ZK2 的 myid 最大,于是 ZK2 胜。ZK1 更新自己的投票为(2, 0),并将投票重新发送给 ZK2。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 ZK1、ZK2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出 ZK2 作为Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。当新的 Zookeeper 节点 ZK3 启动时,发现已经有 Leader 了,不再选举,直接将直接的状态从 LOOKING 改为 FOLLOWING。
4、Zookeeper 集群运行期间 Leader 重新选
在 Zookeeper 运行期间,如果 Leader 节点挂了,那么整个 Zookeeper 集群将暂停对外服务,进入新一轮Leader选举。假设正在运行的有 ZK1、ZK2、ZK3 三台服务器,当前 Leader 是 ZK2,若某一时刻 Leader 挂了,此时便开始 Leader 选举。选举过程如下图所示。
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会讲自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个Server会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 ZK1 的 ZXID 为 124,ZK3 的 ZXID 为 123;在第一轮投票中,ZK1 和 ZK3 都会投自己,产生投票(1, 124),(3, 123),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同,由于 ZK1 事务 ID 大,ZK1 将会成为 Leader。
(5) 统计投票。与启动时过程相同。
(6) 改变服务器的状态。与启动时过程相同。
二、实践
1、在Linux上安装Zookeeper服务器
注:我用的是docker下载的zookeeper
1、拉取zookeeper
docker zookeeper中查看docker容器中zookeeper
docker pull zookeeper:3.4.9
使用:
docker images #查看拉下来的镜像

运行zookeeper镜像:
docker run --name some-zookeeper p 2181:2181 --restart always -d zookeeper

启动成功
进入容器:
docker exec -it 2ca11e0fd50b(容器id) /bin/bash



这几个命令:
#启动zk服务
bin/zkServer.sh start
#进入zk自带的客户端
bin/zkCli.sh
#查看zk服务状态
bin/zkServer.sh status

进入zkCli:

查询znode
ls /

里面的节点是我自前自己测试过的
2、客户端连接
jar包
<!--这是spring结合zookeeper的starter包,但里面的版本和安装的zookeeper服务端不匹配需要更换版本-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
<exclusions>
<!--先排除自带的zookeeper3.5.3-->
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.9</version>
</dependency>
yml配置
server:
port: 8003
spring:
application:
name: cloud-provider-payment
cloud:
zookeeper:
connect-string: ip:2181 # 默认ip写安装zookeeper服务的ip主机,默认为localhost:2181
主启动类
/**
* ClassName: PaymentMain8004
* Package: com.zpc.springcloud
* Description:
*
* @Date: 2020/11/28 11:02
* @Author:zpc@qq.com
*/
@SpringBootApplication
@EnableDiscoveryClient
public class PaymentMain8003 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain8003.class,args);
}
}
测试
/**
* ClassName: PaymentController
* Package: com.zpc.springcloud.controller
* Description:
*
* @Date: 2020/11/28 11:01
* @Author:zpc@qq.com
*/
@RestController
@Slf4j
public class PaymentController {
@Value("${server.port}")
private String port;
@GetMapping("/payment/zk")
public String paymentZK(){
return "springcloud with zookeeper serverport:"+port+"\t"+ UUID.randomUUID().toString();
}
}
三、调用















 1744
1744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









