






1 Introduction
之前的网络比如FCN或者Deep Lab v1都存在从小的分辨率图像往大了进行上采样,那么问题就来了,下采样是必要的嘛?话有一些方法提供多个重构版本(multiple rescaled versions of the image)再进行联合求解预测,这样的操作是必要的嘛?
本文提出一种CNN模型,不会丢失分辨率,也不会联合多个预测去得到最后的分割图。这个模型是基于空洞卷积的,它在保证分辨率的情况下(就是不进行下采样),能够极大的扩大感受野(感受野的大小可以决定单个像素点能够参考周围的多少信息从而决定自身label)。
工作的另一部分是。在分割的基础上,对于分割后的类别预测的准确性也做了一些评估,(意思是:图像的每个部分分割出来了,可是明明是沙发,却预测成了椅子)。
最后,现在的网络越来越复杂,在受控的情况下,调节一些层,来观察哪些component促进或者阻碍了密集预测的准确性。结果发现The result is an initial prediction module that is both simpler and more accurate than prior adaptations,(发现最开始使用的简单模型比调整过后的模型更简单更加准确,也就是优化不成功)。
使用简化的预测模块,通过对Pascal VOC 2012数据集的实验来评估所提出的上下文网络。实验表明,将上下文模块插入现有的语义分割体系结构中,能够有效的提高语义分割的准确性。
2 空洞卷积(dilated convolutions)
空洞卷积的内容在知乎有详细的解释,请自行学习。这里粘贴一个简单的例子:

(a)图对应3x3的1-dilated conv,和普通的卷积操作一样
(b)图对应3x3的2-dilated conv,实际的卷积kernel size还是3x3,但是空洞为1,也就是对于一个7x7的图像patch,只有9个红色的点和3x3的kernel发生卷积操作,其余的点略过。也可以理解为kernel的size为7x7,但是只有图中的9个点的权重不为0,其余都为0。 可以看到虽然kernel size只有3x3,但是这个卷积的感受野已经增大到了7x7(如果考虑到这个2-dilated conv的前一层是一个1-dilated conv的话,那么每个红点就是1-dilated的卷积输出,所以感受野为3x3,所以1-dilated和2-dilated合起来就能达到7x7的conv)
(c)图是4-dilated conv操作,同理跟在两个1-dilated和2-dilated conv的后面,能达到15x15的感受野。对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野,也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
注:这一段是抄别人的,讲的很清楚,忘了抄的谁的,所以空洞卷积部分没有看原论文。
我们的文章开发了一种新的卷积网络架构,大量的使用空洞卷积来进行多尺度的上下文聚合。
3 多尺度图像聚合
该模块具有C个feature maps输入和C个feature maps,由于输出和输入保持一致,所以可以插入任何一个现存的密集预测网络结果当中(个人理解为,在原有的两个卷积或者其他之间可以随意的插入这个模块,而保证网络仍然可以持续运行)。
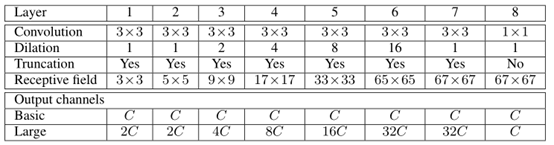
一共是8层,相关参数见图,Dilation表示的是空洞卷积的步长(Dilation等于1表示正常的卷积),也有用rate表示的,Truncation表示的是阶段,原文中说的是在卷积后添加一个max(·, 0)层,Receptive field是每层输出后的感受野大小。6层之后,分辨率提的差不多很高了,就没有再提高了。
开始尝试的时候我们是失败的,因为我们采用的是和常卷积网络一样的随机初始化方式,但是结果表明对于context module,这种方式是没用的,我们重新定义了初始化方式:
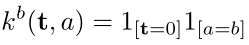
其中a是输入feature map的索引,b是输出feature map的索引。先举一个例子说明这个初始化方式,假设t=0(这个我也没理解是个什么玩意,先把它当作永远的0就好),输入的是a=1通道,输出的是b=2通道,则则这个通道对应的初始化权值为:k^2 (0,1)= 10=0,即用0初始化,而k^1 (0,1)= 11=1就是用1初始化,我们可以看到,除了在相同的输入和输出索引的时候为等价传递,其余的就不进行传递了。
这是一种确定的初始化方式(每次初始化的参数都一样),最近被提倡用于RNN。有人担忧这样子的初始化方式,可能使得这个模块陷入一种模式,在这种模式下,模块只进行信息的传递而不进行参数的更新(不对模块参数进行优化),结果表明,这种担忧是多余的,相反,反向传播的时候,它很有效的收集了上下文信息。提高了后面分割图的准确性。
我们的网络需要很少的参数量就可以提升网络的性能。约为64 * C^2,具体算法就是,3 * 3 * C的卷积核7个,1 * 1 * C的卷积核1个,然后生成的feature maps是C通道的,所以是(3 * 3 * C * 7 + 1 * 1 * C * 1) * C = 64 C^2。这是根据上述表格算出来的basic的参数量。
我们注意到下面还有一行,Larger就是我们做的更多的探索,注意上一层的Output Channel就是下一层的输入Channel,所以在前面7层通道时都是单调不减的,在最后一层,使用1132C的C个卷积核,将它从32C通道,将到了C通道。对于这个探索,我们的初始化方式为:
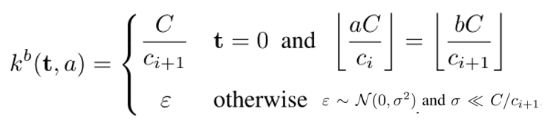
其中ci和ci+1是连续的两个层的通道数,使用epsilon这个随机的噪声,打破了共用同一个前面的特征图的两个层之间的紧密关系。
4 Front-End 前端(整体框架)
请先阅读FCN网络以及Deep Lab v1网络,了解框图即可。
我们为了和上述两者对比,也采用了输入为3通道,输出为21通道(20个类别 + 1个背景),在去掉了VGG16的最后两个池化层,在FCN中就是因为这个池化导致图像变成了1/32的大小,分辨率太低了,而在DeepLab v1中,它是采用了将Pooling的stride变成了1,从而得到了1/8的分辨率图,同时里面应用了部分空洞卷积,但我们这个模型,觉得Pooling是CNN进行分类的时候的,所以没必要放在分割的任务中,所以就直接取消了,同时在中间层进行Padding(边缘填充)对于分割也是没有意义的,所以也去掉了。但是我们直接在一开始,就通过reflection padding的方式进行了图像的扩充(个人理解为类似于U-Net的填充方式)。
我们采用Pascal VOC 2012数据集(还用了别人增强后的一部分数据),没有用Pascal VOC 2012的验证集,而是将准备用于训练的一部分数据提前拿出来当作验证集。SGD、lr=0.001、momentum=0.9、epoch=60K。


我们的模型很牛逼,别问为啥,就是牛逼,比DeepLab v1 + CRF(一种由HMM推得的随机场,加了CRF以后的DeepLab的效果更好,但就这,还是没我们的Context Module牛逼)。
5 experiments
我们又做了一个试验,第一阶段,我们一起在VOC-2012图像和微软COCO图像上进行了训练。在第二阶段,我们只在VOC-2012图像上微调网络。
该模型的前端模块在VOC-2012验证集上达到69.8%的平均IoU,在测试集上达到71.3%的平均IoU。请注意,这种级别的准确性是由前端单独实现的,没有上下文模块或结构化预测。我们再次将这种高准确率归因于去除了最初为图像分类而提出的残留成分(池化和中间层的padding)。
最后又在自身的Front-End里面插入了basic和larger上下文模块,以及在最后添加了CRF-RNN(这个还不懂,反正就是可以提升准确率的),对比结果如下:

反正就是越来越牛逼。
6 结论
删掉对于像素级预测没用的结构,利用空洞卷积,以及basic和larger Context Network,提升了分割的准确率,再加上CRF-RNN就更加厉害了。















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









