







Multi-scale Context Aggregation By Dilated Convolutions
摘要
由于原先的卷积网络都是用于图像识别的,而对于语义分割等密度预测问题不同于图像识别。
通过该扩展卷积,可以聚合多尺度上下文信息,同时不丢失分辨率。该结构的膨胀卷积可以使感受野指数级上升而不损失分辨率。
简介
语义分割的挑战性在于他需要结合像素级的准确性和多尺度上下文推理。在图像分类任务中可以通过降采样和池化降低分辨率,从而获得全局预测;而密度预测任务中需要采用全分辨率。
在调节流量预测问题中的多尺度推理和全分辨率密度预测时,存在两种路径。一种时采用重复上卷积,从而恢复丢失的分辨率,同时从下采样层获取全局视野。第二种则是提供了多个缩放版本的图像作为输入,并且将对应预测值进行组合。
膨胀卷积层
F
:
Z
2
→
R
F:\mathbb{Z}^2\rightarrow\mathbb{R}
F:Z2→R是一个离散函数。令
Ω
r
=
−
[
−
r
,
r
]
2
∩
Z
2
\Omega_r=-[-r,r]^2\cap\mathbb{Z}^2
Ωr=−[−r,r]2∩Z2,并使
k
:
Ω
r
→
R
k:\Omega_r\rightarrow\mathbb{R}
k:Ωr→R作为一个size为
(
2
r
+
1
)
2
(2r+1)^2
(2r+1)2的离散滤波器。则离散卷积操作可定义为:
(
F
∗
k
)
(
p
)
=
∑
s
+
t
=
p
F
(
s
)
k
(
t
)
(F*k)(p)=\sum_{s+t=p}F(s)k(t)
(F∗k)(p)=s+t=p∑F(s)k(t)
当存在膨胀因子时,则可定义为:
(
F
∗
l
k
)
(
p
)
=
∑
s
+
l
t
=
p
F
(
s
)
k
(
t
)
(F*_lk)(p)=\sum_{s+lt=p}F(s)k(t)
(F∗lk)(p)=s+lt=p∑F(s)k(t)
在该篇论文所给出的结构是使得
F
0
,
F
1
,
⋯
,
F
n
−
1
:
Z
2
→
R
F_0,F_1,\cdots,F_{n-1}:\mathbb{Z}^2\rightarrow\mathbb{R}
F0,F1,⋯,Fn−1:Z2→R为离散函数,
k
0
,
k
1
,
⋯
,
k
n
−
2
:
Ω
1
→
R
k_0,k_1,\cdots,k_{n-2}:\Omega_1\rightarrow \mathbb{R}
k0,k1,⋯,kn−2:Ω1→R是
3
×
3
3\times 3
3×3滤波器,则有:
F
i
+
1
=
F
i
∗
2
i
k
i
f
o
r
i
=
0
,
1
,
⋯
,
n
−
2
F_{i+1}=F_i*_{2i}k_i\qquad for\quad i=0,1,\cdots,n-2
Fi+1=Fi∗2ikifori=0,1,⋯,n−2

从而可以得到 F i + 1 F_{i+1} Fi+1感受野的大小为 ( 2 i + 2 − 1 ) × ( 2 i + 2 − 1 ) (2^{i+2}-1)\times (2^{i+2}-1) (2i+2−1)×(2i+2−1)。
多维度上下文聚合
上下文模块利用聚合多维度上下文信息从而增强密度预测效果,该模块中可以将 C C C特征图作为输入, C C C特征图作为输出。
上下文模块基本结构

模块拥有 7 7 7层,每层中拥有 3 × 3 3\times 3 3×3的不同膨胀因子的卷积,膨胀因子分别为 1 , 1 , 2 , 4 , 8 , 16 , 1 1,1,2,4,8,16,1 1,1,2,4,8,16,1。严格说,应该是前两维度是 3 × 3 × C 3\times 3 \times C 3×3×C的膨胀卷积,每个卷积后面都跟这一个单点 m a x ( ⋅ , 0 ) max(\cdot,0) max(⋅,0),最后一层是 1 × 1 × C 1\times 1\times C 1×1×C的卷积,用于输出。
实验
在论文的实验中,前端为上下文网络提供了 64 × 64 64\times 64 64×64分辨率的特征图输入,并在第6层后停止了指数膨胀。
在实验过程中,实验者发现利用随机分布进行初始化对上下文模块效果并不好,故提出了以下方法:
❓
k
b
(
t
,
a
)
=
1
[
t
=
0
]
1
[
a
=
b
]
k^b(\mathbf{t},a)=1_{[\mathbf{t}=0]}1_{[a=b]}
kb(t,a)=1[t=0]1[a=b]
其中
a
a
a是输入特征图的index,
b
b
b是输出特征图的index。
该网络中的总参数量约为 64 C 2 64C^2 64C2。
在对初始方案进行推广后,从而考虑不同层特征的映射数量:
k
b
(
t
,
a
)
=
{
C
c
i
+
1
t
=
0
a
n
d
⌊
a
C
c
i
⌋
=
⌊
b
C
c
i
+
1
⌋
ϵ
o
t
h
e
r
w
i
s
e
k^b(\mathbf{t},a)=\begin{cases} \frac{C}{c_{i+1}}\quad\mathbf{t}=0\quad and\quad \lfloor\frac{aC}{c_i}\rfloor=\lfloor\frac{bC}{c_{i+1}}\rfloor\\ \epsilon\quad otherwise \end{cases}
kb(t,a)={ci+1Ct=0and⌊ciaC⌋=⌊ci+1bC⌋ϵotherwise
其中
ϵ
N
(
0
,
σ
2
)
\epsilon~\mathcal{N}(0,\sigma^2)
ϵ N(0,σ2),
σ
≪
C
/
c
i
+
1
\sigma\ll C/c_{i+1}
σ≪C/ci+1
前端
实验者设计了一个前端预测模块,将彩图作为输入,并且输出channel C = 21 C=21 C=21。实验采用了VGG-16网络进行密度预测并且移除了最后两个池化和striding层,每去除一个,后续层中的卷积就被放大2倍,则最终被放大4倍。这样可以使得获得更高分辨率的输出,即上文所提到的 64 × 64 64\times 64 64×64。在实验中,还使用了反射填充(reflection padding)。
在实验中,实验者去除了池化层和striding层等对密度预测不利的结构,从而使得准确率得到了提高。同时实验还删除了对中间特征图的填充。
训练中使用了一个mini-batch是14的SGD,学习率为 1 0 − 3 10^{-3} 10−3,动量为0.9,训练过程中经过了60K次的迭代。
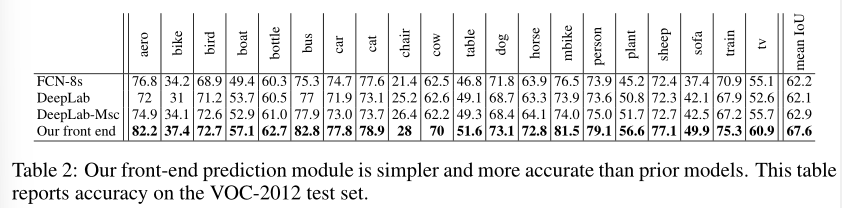
实验者简化后的前端较FCN-8s和DeepLab网络在测试集上提高了5个百分点。
实验
仅用前端
实验使用了Caffe库。在仅使用前端的情况下,使用VOC-2012数据集和COCO数据集,采用mini-batch大小为14的SGD,动量为0.9,100K次迭代, 1 0 − 3 10^{-3} 10−3的学习率,以及40K的后续迭代,学习率为 1 0 − 4 10^{-4} 10−4。
在第二阶段,对网络进行了微调并仅在VOC-2012数据集上进行测试。微调后,迭代次数是50K次,学习率是 1 0 − 5 10^{-5} 10−5,同时验证机没有用于训练。
上下文聚合模块
















 458
458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









