






c++17引入了并行算法函数
-
std::reduce(执行策略, first, last, init, binary_op)
应用binary_op到范围[first,last]的元素,init是返回结果的初始值
头文件#include- 使用
#include <iostream> #include <vector> #include <numeric> using namespace std; int main() { vector v ={4,3,2,1}; //元素相乘 int res = reduce(v.begin(), v.end(), 1, std::multiplies{}); //相加int res = reduce(v.begin(), v.end(), 0, std::plus{}); cout<<res<<endl; return 0; } - 不会改变容器中的值
#include <iostream> #include <vector> #include <numeric> using namespace std; int main() { vector<int> v = {4,3,2,1}; //lambda表达式需要两个参数:累计值、当前值 int res = reduce(v.begin(), v.end(), 1, [&](int acc, int x) { x = x*2; return acc * x; }); cout << res << endl;//8*6*4*2 for(auto vi:v) { cout<<vi<<endl;//4 3 2 1 } return 0; }
- 使用
-
3种执行策略
头文件- 顺序执行,不并行 sequenced_policy
- 并行策略,如果有共享资源要注意线程间的同步 parallel_policy
- 非顺序并行策略,连同步不允许 parallel_unsequenced_policy
- 具体使用:三个策略分别对应对象std::execution::seq、std::execution::par、std::execution::par_unseq
-
transform_reduce(策略, first, last, init, binary_op, unary_op)
#include <vector> #include <iostream> #include <numeric> using namespace std; int main() { vector x = {1, 2, 3}; vector y = {4, 5, 6}; int res = transform_reduce( x.begin(), x.end(), y.begin(), 0, [](int a, int b){return a+b;}, [](int x, int y){return x*y;} ); cout<<res<<endl;//32 /* int res = transform_reduce( x.begin(), x.end(), 0, [](int a, int b){return a+b;}, [](int x){return 3*x;} ); */ } -
{}是非强制转换,如果转换会丢失精度,那么就报错
int(3.14f)不报错,int{3.14f}会报错 -
POD类型不会被初始化为0,需要写上{0}
int、float、double、void*、Object*以及它们组成的类,被称作POD类型
int m{0} 等价于int m{} -
拷贝赋值的写法
A &operator=(A const &other) { //析构现有的,以免浅拷贝 this->~A(); //placement new调用拷贝构造 来重新构造 new (this) A(other); return *this; }
如果写了移动赋值函数,可以省略拷贝赋值函数
-
整数或者枚举类型可以作为模板参数
//这里的N是编译器常量,不同的N会单独生成一份代码 template<int N> void fun() { cout<<N<<endl; } int main() { fun<3>();//输出3 return 0; }enum Color {red,black,}; template <Color c> void fun() { cout<<c<<endl; } int main() { constexpr Color c1 = Color::red; fun<c1>(); } -
条件编译
例子:写一个模板参数debug,if(debug)才打印。这样的话,debug是编译期常量,当debug为false时,会在编译期优化掉这行打印代码。
更进一步的,c++17提供了按条件编译如下template<bool debug> void fun() { //按条件编译 if constexpr (debug)//这里不能传变量 { cout<<"debug..."<<endl; } } int main() { fun<false>(); } -
模板有惰性(函数重载 与 模板特化的区别)
模板函数没被调用到就不会去实际编译它,即使函数里面是错误的也不报错。
模板的声明和定义应当一起写在头文件里。 -
decltype的类型推导
- 带括号的作用
//1.decltype推导 不带括号的左值表达式、不带括号的类成员访问表达式、纯右值,结果为本身类型 //1.1不带括号的左值表达式 int x=0; decltype(x) x3; //x3为x同类型 A a; //1.2.不带括号的类成员访问表达式 decltype(a.m) x5;//x5为a.m同类型 //1.3.纯右值 decltype(A()) x4;//x4为A //2.其它情况:带了括号的左值表达式变为引用 decltype((x)) x2 = x3; //x2为int& - decltype(T1{} + T2{})的用法
#include <iostream> #include <vector> #include <numeric> using namespace std; template<class T1, class T2> auto add(vector<T1> t1, vector<T2> t2) { using T0 = decltype(T1{} + T2{}); vector<T0> res; for (int i = 0; i < t1.size(); i++) { res.push_back(t1[i]+t2[i]); } return res; } int main() { vector<int> x = {1,2,3}; vector<double> y = {1.1, 2.2, 3.3}; auto res = add(x, y); for (int i = 0; i < res.size(); i++) { cout<<res[i]<<endl; } return 0; }
- 带括号的作用
-
decltype(auto)可以推导出引用
int &fun() { int x =3; return x; } int fun2(){return 4;} int main() { //1.引用不是类型,auto不能推导出引用,因此fun函数必须返回引用 auto &p = fun(); //2.decltype(auto)可以推导引用:c++14提出的 decltype(auto) p2 = fun2(); return 0; }
函数式编程
- 函数式编程
- 函数可以作为 函数的参数
编译器会为每个不同Func对应的printfun生成一份函数void fun(int n) { cout<<"fun "<<n<<endl; } void fun2(int n) { cout<<"fun2 "<<n<<endl; } template<class Func> void printfun(Func fun, int n) { fun(n); } int main() { printfun(fun2, 3); return 0; } - 可调用对象包装器 std::function<返回值类型(参数类型)>
头文件 functional//这样写可以避免使用模板参数 //或者直接写函数指针 void printfun(void xx(int), int n) void printfun(function<void(int)> const &fun, int n) { fun(n); } - tuple容器(c++11)
#include <iostream> #include <tuple> using namespace std; template<typename T, size_t idx = 0> void print_tuple(const T& t) { auto v = get<idx>(t); cout << v << " "; const int n = tuple_size_v<T>; //必须使用条件编译 if constexpr(idx < n - 1) { print_tuple<T, idx+1>(t); } else { cout << endl; } } int main() { tuple<int, double, string> a(1,1.5,"xxx"); //读取 cout<<get<0>(a)<<endl; //解包 int x; double y; string z; tie(x,y,z) = a; cout<<x<<endl; //结构化绑定 auto [x,y,z] = a; // 遍历:没有提供operator[] const size_t n = tuple_size_v<decltype(a)>;//3 print_tuple(a); return 0; }- 结构化绑定
- 使用万能推导时,由于历史原因,不能写成decltype(auto),而是写成auto &&
auto &&[x,y,z] = tup - 结构化绑定不仅可以用于tuple,还能用于任意自定义类
struct Test { int a; float b; }; int main() { Test t = {1, 2.3f}; auto [x,y] = t; cout<<x<<" "<<y<<endl; return 0; }
- 使用万能推导时,由于历史原因,不能写成decltype(auto),而是写成auto &&
- 结构化绑定
- tuple作为函数返回值
#include <iostream> #include <tuple> #include <cmath> using namespace std; tuple<bool, int> fun(int x) { if (x>0) return {true, sqrt(x)}; else return {false, 0}; } int main() { auto ret = fun(4); cout<<get<1>(ret)<<endl; return 0; } - std::optional相当于更安全的指针
头文件optional- 两种获取ret值的方式
- ret.value() 会检查是否has_value(),空的话会抛异常
- *ret 不检查has_value(),不抛异常,但更高效
#include <iostream> #include <cmath> #include <optional> using namespace std; optional<int> fun(int x) { if (x>0) return sqrt(x); else return nullopt; } int main() { auto ret = fun(-1); //实际上 if(ret.has_value()) 等价于 if(ret) if (ret.has_value()) cout<<ret.value()<<endl; else cout<<"负数"<<endl; //写法2 //retvalue_or(0)等价于 ret.has_value()?ret.value:0 cout<<ret.value_or(0)<<endl; return 0; } - 两种获取ret值的方式
- variant相当于更安全的union
variant<int,string> v = 3; //1.获取数据 // string s = get<string>(v);//类型不匹配会抛出异常 int i = get<int>(v); //2.判断类型 cout<< holds_alternative<string>(v) <<endl; //3.静态多态:自动用相应的类型调用所写的lambda函数 visit([&](auto const &t){//这里使用auto lambda是模板函数,是惰性的,会多次编译 cout<<t<<endl; }, v); //4.visit支持多个variant 如果有n种类型,这里会编译n*n*n次,因此编译会变慢 variant<int, float> x= 1.5f; variant<int, float> y= 2; variant<int, float> z= 3; variant<int, float> ret; visit([&](auto const &t1, auto const &t2, auto const &t3){ ret = t1+t2+t3; if (holds_alternative<int>(ret)) cout<<get<int>(ret)<<endl; else cout<<get<float>(ret)<<endl; },x,y,z);
- 函数可以作为 函数的参数
汇编的角度
-
汇编
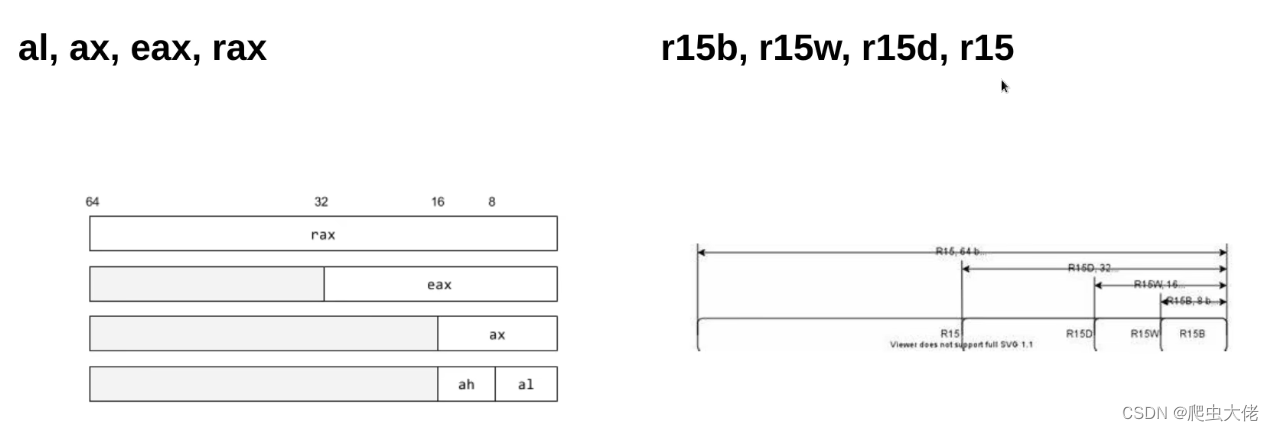
通用寄存器:
32位架构下只有8个32位通用寄存器,用于存取数据、存放栈指针、for循环计数。寄存器较少,因此一般使用线程栈来传参
到了64位架构时,原来的32位寄存器扩充为64位(名字由e开头改为r开头),且又增加了8个通用寄存器r8-r15。寄存器富裕了,因此一般用寄存器来传参了。标志寄存器:
最重要的是指令寄存器rip,指向了下一条要执行的指令所存放的地址
段寄存器:cs ds ss es fs gsxmm系列寄存器:
128位宽,可容纳4个float(存int也可以)
浮点数加法:addss:第1个s表示只对xmm最低位运行,p表示所有位。第2个s表示float类型,d表示double类型
 - 写循环时为什么使用size_t更好
- 写循环时为什么使用size_t更好在取数组值a[b]时,如果b是int,则b是32位的,而a作为指针是64位的。在访问数组元素时会首先将b转为64位,这一步在汇编中就是执行movslq %esi %rsi来扩展到64位,然后才去访问rsi值*4的偏移量处的值。
而如果使用size_t,在64位系统上就是uint64_t,32位系统上是uint32_t,就不需要使用movslq将其扩展到64位。 -
SIMD技术(单指令多数据):把4个float打包到一个xmm寄存器中同时计算
-
vector、map、set、string、function、any、智能指针都是存储在堆上的,妨碍优化
array、bitset、pair、tuple、optional、variant都是存储在栈上的 -
函数前加constexpr可以强制编译器在编译期求值
constexpr long fun() { long res=0; for (long i = 0; i < 262144; i++) { res++; } return res; } -
所有非const指针都声明为__restrict(gcc特有的,或#pragma GCC ivdep),只要确保该指针不会和其它指针重叠。
void fun(int *__restrict c)
也可以使用跨平台的OpenMP框架:
#pragma omp simd编译时加上−fopenmp对于没有声明为__restrict的两个指针,编译器担心它们重叠,会同时生成两份代码,一份是SIMD的,一份是传统标量的,运行时判断指针的差值是否超过1024来判断重叠。如果不止2个指针,编译器认为这段代码过于复杂,会放弃优化。
对于for循环遍历容器,无法使用__restrict来指明使用SIMD优化,需要用#pragma GCC ivdep或者#pragma omp simd -
加了volatile的对象,编译器会放弃优化其读写操作
int volatile *a注意语法上的区别:volatile要写在前,而__restrict要写在后
-
为什么数组个数n是4的倍数会更快
1个int是32位,如果存储4个int,编译器会使用SIMD加速,也就是矢量化,一次性读写4个int。如果不是4的倍数,例如1023,那么会将1020个元素用SIMD填入,剩余的3个元素使用传统标量方式填入,为了实现这样的功能,编译器会生成很复杂的边界特判代码
-
避免在for循环里调用外部函数,应当将要调用的函数放在同一个文件,这样编译器才能内联该函数
-
对于下面的for循环,只对a执行了1次操作,大部分时间都浪费在i++和判断上了,可以使用编译器指令进行循环展开
#pragma unroll 2 for (int i = 0; i < 1024; i++) { a[i] = 1; } /* 等价于: for(int i=0;i<1024;i += 2) { a[i+0]=1; a[i+1]=1; } */ -
结构体大小要为2的整数幂(alignas可以实现字节对齐)
struct test { float x;//32 float y;//32 float z;//32 //加一个没有用处的变量,使结构体大小变成2的整数幂,这样编译器才能进行SIMD优化 char padding[4];//32 }; //等价写法 //c++11 alignas(对齐到的字节数) struct alignas(16) test2 { float x; float y; float z; }; -
结构体的内存布局:AOS(xyzxyzxyz这样存储) 和 SOA(xxxxyyyyzzzz)
- 结构体数组:
struct test { float x; float y; float z; }; //分离存储多个属性 struct test2 { float x[1024]; float y[1024]; float z[1024]; }; int main() { //AOS 面向对象(OOP)的思想 test t[1024]; //SOA 面向数据(DOP)编程 test2 t2; return 0; } - 结构体容器也能实现SOA
struct test { float x; float y; float z; }; struct test2 { vector<int> x; vector<int> y; vector<int> z; }; int main() { //AOS 面向对象(OOP)的思想 vector<test> v; //SOA 面向数据(DOP)编程 test2 t2; return 0; }
- 结构体数组:
-
数学函数始终用std的,C语言版的函数对于不同类型数据要调用不同名字函数,例如sqrt和sqrtf
-
由于乘法比除法运算更快,编译器在明确除数非0时会计算倒数来执行乘法,但如果不明确会放弃优化:使用-ffast-math让GCC大胆尝试浮点运算的优化
TBB并行编程
-
TBB并行编程:Intel TBB是一个跨平台的C++并行编程库
#include <iostream> #include <vector> #include <cmath> #include <tbb/tbb.h> using namespace std; int main() { //1.任务组,需要自己调用wait等待执行完毕 tbb::task_group tg; tg.run([&](){ cout<<"1"<<endl; }); tg.run([&](){ cout<<"2"<<endl; }); tg.wait(); //2.使用parallel_invoke,会在函数返回前自动的等待所有lambda函数执行完毕 tbb::parallel_invoke([&](){ cout<<"1"<<endl; },[&](){ cout<<"2"<<endl; }); //3.parallel_for //方式1:简单的使用方法。这里演示的是捕获下标i,其实也支持迭代器 vector<float> v(10); tbb::parallel_for(0, 10, [&](size_t i){ v[i] = sin(i); }); //方式2:复杂,但编译器还能在此进行SIMD优化。捕获blocked_range tbb::parallel_for(tbb::blocked_range<size_t>(0,10), [&](tbb::blocked_range<size_t> r){ for (size_t i = r.begin(); i < r.end(); i++) { v[i] = sin(i); } }); //4.parallel_for_each。捕获元素 tbb::parallel_for_each(v.begin(), v.end(), [](float &f){ f = 32.f;//给每个值赋值为32的浮点数 }); for (size_t i = 0; i < 10; i++) { cout<<v[i]<<endl; } //5.parallel_reduce auto res = tbb::parallel_reduce(tbb::blocked_range<size_t>(0,100), 0.f, //对每个小块执行的操作 [&](tbb::blocked_range<size_t> r, float local_res){ for (size_t i = r.begin(); i < r.end(); i++) { local_res += i; } return local_res; }, //将各个局部结果进行累加 [](float x, float y){ return x+y; }); cout<<"0+1+...+99="<<res<<endl; return 0; } -
并行的parallel_reduce(数据并行)比串行的reduce好:可以避免浮点误差
计算数组内浮点数的和时,由于temp越加越大,如果是串行着累加,就会导致 大加小 丢失精度,而如果使用并行的累加,每次相加的就都是一个数量级的,会更精确。
-
并行扫描与串行扫描
parallel_scan扫描是指要输出串行执行时每次累加得到的当前结果。并行扫描就是要把各元素划分以后并行的累加,如先计算a1+a2、a3+a4、…,然后将缺失的中间结果a2+a3、…再次并行计算,得到扫描结果。因此,并行扫描比串行扫描更省时间,但工作量更大。
-
时间:tbb::tick_count::now()
-
tbb::task_arena指定用多少个线程来执行for循环
vector<int> v(10000, 0); tbb::task_arena ta(4);//指定要使用4个线程来执行 ta.execute([&](){ tbb::parallel_for(0, 10000, [&](size_t i){ v[i] = v[i] + 1; }); }); -
嵌套for循环
vector<int> x={1,2,3}; vector<int> y={4,5,6}; vector<int> res(3, 0); auto begin = chrono::steady_clock::now(); tbb::parallel_for(0, 3, [&](size_t i){ tbb::parallel_for(0, 3, [&](size_t j){ res[i] = res[i] + x[i]*y[j]; }); });- 嵌套for循环可能导致死锁,因为tbb采用的是工作窃取法来分配任务,内层循环的线程完成自己队列的工作后会去窃取执行外层循环线程的任务,这就可能导致重复上锁
解决方法:
1.使用递归锁recursive_mutex
2.另外创建任务域,隔离开内外层的线程
3.使用tbb:this_task_arena::isolate
- 嵌套for循环可能导致死锁,因为tbb采用的是工作窃取法来分配任务,内层循环的线程完成自己队列的工作后会去窃取执行外层循环线程的任务,这就可能导致重复上锁
-
parallel_for(数据并行)可以多跟一个参数可以指定怎么分配任务,默认不写就是自动判断使用什么分配方式
- tbb::static_partitioner 工作量平均分配给所有的线程
- auto_partitioner (默认)
ta.execute([&](){ tbb::parallel_for(0, 10000, [&](size_t i){ v[i] = v[i] + 1; }, tbb::simple_partitioner{}); }); - 对于矩阵转置,使用合适的粒度,可以比默认方式更快
#include <iostream> #include <vector> #include <tbb/tbb.h> #include <tbb/parallel_for.h> using namespace std; int main() { int n=1024; vector<float> a(n*n); vector<float> b(n*n); //矩阵转置。这里多指定出粒度grainsize,即没=每行16个块,每列16个块 tbb::parallel_for(tbb::blocked_range2d<size_t>(0, n, 16, 0, n, 16), [&](tbb::blocked_range2d<size_t> r){ for (size_t i = r.cols().begin(); i < r.cols().end(); i++) { for (size_t j = r.rows().begin(); j < r.rows().end(); j++) { b[i*n + j] = a[j*n + i]; } } }, tbb::simple_partitioner{}); return 0; }
-
tbb::concurrent_vector: 内存不连续的、线程安全的vector
std::vector在容量不够时,会扩容移动元素,如果之前保存有vector中元素的地址,在扩容后就有问题。可以使用tbb::concurrent_vector
tbb::concurrent_vector<int> v; vector<int *> ptr; for (size_t i = 0; i < 100; i++) { auto it = v.push_back(i); ptr[i] = &*it;//*it是int } -
concurrent_vector是线程安全的
//1.vector的push_back不是并发安全的,因此这里使用多线程并发push_back会出错 vector<int> vv; tbb::parallel_for(0, 1000, [&](size_t i){ vv.push_back(i); }); cout<<vv.size()<<endl; //2.使用并发版的vector tbb::concurrent_vector<int> v; tbb::parallel_for(0, 1000, [&](size_t i){ auto it = v.push_back(i);//concurrent_vector的push_back方法会返回该元素的迭代器 }); cout<<v.size()<<endl; -
正确实现并行筛选:先推入到局部,再拷贝到全局
#include <iostream> #include <vector> #include <tbb/tbb.h> #include <tbb/parallel_for.h> #include <chrono> using namespace std; int main() { /* 不应该直接多线程的边筛选边推入到concurrent_vector, 这样各线程之间频繁的抢着push_back到concurrent_vector,导致不够高效 应该线程中先把结果推入到局部的vector中,再一次性推入到concurrent_vector */ //1.不正确的写法 tbb::concurrent_vector<int> a1; auto t1 = chrono::steady_clock::now(); tbb::parallel_for(tbb::blocked_range<size_t>(0, 10000), [&](tbb::blocked_range<size_t> r){ vector<int> local_a; for (size_t i = r.begin(); i < r.end(); i++) { //筛选,偶数位的才放入 if (i%2 == 0) { a1.push_back(i); } } }); auto t2 = chrono::steady_clock::now(); cout<<(t2-t1).count()<<endl; cout<<a1.size()<<endl; //2.正确的写法:更快 //如果需要内存连续的vector,那么这里用std::vector,但在下面一次性推入时要记得先加锁 tbb::concurrent_vector<int> a; auto t3 = chrono::steady_clock::now(); tbb::parallel_for(tbb::blocked_range<size_t>(0, 10000), [&](tbb::blocked_range<size_t> r){ //先把结果放在局部vector中 vector<int> local_a;//可以使用reserve预先分配内存,这样会更快 for (size_t i = r.begin(); i < r.end(); i++) { //筛选,偶数位的才放入 if (i%2 == 0) { local_a.push_back(i); } } //一次性推入到concurrent_vector auto it = a.grow_by(local_a.size());//给a扩容,返回第一个新元素位置 for (size_t i = 0; i < local_a.size(); i++) { *it++ = local_a[i]; } }); auto t4 = chrono::steady_clock::now(); cout<<(t4-t3).count()<<endl; cout<<a.size()<<endl; return 0; } -
parallel_invoke:并行的执行多个任务(任务并行)
#include <iostream> #include <tbb/tbb.h> using namespace std; int main() { tbb::parallel_invoke([](){ int i=0; while (1) { cout<<i++<<endl; sleep(1); } }, [](){ int i=100; while (1) { cout<<i--<<endl; sleep(1); } }); return 0; } -
parallel_pipeline流水线并行
假设现在for循环要执行4个步骤,有3种方式
1.粗暴的并行for:直接改写为parallel_for_each下执行4个步骤
这样循环体太大,每个线程都在读写不同的数据,导致内存成为瓶颈
2.写成4个parallel_for_each:这样每个循环体就变小成只执行一个步骤了,但是每个线程执行完后还需要同步数据
3.流水线并行parallel_pipeline:每个线程只做自己的那个步骤#include <iostream> #include <vector> #include <tbb/tbb.h> // 定义一个处理阶段的函数对象 struct ProcessStage { void operator()(int& item) const { // 在这里进行具体的处理逻辑,这里只是简单地将item乘以2 item *= 2; } }; int main() { // 创建一个输入数据的向量 std::vector<int> input = {1, 2, 3, 4, 5}; // 定义一个输出数据的向量 std::vector<int> output(input.size()); // 定义一个处理阶段的函数对象 ProcessStage processStage; // 使用parallel_pipeline进行并行处理 tbb::parallel_pipeline( input.size(), // 并行度,即处理阶段的数量 tbb::make_filter<void, int>( tbb::filter::serial_in_order, // 串行顺序执行 [&](tbb::flow_control& fc) -> int { static int index = 0; if (index < input.size()) { return input[index++]; } else { fc.stop(); return 0; } })& tbb::make_filter<int, void>(//流水线上一步的返回类型要和下一步的输入类型一致 tbb::filter::parallel, // 表示可以并行执行当前步骤,且顺序可打乱 [&](int item) { processStage(item); })& tbb::make_filter<void, int>( tbb::filter::serial_in_order, // 只允许串行执行,顺序必须一致 [&](tbb::flow_control& fc) -> int { static int index = 0; if (index < output.size()) { return index++; } else { fc.stop(); return 0; } })& tbb::make_filter<int, void>( tbb::filter::serial_out_of_order, // 只允许串行执行,顺序可打乱 [&](int item) { output[item] = item; }) ); // 输出处理结果 for (int item : output) { std::cout << item << " "; } std::cout << std::endl; return 0; }















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









