







论文标题
论文作者、链接
作者:Bo, Deyu and Wang, Xiao and Shi, Chuan and Zhu, Meiqi and Lu, Emiao and Cui, Peng
链接:Structural Deep Clustering Network | Proceedings of The Web Conference 2020
代码:https://github.com/bdy9527/SDCN
Introduction逻辑
论文动机&现有工作存在的问题
(1)现有工作往往着重于数据自身的特征,忽视了数据的结构化信息
(2)在深度聚类中,应该选取怎样的结构信息
(3)结构信息和深度聚类之间有什么样的关系
论文核心创新点
(1)将K近邻和深度神经网络结合
(2)GCN为DNN表示提供了近似的二阶图正则化
相关工作
深度聚类:忽略了数据的结构化信息
基于图卷积网络的深度聚类:忽略了数据本身自带的信息
论文方法

本文模型流程:(1)根据原始数据构建KNN图(2)将原始数据和原始KNN图分别输入自编码器和GCN(3)使用双重自监督模块计算损失指导模型训练
KNN图
有一组原始数据![]() ,其中每一行的
,其中每一行的代表第i个样本,N是样本的个数,d是维度。对每一个样本,先用边使该样本与这最近的K个邻居点相连。
本文主要采用两种方法计算相似性矩阵![]()
(1)Heat Kernel:样本i和j的相似性计算方法为:
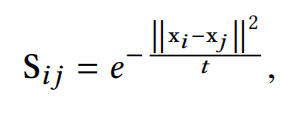
其中,t是时间参数
(2)Dot-product:样本i和j的相似性计算方法为:

在计算相似性矩阵S后,我们选取每个样本的top-K相似点作为其邻点,构造无向k近邻图。这样,我们就可以从非图数据中得到邻接矩阵A。
DNN模块
假设有一个L层的自编码器,l代表第l层的编码,则第l层输出的特征如下

其中,代表全连接层的激活函数,
分别为编码器的第l层的权重矩阵和偏置矩阵。将原始数据记为
。
编码器后跟着一个解码器,目标是通过几个全连接层重构输入的数据,公式如下:

其中,分别为解码器的第l层的权重矩阵和偏置矩阵。解码器的输出为重构的原始数据
![]() ,目标函数为:
,目标函数为:

GCN模块
将DNN学到的特征都集成到GCN中,那么GCN学习的特征表示将能够适应两种不同类型的信息,即数据本身以及数据之间的相互关系。对于权值矩阵以及GCN第i层学习到的表示
,可以通过下面的卷积运算得到:

其中![]() ,
,是每个节点的自环的相邻矩阵
的单位对角矩阵。从上式中可知,特征表示
经过正则化领接矩阵
![]() 传播得到新的特征表示
传播得到新的特征表示。自编码器学习到的特征
能够重构回数据本身并且含有不一样的丰富信息。我们将
和
结合起来得到更复杂并且强而有力的特征表示:
![]()
其中,![]() 是平衡系数,恒设为0.5。这样可以将自编码器和GCN一层层的链接起来。
是平衡系数,恒设为0.5。这样可以将自编码器和GCN一层层的链接起来。
将![]() 记为GCN第l层的输入,并且产生的输出为:
记为GCN第l层的输入,并且产生的输出为:
![]()
在上式中,![]() 将被通过正则化邻接矩阵
将被通过正则化邻接矩阵![]() 传播。因为DNN每一层学到的特征不一样,所以我们将从每个DNN层学习到的表示转移到相应的GCN层进行信息传播。交付操作在整个模型中执行L次。
传播。因为DNN每一层学到的特征不一样,所以我们将从每个DNN层学习到的表示转移到相应的GCN层进行信息传播。交付操作在整个模型中执行L次。
值得注意的是,GCN的第一层输入是原始数据:

GCN的最后一层输出是一个多分类层后接softmax函数:

其中,结果![]() 代表样本i属于簇中心j的概率,可以把
代表样本i属于簇中心j的概率,可以把视为概率分布
双路自监督模块
上文介绍中已经将GCN和神经网络的架构结合。为了将模型应用于聚类,便设计了该模块。
对于第i个样本以及第j个簇,我们使用学生t-分布去衡量数据表示和簇中心向量的
的相似性,公式如下:

其中,是
的第i行,
是使用K-means算法对预训练的自编码器学到的特征进行初始化得到的,t是学生t-分布的自由度。
可以视为将样本i分配给簇j的概率。将
![]() 视为所有样本的分配概率。
视为所有样本的分配概率。
得到聚类结果分布之后,模型根据高置信度的聚类结果优化特征学习过程。具体来说,就是让学到的特征尽可能的靠近簇中心。因此,目标分布
的计算公式为:

其中,![]() 是软簇频率,就是将所有选中分配给簇j的样本点求和,也就是簇j的被选中的概率\频率。在目标分布
是软簇频率,就是将所有选中分配给簇j的样本点求和,也就是簇j的被选中的概率\频率。在目标分布中,对
中的每一个赋值进行平方和标准化,使赋值具有更高的置信度,计算
和
的KL散度:

目标分布可以帮助DNN模块学习到更好的聚类任务表示。
GCN模块也会提供一个簇分布,于是分布
也可以由分布
指导训练:

这样的损失设计有两个好处:
(1)与传统的多分类损失函数相比,KL散度以一种更“温和”的方式更新整个模型,防止数据表示受到严重干扰;
(2) GCN和DNN模块统一在同一个优化目标下,使得训练过程中其结果趋于一致。
本文的全局损失函数:
![]()
其中,。
训练过程中,选分布作为最后的聚类结果,标签分配方式为:
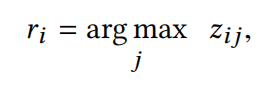
本文算法

消融实验设计
不同传播层的分析
平衡系数分析
K敏感度分析
训练过程分析
一句话总结
将图卷积和自编码器结合设计的模型,总体设计比较有趣。
论文好句摘抄(个人向)
无















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









