







论文标题
论文作者、链接
作者:Liu, Yixin and Zheng, Yu and Zhang, Daokun and Chen, Hongxu and Peng, Hao and Pan, Shirui
链接:https://arxiv.org/pdf/2201.06367.pdf
Introduction逻辑
图神经网络——图神经的基础假设——如果GNN可以学习样本间的潜在关系性能会更好——deep graph structure learning(GSL)深度图结构学习解决上述问题——GSL存在的问题——本文方法

论文动机&现有工作存在的问题
图神经的基础假设:原始结构足够可信作为ground-truth,但是这个假设往往在现实中不成立
GSL存在问题:(1)对标签的依赖(2)边缘分布的学习存在偏差(3)受到下游任务的限制
论文核心创新点
(1)无监督学习
(2)下游任务普适性
(3)从原始数据中构建一个“锚图”来指导结构优化,并以一个对比损失来最大化锚图和学习到的结构之间的互信息(MI)。
(4)设计了一个加速机制
相关工作
图神经网络
深度图结构学习:现有方法都是有监督的
基于图谱的对比学习:现有方法往往没有将GSL和对比学习结合
问题定义
一个特征图定义为,其中
是
的点集,
是
的边集,
是节点的特征矩阵,并且
的权重邻接矩阵(
是
和
相连的边的权重)
本文有两种无监督的GSL任务,两种任务下都是无标签的:
(1)结构推理:当图结构没有预先定义或者是无法使用的情况。
给定一个特征矩阵,结构推理的目标是自动学习一个图拓扑结构
,这个图反映了样本数据之间的潜在相关性。其中,
代表样本点
和
之间是否有边相连。
(2)结构精炼:对于给定的含噪声的拓扑结构,产生含有更丰富信息的图谱。
给定一个图,其中
是噪声图结构,结构精炼的目标是将
细化为优化的邻接矩阵
,以便更好地捕捉节点之间的底层依赖关系。
对于从数据中自动学习或从现有图结构中精炼的图拓扑,假设
作为输入,可以从本质上提高下游任务的模型性能。
论文方法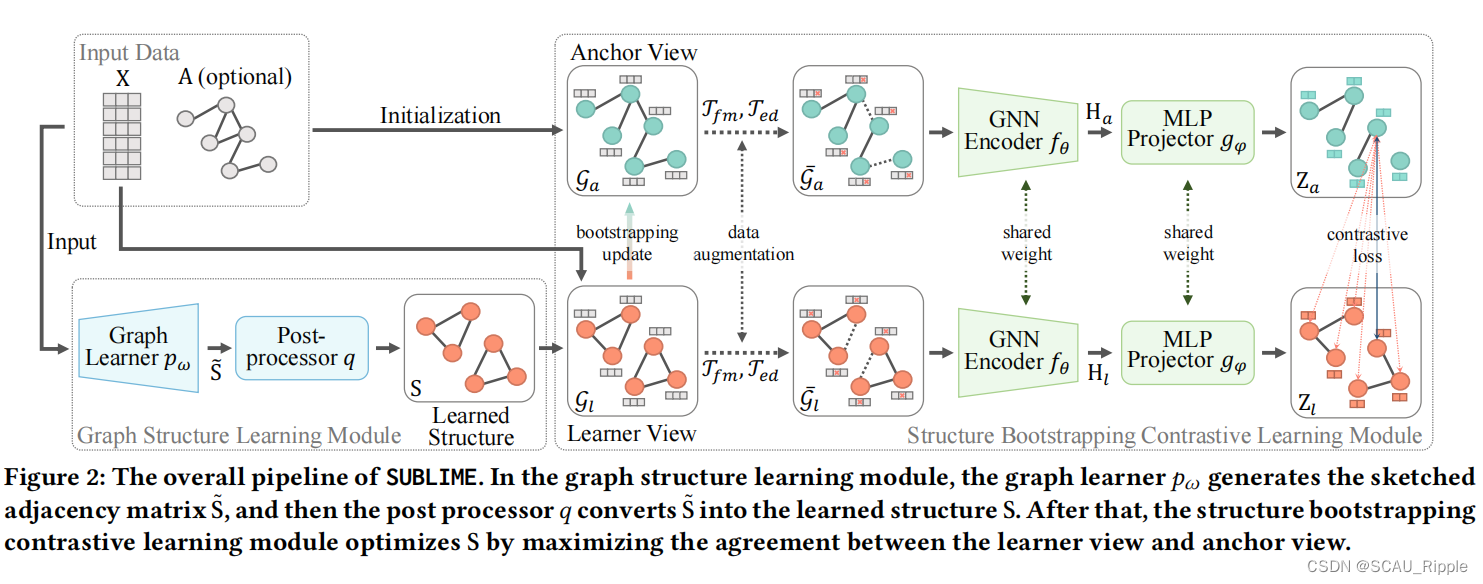
主要由两个模块组成:(1)图结构学习模块(2)结构引导对比学习模块
图学习器
图学习器生成一个草图邻接矩阵带着一个含参数的模型。现有的方法往往使用一个单独的策略对图进行建模,因此不能适应不同的数据。为了找到最好的建模方法,本文使用四种图学习器,包括:full graph parameterization 全图参数化(FGP)学习器和三种基于度量学习的学习器(即,attention, MLP和GNN)。将图学习器记为
,其中
是一个可学习的参数。
FGP学习器
FGP学习器直接用一个独立参数对邻接矩阵的每个元素建模,不需要任何额外的输入。
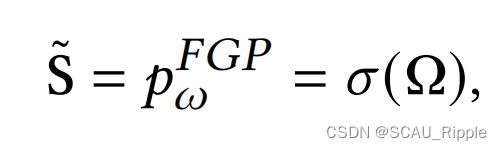
其中,是参数矩阵,
是一个非线性函数。FGP假设图谱中的每一条边都是独立存在的。
基于尺度的学习器
与FGP不同,基于尺度的学习器先从属于的数据中获得一个节点嵌入,然后根据节点嵌入的成对相似性建模
:
![]()
其中是神经网络,
是一个无参的尺度函数(余弦相似性或者Minkowski distance)用来计算相似性。对于不同的
本文使用不同的基于尺度的学习器:细腻学习器,MLP,GNN
Attentive Learner 注意学习器
使用一个GAT似的注意网络,对每一层计算输入特征向量和参数向量的哈达玛积
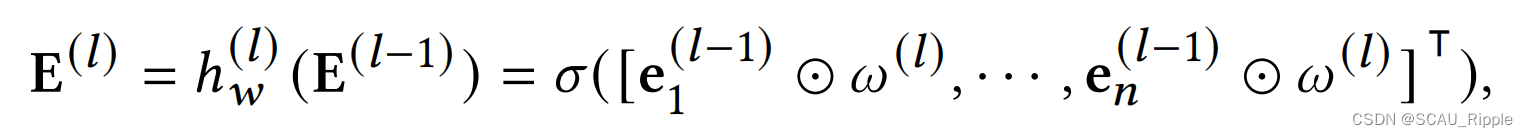
其中,是网络的第
层输出,
是
的第
行向量的转置,
是第
层的参数向量,
是哈达玛积,
是转置操作,
是一个非线性函数。第一层
的输入是特征矩阵
,最后一层
的输出是嵌入矩阵
。注意学习器假设每个特征对边的存在有不同的贡献,但特征之间不存在显著的相关性。
MLP学习器
使用多层感知机作为嵌入网络,其中单层的公式为:
![]()
其中是第
层网络的参数矩阵,其他标识与上文相同。比起注意学习器,MLP学习器更注意特征的相关性和组合,生成更富含语音信息的嵌入。
GNN学习器
通过基于GNN的嵌入网络,集成特征矩阵和原始结构矩阵
到节点嵌入
中。因为需要原始的拓扑结构,所以GNN学习器只用于结构精炼任务。GCN层的公式化表示如下:

其中是带有自环结构的邻接矩阵,
是
的度矩阵,其他标识与上文相同。GNN学习器假设两点之间的链接不仅与特征有关还与原始的图谱结构有关。
本文在不同的数据集选用不同的学习器。
后处理器
后处理器旨在细化草图的邻接矩阵
到一个稀疏的,非负的,对称的和标准化的邻接矩阵
。总共分为四步:(1)稀疏化sparsification
(2)激活activation
(3)对称化symmetrization
(4)正则化normalization
稀疏化sparsification
草图邻接矩阵往往是稠密的,代表了一个全连接的图结构。但是这种邻接矩阵计算开销大,而且还只有一点作用。于是使用KNN对该矩阵进行稀疏化。具体来说就是,对于每一个节点,保持最近邻的K个结点的边,剩余的边全部置为。公式如下:
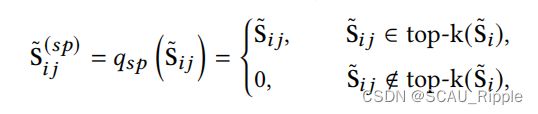
其中是
的前k个行向量的值的集合。为了梯度顺利,本文不将稀疏化应用于FGP学习器。对于大规模图,用它的位置敏感近似进行kNN稀疏化,从一批节点中而不是从所有节点中选择最近的邻居,减少了对内存的需求。
对称和激活Symmetrization and Activation
在现实世界的图谱中,连接通常是双向的,这需要一个对称的邻接矩阵。并且边的权值应该为非负的。为了满足这个要求,有:

其中是一个非线性的激活函数,在基于尺度的学习器中使用ReLU,在FGP学习器中使用ELU激活来避免梯度消失。
正则化 Normalization
为了使得边的权重在[0,1]范围内,对进行正则化操作。
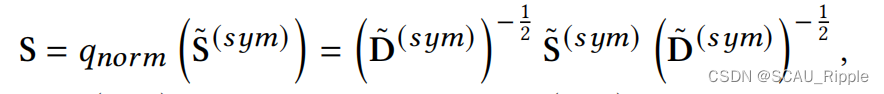
其中是
的度矩阵。
多视图对比学习
上文中已经计算得到一个参数良好的邻接矩阵,接下来的问题是:如何在无标签的情况下指导图结构学习?本文从多视图对比学习中提供无监督学习的指导信号。
图谱视图建立
现有图对比学习模型往往是从原始数据获得不同的视图。本文将学到的图谱定义为一个视图,然后由输入数据构建另一个视图。前者称为学习视图learner view在每一步训练中提供潜在结构,后者称为锚视图anchor view提供GSL的稳定学习目标。
学习视图:由学习到的邻接矩阵与特征矩阵
结合起来直接建立的,记作
。每次训练迭代中,
及参数直接由梯度下降更新。在GSL中,根据KNN图初始化学习视图。在FGP学习器中,将KNN选择的结点之间的边权值置为1,剩余的为0。对于注意学习器,
中的每一个元素都置为1,然后根据尺度函数计算相似性。对于MLP和GNN学习器,将嵌入维度设为
然后初始化
为单位矩阵。
锚视图:作为一个”老师“的角色,指导GSL训练。在结构精炼任务中,原始结构矩阵是可利用的,将锚视图定义为
;在结构推理任务中,原始结构矩阵
是不可得到的,将锚视图定义为
。为了提供一个稳定的学习目标,锚视图不是通过梯度下降来更新的,而是一种本文设计的新的引导机制,后文介绍该机制。
数据增广
本文主要用两种:(1)特征掩膜(2)边缘抛弃。
在结构和特征水平破坏图谱视图。
特征掩膜:随机选择一小部分特征维度,把其值置为0。对于给定的特征矩阵,一个掩膜向量
的每个元素都是从概率为
的伯努利分布中独立提取的。掩膜公式如下:
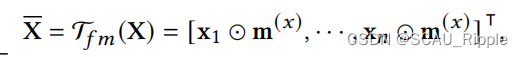
其中,是增广后的特征矩阵,
是特征掩膜变换,
是
的第
行向量的转置。
边缘抛弃:随机丢弃一些边。对一个给定的邻接矩阵,先生成一个掩膜矩阵
,其中每一个元素
是从概率为
的伯努利分布中独立提取的。操作结束后,邻接矩阵被
掩盖:
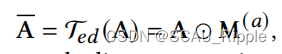
其中,是增广过后的邻接矩阵,
是边缘抛弃变换。
联合利用这两种增强方案,在学习和锚视图上生成增强视图:
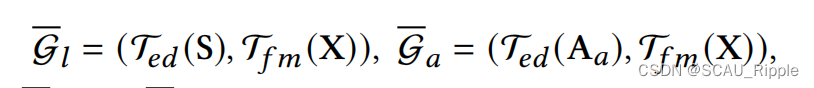
其中,和
是增广过后的学习视图和锚视图。
为了在两个视图中获得不同的上下文信息,两个视图的特征掩膜采用不同的概率,。对于边缘抛弃,因为两个视图的邻接矩阵已经显著不同,使用相同的抛弃概率
。
结点级的对比学习
得到两个视图之后做节点级的对比学习,采用来自SimCLR的对比学习框架
基于GNN的编码器:一个基于GNN的编码器提取增广后的视图
和
的结点级的特征:
![]()
其中,(
是特征维度)是结点特征矩阵,分别对应学习、锚视图。本文使用一个两层的GCN作为编码器。
基于MLP的投影器:一个投影器记为,是一个
层的MLP,将特征映射到计算对比损失的潜空间中:
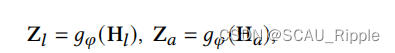
其中,是映射后的特征矩阵,分别对应学习、锚视图,
是映射维度。
结点级的对比损失函数:一个对比损失用来计算一个结点的两个视图,经过投影后得到的
和
的相似性:

其中,代表余弦相似性函数,t是温度参数。
结构引导机制Structure Bootstrapping Mechanism
固定一个由或者
确定的锚邻接矩阵
,本文算法SUBLIME可计算两个视图的最大化互信息来学习图结构。使用固定的锚邻接矩阵会存在一些问题:
(1)错误信息的继承。是从原始输入数据得到的,也会得到其中的噪音。
(2)缺乏持续的指导。固定锚图只包含有限的信息来引导GSL。
(3)对于锚结构的过拟合。两个视图之间的一致性最大化,学习结构往往会过度拟合固定锚结构,导致测试性能与原始数据相似。
由基于引导的算法启发,本文设计了一个结构引导机制。核心想法是缓慢的更新,而不是保持不变。对于衰减率
,
每
轮更新一次:

随着更新的进行,那些有噪声的边的权值会越来越低。并且因为是变化的,所以总是使用更有效的信息来指导图谱的学习,过拟合问题也能被避免。
消融实验设计
参数的消融
结构引导机制的消融
超参的敏感性消融
一句话总结
感觉本文模型结构也复杂,论文写的也复杂…其实核心感觉也是如何构建样本对如何执行对比学习
论文好句摘抄(个人向)
(1)Nonetheless, these methods focus on a supervised learning scenario, which leads to several problems, i.e., the reliance on labels, the bias of edge distribution, and the limitation on application tasks.
(2)...use a contrastive loss to maximize the agreement between the anchor graph and the learned graph.
(3)Such assumption, unfortunately, is usually violated in real-world scenarios,...
(4)To tackle the aforementioned problems,
(5)Through maximizing their consistency, informative hidden connections can be discovered, which well respects the node proximity conveyed by the original features and structures.
(6)We perform extensive experiments to corroborate the effectiveness and analyze the properties of SUBLIME via thorough comparisons with state-of-the-art methods on eight benchmark datasets.
(7)...,which pulls the representations of samples with shared semantic information closer while pushing the representations of irrelevant samples away
(8)This section elaborates our proposed SUBLIME, a novel unsupervised GSL framework
(9)Concretely
(10)Since we have obtained a well-parameterized adjacency matrix S, a natural question that arises here is: how to provide an effective supervision signal guiding the graph structure learning without label information?Our answer is to acquire the supervision signal from data itself via multi-view graph contrastive learning.















 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









