







论文标题
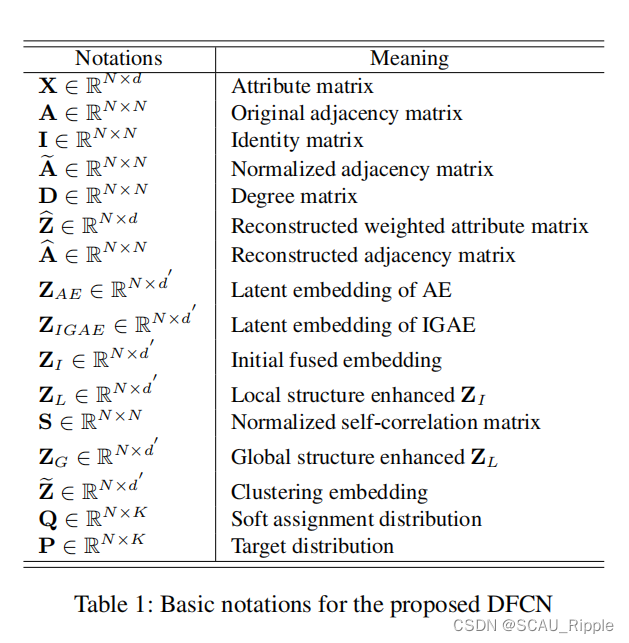
Deep fusion clustering network
论文作者、链接
作者:Tu, Wenxuan and Zhou, Sihang and Liu, Xinwang and Guo, Xifeng and Cai, Zhiping and Cheng, Jieren and others
链接:https://arxiv.org/abs/2012.09600
代码:GitHub - WxTu/DFCN: AAAI 2021-Deep Fusion Clustering Network
Introduction逻辑
深度聚类简介——对深度聚类的分类简介——早期深度聚类集中于挖掘数据原始特征空间中的信息——现在的深度聚类倾向于添加几何结构信息——对一些图聚类进行介绍——现有方法存在的问题——本文方法
论文动机&现有工作存在的问题
(1)缺少一种动态融合机制,能够有选择地整合和细化图结构和节点属性信息,用于共识特征表示学习
(2)未能从双方提取信息进行鲁棒目标分布(即“groundtruth”软标签)生成。
论文核心创新点
(1)一个基于相互依赖学习的结构与属性信息融合(SAIF)模块
(2)一种可靠的目标分布生成方法和一种三重自我监督策略
相关工作
图聚类:over-smoothing限制了GCN的准确性,SDCN中两个子网络缺少信息交互
目标分布生成:即自监督学习中的软标签。现有方法只用autoencoder或者GCN,没有将它们合起来
论文方法
论文中所使用的标识
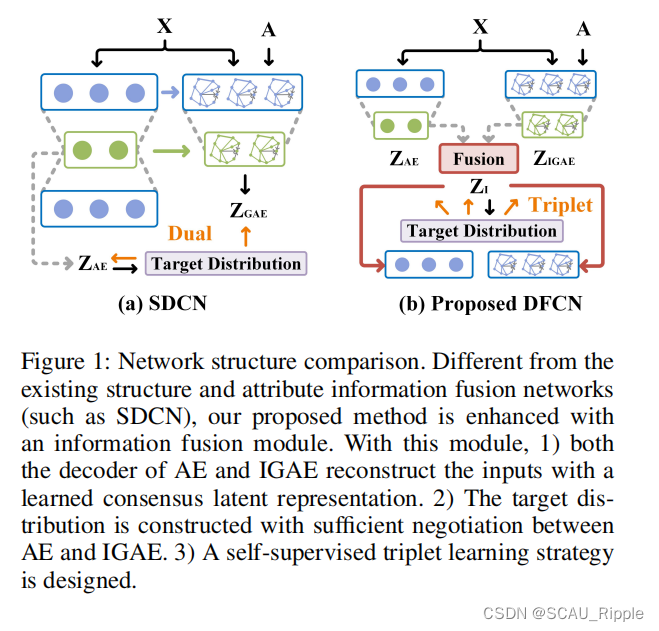
对一个无向图有K个簇中心,
为顶点集,
为边集,
是样本个数。图谱由特征矩阵
以及原始邻接矩阵
表示。
是特征维度,并且如果
,则
,否则
。
对应的等级矩阵为,并且
,对于
矩阵的原始邻接矩阵通过
进一步正则化为
,其中
代表
中的每个结点都链接着一个自环型结构。
基于融合的自编码
现有的自编码器往往根据自身的潜在特征对输入进行重构。我们首先整合GAE和AE学到的特征以获得共通的潜在表示。然后将这种嵌入作为输入,AE和GAE的解码器对两个子网络的输入进行重构。与其他现有的方法区别在于通过融合模块融合异构结构和特征信息,然后用共识潜在特征表示重构两个子网络的输入。
增强图自编码器
现有的图自编码器往往忽视基于结构的特征信息。本文为图编码器添加了邻接信息和结构信息,设计了improved graph autoencoder (IGAE)。
在IGAE中,编码器和解码器中的一层公式表示为:
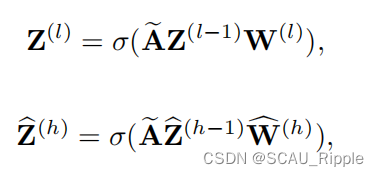
其中![]() 和
和![]() 分别表示第
分别表示第层的编码器和第
层的解码器。
是非线性的激活函数,ReLU或者Tanh。 IGAE的总损失为:
![]()
其中的两项为:
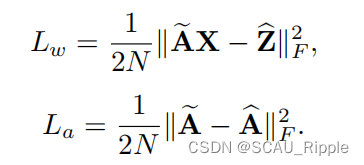
其中,是重构的权值特征矩阵,
是重构的邻接矩阵。网络在训练过程中可以同时减小特征矩阵和邻接矩阵的重构误差。
结构信息与特征信息融合
本文提出structure and attribute information fusion (SAIF)
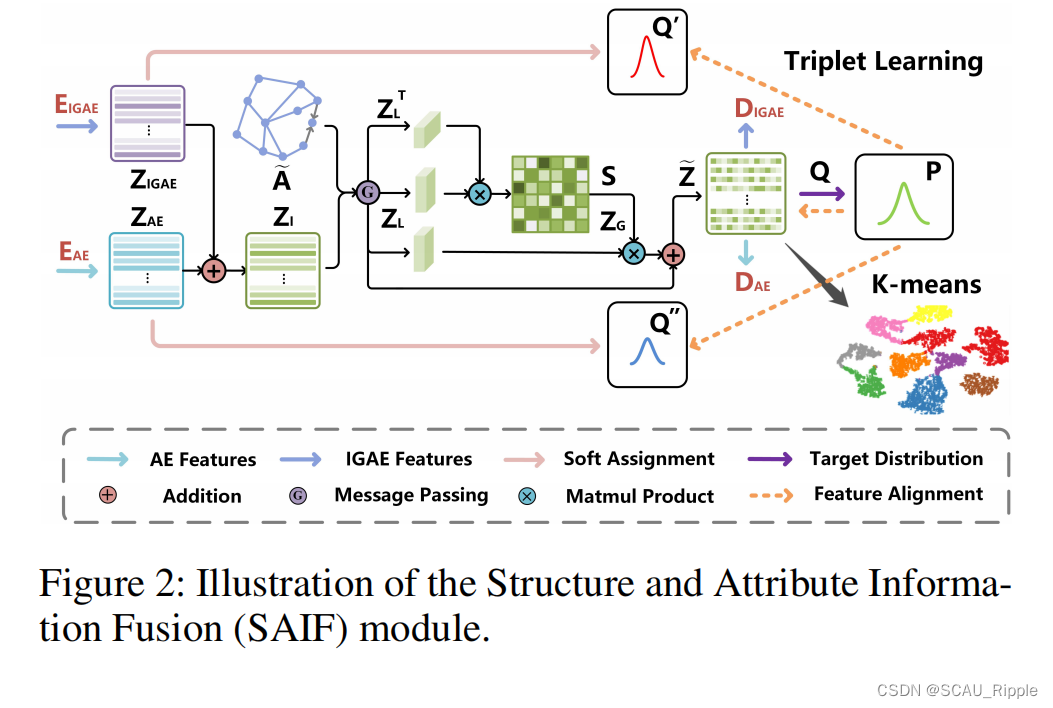
跨模态动态融合机制:从局部和全局考虑样本之间的相关性,精炼AE和IGAE学习的信息
分四步:
(1)将AE的潜在嵌入向量和GAE的潜在嵌入向量
线性融合
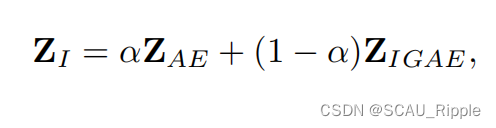
其中是潜在嵌入的维度,
是超参,本文设为0.5。
(2)然后,用一个类似于图卷积的操作处理组合信息。在这个操作下,通过考虑数据的局部结构信息强化初始融合嵌入:
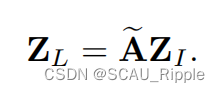
其中,表示局部信息增强的
(3)引入样本间信息融合空间的非局部关系,先计算正则化的自相关矩阵通过以下公式:

将S视为系数,通过考虑样本间的全局相关性重组通过
(4)们采用跳跃式连接来鼓励信息在融合机制中传递:
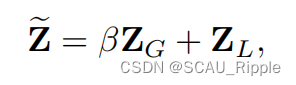
其中,是尺度参数,初始化为0,在训练中学习该参数。
三路自监督策略
从AE和IGAE生成聚类嵌入来指导聚类学习,生成目标分布包括以下两个步骤:
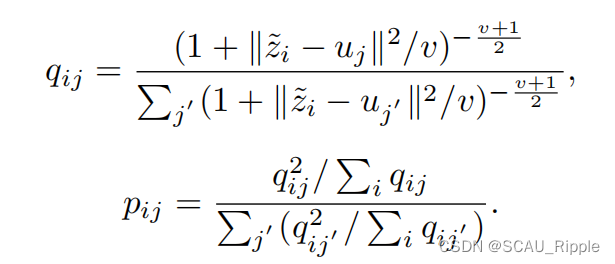
第一条公式表示,在融合嵌入空间中,以学生t分布作为核函数计算,第个样本
和第
个预计算的簇中心
的相似性。
第二条公式中,是学生t分布的自由度,
表示将第
个结点分配给第
个簇中心的概率。软分布矩阵
反映了所有样本的分布。为了提高聚类分布的自信度,第二条公式将会使得所有样本尽可能靠近簇中心。其中,
是生成的目标分布
的一个样本,代表了第
个样本分配给第
个簇中心的概率。
将AE和IGAE的软分配分布记为:和
。
为了让网络作为一个整体训练,设计了一个三联聚类损失,通过下列的KL散度计算:
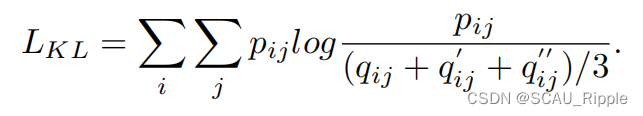
在该公式中,AE、IGAE和融合特征的软分配分布之和,同时与目标分布对齐。
联合损失以及优化
全局的目标函数为:

伪代码

消融实验设计
IGAE的有效性
SAIF模块的分析
双源信息的影响
超参分析
一句话总结
在SDCN的基础上做了目标分布的融合
论文好句摘抄(个人向)
(1) They require only the latent representation to reconstruct the adjacency information and overlook that the structure-based attribute information can also be exploited for improving the generalization capability of the corresponding network.















 1035
1035











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









