






今日主要总结一下,47. 全排列 II
题目:47. 全排列 II
题目描述:
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
示例 2:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
提示:
1 <= nums.length <= 8
-10 <= nums[i] <= 10
本题重难点
大家在做这道题之前最好做一下46. 全排列
和40. 组合总和 II这两道题,这道题其实就是以上两道题的结合应用
或者看一下一文搞懂回溯解决全排列问题上篇和一文搞懂回溯解决有重集合中结果去重的组合问题我对这两道题有详细的讲解
这道题目和题目46. 全排列的区别就是给定一个可包含重复数字的序列,而求取的最后全排列的结果要去重。
本题的难点在于:输入集合有重复元素,输出但还不能有重复的排列结果。
首先要搞懂排列和组合以及子集问题的区别:
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的组合以及子集所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
但排列问题需要一个used数组,而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
在40.组合总和II、90.子集II分别解决了组合问题和子集问题如何去重。
那么排列问题其实也是一样的套路。
还要强调的是去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
以示例中的 [1,1,2]为例 (为了方便举例,已经排序)抽象为一棵树,去重过程如图:
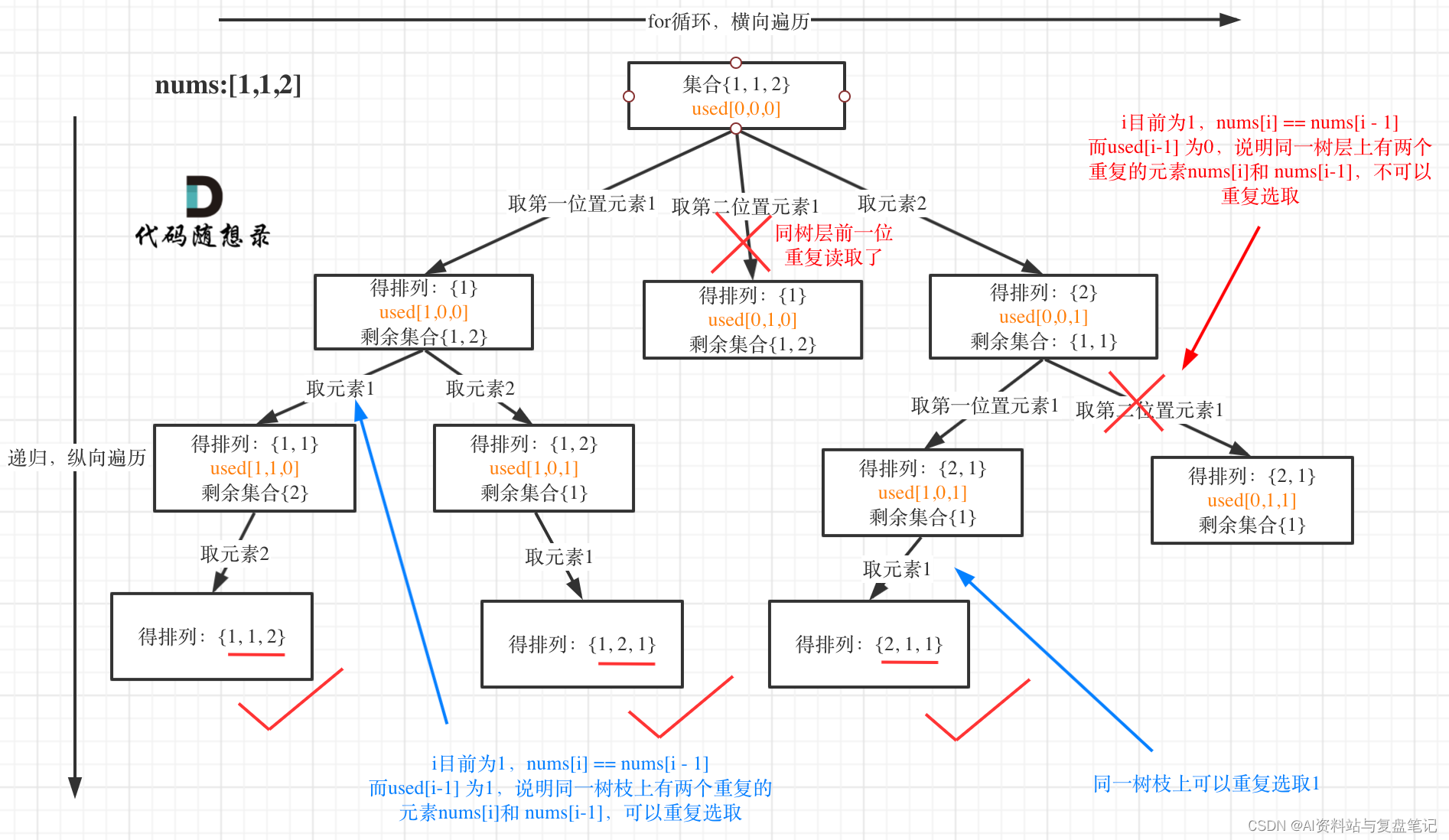
图中和我们之前讲的去重方法一样,对同一树层,前一位(也就是nums[i-1])如果使用过,那么就进行去重——即树层去重!!!
一般来说:组合问题和排列问题是在树形结构的叶子节点上收集结果,而子集问题就是取树上所有节点的结果。
一、正确解法
C++代码
class Solution {
public:
vector<vector<int>> res;
vector<int> path;
vector<bool> used;
void backtracing(vector<int>& nums, vector<bool>& used){
if(path.size() == nums.size()){
res.push_back(path);
return;
}
for(int i = 0; i < nums.size(); i++){
if(used[i] == true || i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
path.push_back(nums[i]);
used[i] = true;
backtracing(nums, used);
used[i] = false;
path.pop_back();
}
return;
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
res.clear();
path.clear();
sort(nums.begin(), nums.end());
used.resize(nums.size(), false);
backtracing(nums, used);
return res;
}
};
树层去重最为关键的代码为:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
大家在开始接触这个算法时很容易会迷惑,当nums[i] == nums[i - 1]时,used[i - 1] == false和used[i - 1] == true哪个代表树层去重哪个又代表树枝去重呢???
其实很容易理解:
根据之前回溯算法所讲,当需要遍历到上面树形图中某一个节点1的同一层的右侧节点时需要回溯退回到该节点的上一次父节点再向父节点的右下进行遍历该节点1的同一层的右侧节点
1. 因为回溯逻辑会对used数值的更新进行撤销,即调用backtracing函数的下一句代码used[i - 1] = false,所以树层去重一定对应used[i - 1] == false
2. 同理王深层树枝遍历是通过递归进行的,即先used[i - 1] = true,再调用backtracing(nums, used),此时used[i - 1] == true,所以树枝去重一定对应used[i - 1] == true
本题其实最后提交时used[i - 1] == false也行而used[i - 1] == true也行(也就是树层去重和树枝去重都可以),但是一般树层去重效率更高,遇到这种题就优先使用树层去重就可以了!
总结
1. 首先要搞懂排列和组合以及子集问题的区别:
首先排列是有序的,也就是说 [1,2] 和 [2,1] 是两个集合,这和之前分析的组合以及子集所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
大家此时可以感受出排列问题的不同:
(1)每层都是从0开始搜索而不是startIndex
(2) 排列问题需要一个used数组,标记已经选择的元素,而used数组,其实就是记录此时path里都有哪些元素使用了,一个排列里一个元素只能使用一次。
还要强调的是去重一定要对元素进行排序,这样我们才方便通过相邻的节点来判断是否重复使用了。
2. 树层去重最为关键的代码为:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false) continue;
大家在开始接触这个算法时很容易会迷惑,当nums[i] == nums[i - 1]时,used[i - 1] == false和used[i - 1] == true哪个代表树层去重哪个又代表树枝去重呢???
其实很容易理解:
根据之前回溯算法所讲,当需要遍历到上面树形图中某一个节点1的同一层的右侧节点时需要回溯退回到该节点的上一次父节点再向父节点的右下进行遍历该节点1的同一层的右侧节点
1. 因为回溯逻辑会对used数值的更新进行撤销,即调用backtracing函数的下一句代码used[i - 1] = false,所以树层去重一定对应used[i - 1] == false
2. 同理王深层树枝遍历是通过递归进行的,即先used[i - 1] = true,再调用backtracing(nums, used),此时used[i - 1] == true,所以树枝去重一定对应used[i - 1] == true
排列问题是回溯算法解决的经典题目,大家可以好好体会体会。
欢迎大家关注本人公众号:编程复盘与思考随笔
(关注后可以免费获得本人在csdn发布的资源源码)
公众号主要记录编程和刷题时的总结复盘笔记和心得!并且分享读书、工作、生活中的一些思考感悟!

















 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











