







文章目录
一、广度优先搜索
算法解释
浅显的解释:声波、水波纹扩散
广度优先搜索(BFS)不同于深度优先搜索,它是一层层进行遍历的,因此需要用先入先出的队列而非先入后出的栈进行遍历。由于是按照层次遍历,广度优先搜索时按照“广”的方向进行遍历,也常常用来处理最短路径等问题。
考虑如下一棵简单的树。我们从1号节点开始遍历,假如遍历顺序是从左子节点到右子节点,那么按照优先向着“广”的方向前进的策略,队列顶端的元素变化过程为【1】->【2->3】->【4】,其中方括号代表每一层的元素。
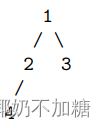
需要注意的是,深度优先搜索和广度优先搜索都可以处理可达性的问题,即从一个节点开始是否能达到另一个节点。因为深度优先搜索可以用递归快速实现,很多人会习惯使用深度优先搜索刷此类题目,但这在工程上并不常见。
用栈实现的深度优先搜索和用队列实现的广度优先搜索在写法上并没有较大的差异,可根据实际功能需求判断。
参考视频:https://www.bilibili.com/video/BV1GY4y1u7b2/?spm_id_from=333.999.0.0&vd_source=3d46a1fbf4fe486c92dd8f7d2cc0248d
代码框架
参考代码随想录的文章。
搜索过程的实现是通过什么容器呢?最常用的容器就是队列,但其实用栈也可以。针对类似岛屿问题的题目,BFS的代码框架是:
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que; // 定义队列
que.push({x, y}); // 起始节点加入队列
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
while(!que.empty()) { // 开始遍历队列里的元素
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
int curx = cur.first;
int cury = cur.second; // 当前节点坐标
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
if (!visited[nextx][nexty]) { // 如果节点没被访问过
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
}
}
}
}
934. 最短的桥
给你一个大小为 n x n 的二元矩阵 grid ,其中 1 表示陆地,0 表示水域。
岛 是由四面相连的 1 形成的一个最大组,即不会与非组内的任何其他 1 相连。grid 中 恰好存在两座岛 。
你可以将任意数量的 0 变为 1 ,以使两座岛连接起来,变成 一座岛 。
返回必须翻转的 0 的最小数目。
示例 1:
输入:grid = [[0,1],[1,0]]
输出:1
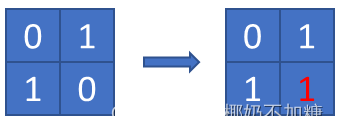
示例 2:
输入:grid = [[0,1,0],[0,0,0],[0,0,1]]
输出:2
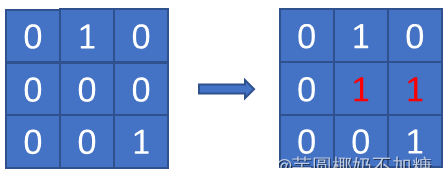
示例 3:
输入:grid = [[1,1,1,1,1],[1,0,0,0,1],[1,0,1,0,1],[1,0,0,0,1],[1,1,1,1,1]]
输出:1
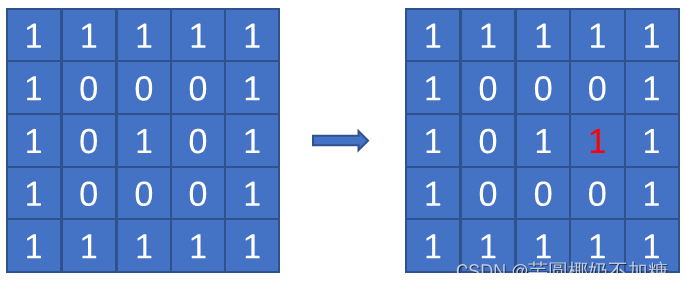
思路:
参考爪哇缪斯的题解。该解法其实是DFS+BFS。深度优先搜索先找到一个岛屿,然后利用广度优先搜索来一层层扩充,记录扩充的层数。
本题一开始看到的时候感觉和827.最大人工岛较为类似。但是仍有一些区别:
- 最大人工岛的岛屿数量不一定,而本题规定
grid中恰有2个岛屿; - 最大人工岛要求将一块海洋格子变为陆地格子得到最大的岛屿面积,而本题规定求出连通两个岛屿最短的桥。
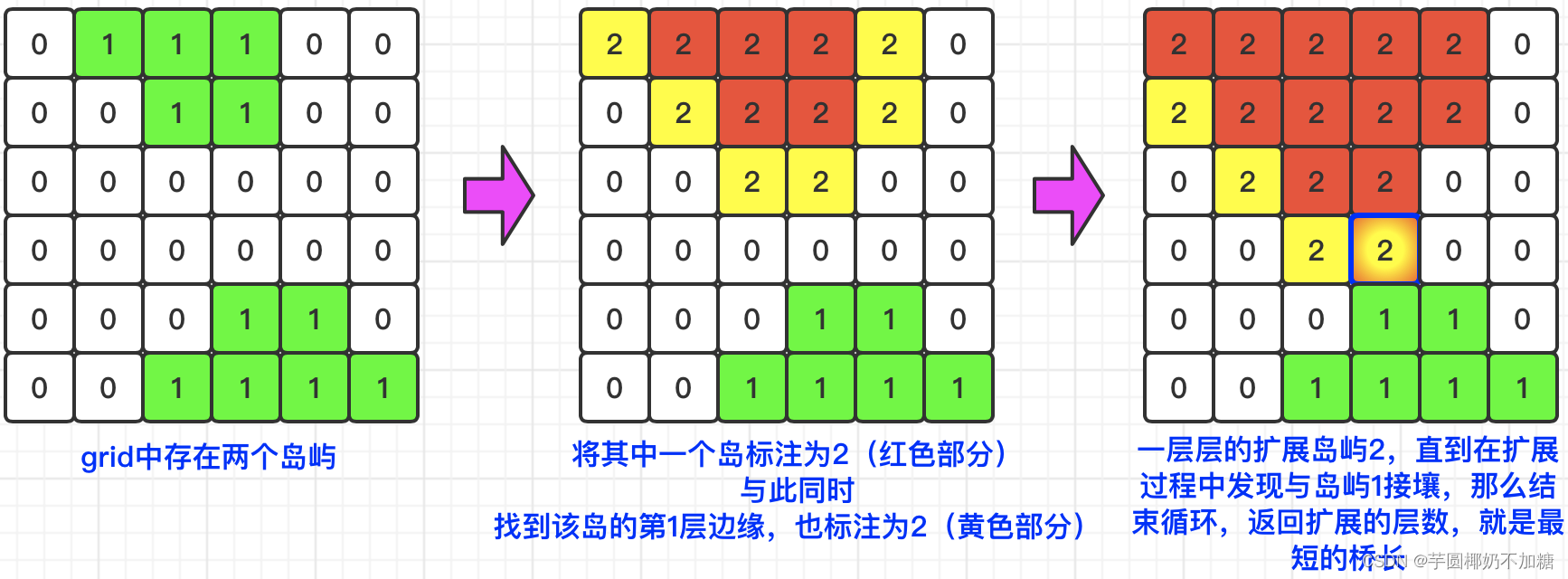
值得借鉴的是,最大人工岛中将不同岛屿编号为“2,3,4,......”,在这里我们也将遍历到的第一个岛屿编号为2。
在深度遍历时,若发现某个格子编号为0,说明已经遍历到岛屿的边缘部分,将其也赋值为2,与此同时,将这个边缘格子放到双向队列queue<pair<int, int>> edges,保存边缘格子的行和列。
接着开启while循环,即每次循环都根据edges中保存的这个岛屿的所有边缘格子对外进行一层的岛屿扩充操作:从edges中出队列每个边缘格子,再分别从上下左右四个方向去查相邻的格子,如果发现是0,表明是新的一层边缘格子,将其赋值为2,加入队列edges,用于下一次的while循环。
在一层层拓展之后,只要发现有边缘格子的四周出现了1,说明已经与另一个岛屿接壤了,返回拓展层数即可。
图解:
代码:
class Solution {
public:
int shortestBridge(vector<vector<int>>& grid) {
int ret = 0;//层数
vector<vector<int>> land = {{1,0}, {-1,0}, {0,1}, {0,-1}};
//先找到岛屿的所有边缘海域的位置
queue<pair<int, int>> edges;
findIsland1(grid, edges);
//逐步扩张海域边缘,直到遇到另外一座岛屿
while(!edges.empty()){
++ret;
int n = edges.size();
while(n--){
pair<int,int> coor = edges.front(); //返回队头元素
edges.pop();//出队操作
int i, j;
//向四个方向扩张
for (int k = 0;k < 4;k++){
//k = 0时 i = coor.first + 1, j = coor.second 下
//k = 1时 i = coor.first - 1, j = coor.second 上
//k = 2时 i = coor.first, j = coor.second + 1 右
//k = 3时 i = coor.first, j = coor.second - 1 左
i = coor.first + land[k][0];
j = coor.second + land[k][1];
//如果超出范围
if (i < 0 || i >= grid.size() || j < 0 || j >= grid[0].size()){
continue;
}
//岛内元素
else if (grid[i][j] == 2){
continue;
}
//边缘海域,插入队列并置为2
else if (grid[i][j] == 0){
edges.push(make_pair(i, j));
grid[i][j] = 2;
}
//遇到另一个岛屿
else if (grid[i][j] == 1){
return ret;
}
}
}
}
return 0;
}
private:
void findIsland1(vector<vector<int>>& grid, queue<pair<int, int>>& edges){
for (int r = 0;r < grid.size();r++){
for (int c = 0;c < grid[0].size();c++){
if (grid[r][c] == 1){
dfs(grid, r, c, edges);
return;
}
}
}
}
void dfs(vector<vector<int>>& grid, int r, int c, queue<pair<int, int>>& edges){
//超出范围
if (r < 0 || r >= grid.size() || c < 0 || c >= grid[0].size()){
return;
}
//边缘海域,插入队列,防止重复访问
if (grid[r][c] == 0){
edges.push(make_pair(r,c));//队列的插入操作
grid[r][c] = 2;
return;
}
else if (grid[r][c] == 2){
return;
}
//将岛屿每个格子赋值为2
grid[r][c] = 2;
dfs(grid, r+1, c, edges);
dfs(grid, r-1, c, edges);
dfs(grid, r, c+1, edges);
dfs(grid, r, c-1, edges);
}
};
127. 单词接龙
字典 wordList 中从单词 beginWord 和 endWord 的 转换序列 是一个按下述规格形成的序列 beginWord -> s1 -> s2 -> ... -> sk:
- 每一对相邻的单词只差一个字母。
- 对于
1 <= i <= k时,每个si都在wordList中。注意,beginWord不需要在wordList中。 sk == endWord
给你两个单词beginWord和endWord和一个字典wordList,返回 从beginWord到endWord的最短转换序列中的单词数目。如果不存在这样的转换序列,返回0。
示例 1:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”,“cog”]
输出:5
解释:一个最短转换序列是 “hit” -> “hot” -> “dot” -> “dog” -> “cog”, 返回它的长度 5。
示例 2:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”]
输出:0
解释:endWord “cog” 不在字典中,所以无法进行转换。
思路:
本题只需要用到BFS。
代码:
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
//将wordList转换为set 提高查找效率
unordered_set<string> words(wordList.begin(),wordList.end());
if (words.empty() || words.find(endWord) == words.end()) return 0;
words.erase(beginWord);
queue<string> que;
que.push(beginWord);
//改进:不需要visited,每个单词如果被访问到了就直接从words中删除就可以
unordered_set<string> visited;
visited.insert(beginWord);
int step = 1;
//标准BFS流程
while(!que.empty()){
//找到没有被访问过,而且能够由当前单词转换而成的单词
int n = que.size();
//每一轮(每一层step需要+1)
while(n--){
string curWord = que.front();
que.pop();
//当前单词的每个字符都替换成其他的另外25个字符,然后在单词表中查询是不是包含转换后的单词
//不选择遍历单词表的原因是:单词表可能很长,而哈希表使用的红黑树的查询效率比遍历单词表的效率高得多
for (int i = 0;i < curWord.size();i++){
//为了之后恢复成原单词
char originalChar = curWord[i];
for (int j = 0;j < 26;j++){
if (char('a' + j) == originalChar) continue;
curWord[i] = (char)('a' + j);
if (words.find(curWord) != words.end() && visited.find(curWord) == visited.end()){
if (curWord == endWord) return step + 1;
else{
que.push(curWord);
visited.insert(curWord);
}
}
}
curWord[i] = originalChar;
}
}
++step;
}
return 0;
}
};
126. 单词接龙 II (理解不全面)
按字典 wordList 完成从单词 beginWord 到单词 endWord 转化,一个表示此过程的 转换序列 是形式上像 beginWord -> s1 -> s2 -> ... -> sk 这样的单词序列,并满足:
-
每对相邻的单词之间仅有单个字母不同。
-
转换过程中的每个单词
si(1 <= i <= k)必须是字典wordList中的单词。注意,beginWord不必是字典wordList中的单词。 -
sk == endWord
给你两个单词beginWord和endWord,以及一个字典wordList。请你找出并返回所有从beginWord到endWord的最短转换序列,如果不存在这样的转换序列,返回一个空列表。每个序列都应该以单词列表[beginWord, s1, s2, ..., sk]的形式返回。
示例 1:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”,“cog”]
输出:[[“hit”,“hot”,“dot”,“dog”,“cog”],[“hit”,“hot”,“lot”,“log”,“cog”]]
解释:存在 2 种最短的转换序列:
“hit” -> “hot” -> “dot” -> “dog” -> “cog”
“hit” -> “hot” -> “lot” -> “log” -> “cog”
示例 2:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”]
输出:[]
解释:endWord “cog” 不在字典 wordList 中,所以不存在符合要求的转换序列。
思路:
参考liweiwei的题解。
题目要求我们找出 最短转换序列 ,需要使用 广度优先遍历 。但与绝大多数使用广度优先遍历只要求返回最短途径是多少的问题(如127.单词接龙)不同,本题要求返回 所有 从 beginWord 到 endWord 的最短转换序列,提示我们使用 深度优先遍历 + 回溯算法完成。
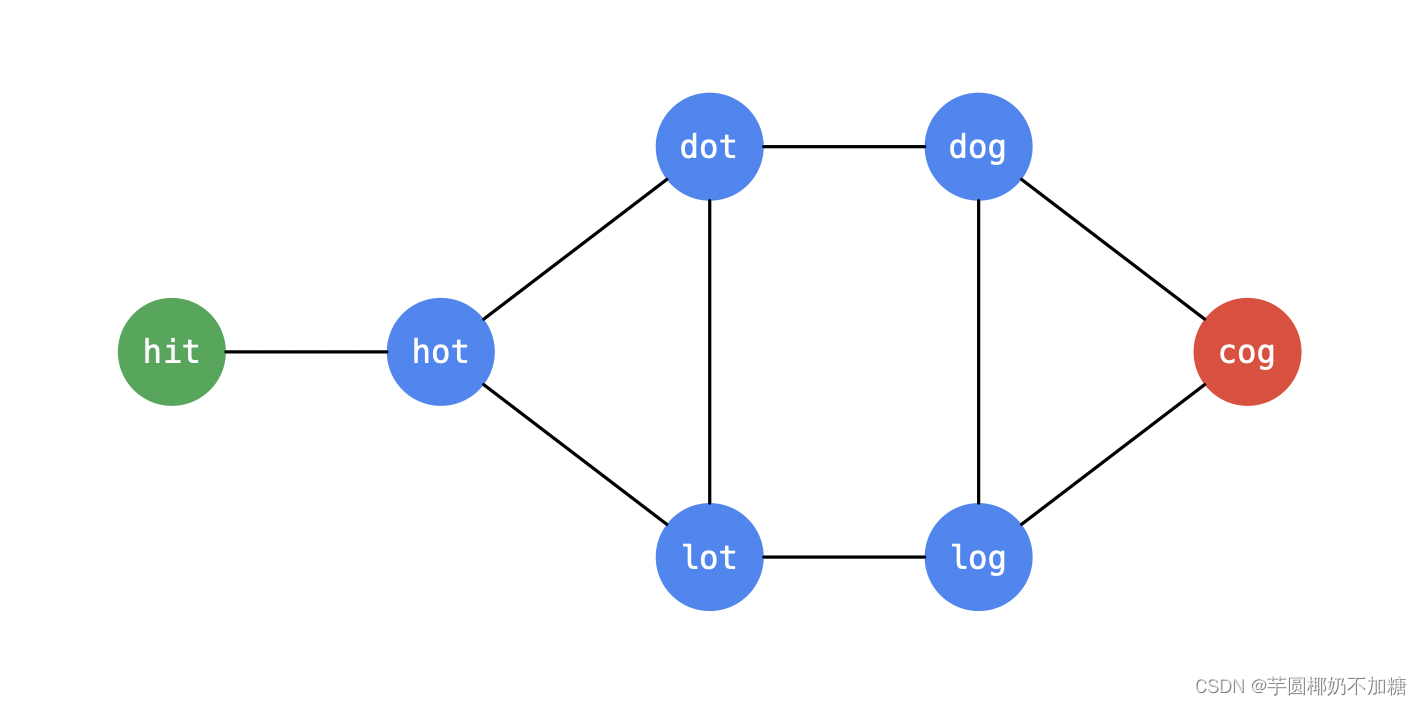
题目中的单词与单词之间可以构成一张无向无权图(两个单词有且只有一个字符不相等,若单词1可以转换为单词2,那么单词2一定可以转换为单词1;每个顶点之间的权重视为1),以示例1为例:
输入:beginWord = “hit”, endWord = “cog”, wordList = [“hot”,“dot”,“dog”,“lot”,“log”,“cog”]
转化为图为:
注意事项:
- 连接
dot和lot、dog和log的两条边不可以被记录下来,不符合最短路径的要求。
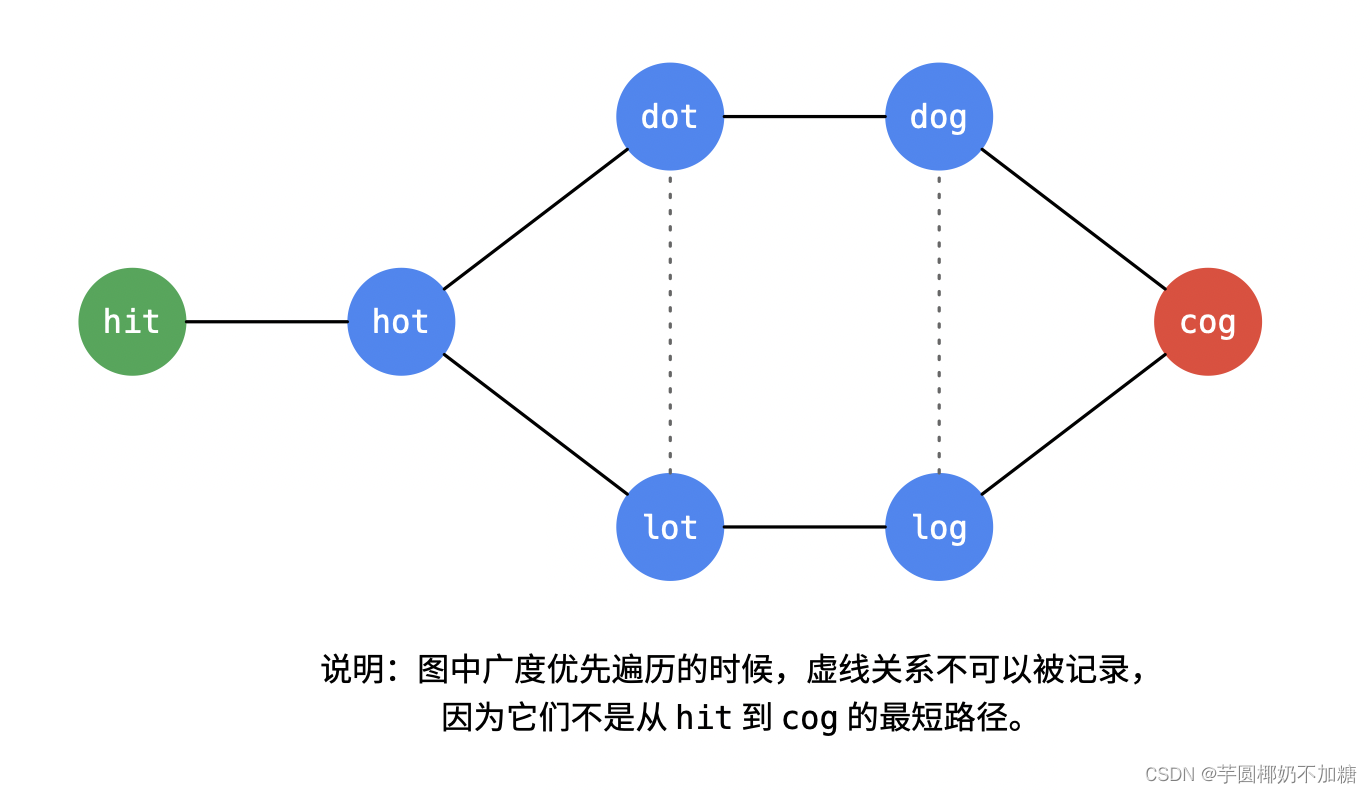
也就是说,位于广度优先遍历同一层的单词,如果它们之间有边连接,不可以记录下来。需要一个哈希表记录遍历到的单词在第几层。
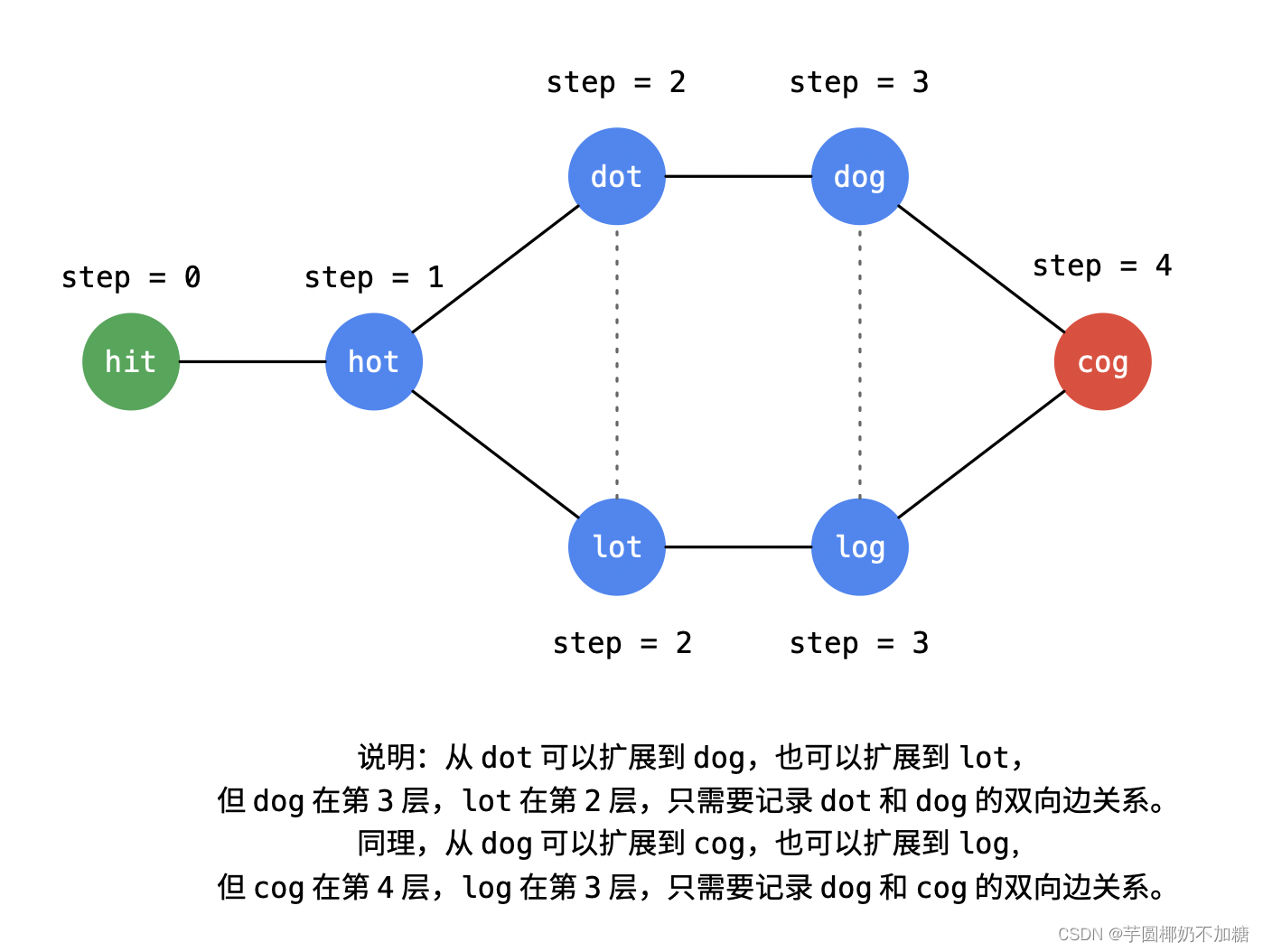
2. 在广度优先遍历的时候,我们需要记录:当前单词currWord到下一单词nextWord(相对于currWord只变化了一个字符,且在字典里)之间的单向关系,记为from。from是一个映射关系:键是单词,值是广度优先遍历时从哪些单词可以遍历到键所表示的单词,使用哈希表保存。这与之前提到的无向图似乎矛盾,但是由于广度优先遍历是有方向的,所以我们只能视为有向图。
补充知识:
unordered_set的相关知识点参照链接。
代码:
class Solution {
private:
//存放最短路径
unordered_map<string, int> table;
//存放通过相邻单词创建的有向图
unordered_map<string, unordered_set<string>> graph;
vector<vector<string>> ret;
//存储回溯算法中的单条路径,用来加入ret,其中元素的顺序为倒序,即从endWord到beginWord
vector<string> path;
//用全局变量存储beginWord,减少传参个数
string target;
public:
//思路:BFS找到最短路径的同时建图存储节点信息 + DFS回溯算法找到所有命中起点与终点的最短路径
void dfs(string s){
if (s == target){
//因为path中元素为倒序,所以想要颠倒过来需要用rbegin,rend
ret.emplace_back(path.rbegin(),path.rend());
return;
}
for (auto node : graph[s]){
path.emplace_back(node);
dfs(node);
path.pop_back();
}
}
vector<vector<string>> findLadders(string beginWord, string endWord, vector<string>& wordList) {
//由单词表创建哈希set减少查找的时间复杂度
unordered_set<string> set(wordList.begin(),wordList.end());//set是完全复制wordList
queue<string> q;
q.emplace(beginWord);//相当于push
//在开始时需要给beginWord设置初值0
table[beginWord] = 0;
int n = beginWord.size();
while(!q.empty()){
auto p = q.front();
q.pop();
//对每个单词的每个字母进行循环,对每个字母都尝试a-z的所有组合,来查找是否符合本题条件
for (int i = 0;i < n;i++){
auto nextWord = p;
//让p作为当前节点,nextWord作为下一个节点去探索新的字符组合
for (auto c = 'a';c <= 'z';c++){
nextWord[i] = c;
//对于每一种组合,存在于wordList并且从未遍历过或者和当前单词相邻(为了找到所有相邻节点)
if (set.count(nextWord) && (!table.count(nextWord) || table[nextWord] == table[p] + 1)){
//graph反向插入,有向边的顺序是从endWord到beginWord
graph[nextWord].emplace(p);
}
//如果是存在WordList并且从未遍历,那么就在最短路径中添加当前节点的相邻节点信息
if (set.count(nextWord) && !table.count(nextWord)){
table[nextWord] = table[p] + 1;
//如果正好遍历到了endWord,那么就终止循环剪枝
if (nextWord == endWord) break;
q.emplace(nextWord);
}
}
}
}
//如果没有找到,返回空vector
if (!table.count(endWord)) return ret;
//开始dfs寻找命中起点和终点的最短路径,需要先将endWord加进去(因为需要从尾到头找)
path.emplace_back(endWord);
target = beginWord;
dfs(endWord);
return ret;
}
};
130.被围绕的区域
给你一个 m x n 的矩阵 board ,由若干字符 'X'和 'O' ,找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例 1:
输入:board = [[“X”,“X”,“X”,“X”],[“X”,“O”,“O”,“X”],[“X”,“X”,“O”,“X”],[“X”,“O”,“X”,“X”]]
输出:[[“X”,“X”,“X”,“X”],[“X”,“X”,“X”,“X”],[“X”,“X”,“X”,“X”],[“X”,“O”,“X”,“X”]]
解释:被围绕的区间不会存在于边界上,换句话说,任何边界上的 ‘O’ 都不会被填充为 ‘X’。 任何不在边界上,或不与边界上的 ‘O’ 相连的 ‘O’ 最终都会被填充为 ‘X’。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
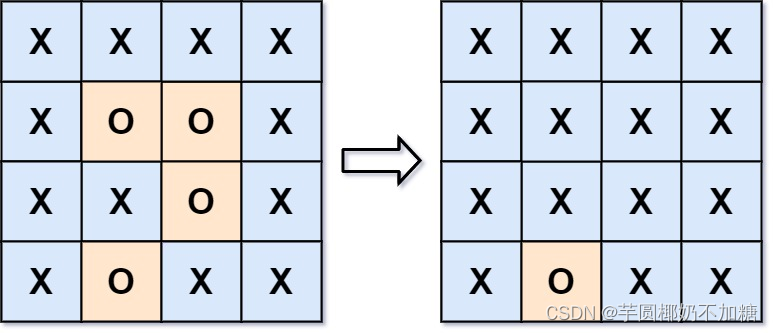
示例 2:
输入:board = [[“X”]]
输出:[[“X”]]
思路:
从矩阵的边界开始遍历,遇到周围相邻的'O'格子,用'A'替换,最后对替换完的矩阵进行遍历,将'A'格子用'O'替换,将'O'格子用'X'格子替换。
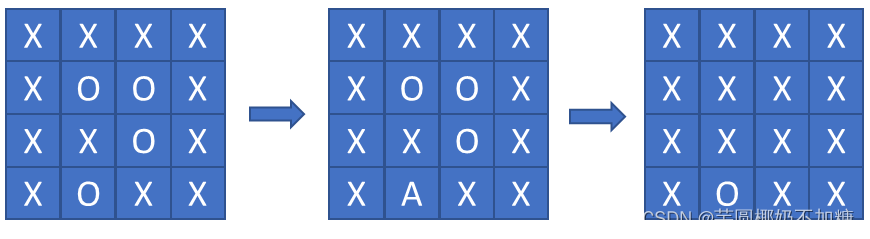
代码:
class Solution {
private:
int dir[4][2] = {-1,0,0,-1,1,0,0,1}; //保存四个方向
void dfs(vector<vector<char>>& board, int x, int y){
board[x][y] = 'A'; //将地图周边的'O'全部改成'A'
for (int i = 0; i < 4;i++){//向四个方向遍历
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
//判断是否超过边界
if (nextx < 0 || nextx >= board.size() || nexty < 0 || nexty >= board[0].size()) continue;
//不符合条件,继续遍历
if (board[nextx][nexty] == 'X' || board[nextx][nexty] == 'A') continue;
dfs(board,nextx,nexty);
}
return;
}
public:
void solve(vector<vector<char>>& board) {
//被围绕的区间不会存在于边界上,即任何边界上的'O'都不会被填充为'X'
//任何不在边界上,或者不与边界上的'O'相连的'O'最终都会被填充为'X'
//相连即为两个元素在水平或者垂直方向相邻
//思路:从地图周边出发,将周边空格相邻的'O'都做上标记,然后再遍历一遍地图,遇到'O'且没有做过标记的,即为地图中间的'O',全部改为'X'即可。
int n = board.size(), m = board[0].size();
//步骤1:从左侧边、右侧边向中间遍历
for (int i = 0; i < n; i++){
if (board[i][0] == 'O') dfs(board,i,0);
if (board[i][m-1] == 'O') dfs(board,i,m-1);
}
//从上侧边、下侧边向中间遍历
for (int j = 0; j < m; j++){
if (board[0][j] == 'O') dfs(board,0,j);
if (board[n-1][j] == 'O') dfs(board,n-1,j);
}
//步骤2:遍历地图,将'O'全部改成'X'(地图中间的'O'改成了'X'),将'A'改回'O'(保留的地图周边的'O')
for (int i = 0; i < n; i++){
for (int j = 0; j < m; j++){
if (board[i][j] == 'O') board[i][j] = 'X';
if (board[i][j] == 'A') board[i][j] = 'O';
}
}
}
};
1020.飞地的数量
给你一个大小为 m x n 的二进制矩阵 grid ,其中 0 表示一个海洋单元格、1 表示一个陆地单元格。
一次 移动 是指从一个陆地单元格走到另一个相邻(上、下、左、右)的陆地单元格或跨过 grid 的边界。
返回网格中 无法 在任意次数的移动中离开网格边界的陆地单元格的数量。
示例 1:
输入:grid = [[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]]
输出:3
解释:有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。
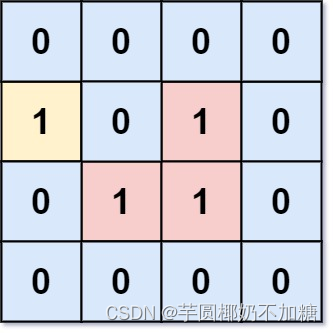
示例 2:
输入:grid = [[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]]
输出:0
解释:所有 1 都在边界上或可以到达边界。
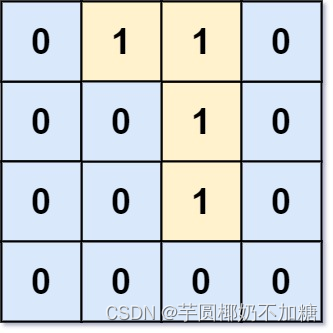
思路:
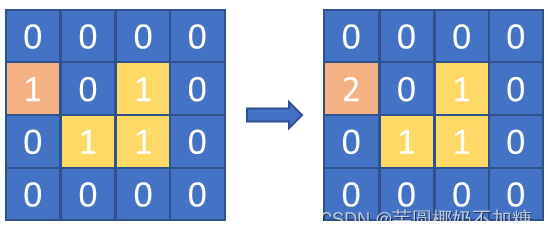
从边界开始遍历,遇到周围相邻的1格子将其变为2,最后遍历改变后的矩阵,最终找1的数量即可。
代码:
class Solution {
//思路:从边界开始遍历,遇到周围相邻的1格子将其变为2,最后遍历改变后的矩阵,记录1的数量
private:
int dir[4][2] = {-1,0,0,1,1,0,0,-1};
void dfs(vector<vector<int>>& grid, int x, int y){
grid[x][y] = 2;
for (int i = 0; i < 4; i++){
int nextx = x + dir[i][0];
int nexty = y + dir[i][1];
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue;
if (grid[nextx][nexty] == 0 || grid[nextx][nexty] == 2) continue;
dfs(grid,nextx,nexty);
}
return;
}
public:
int numEnclaves(vector<vector<int>>& grid) {
int n = grid.size(), m = grid[0].size();
int num = 0;
//左右
for (int i = 0; i < n; i++){
if (grid[i][0] == 1) dfs(grid,i,0);
if (grid[i][m-1] == 1) dfs(grid,i,m-1);
}
//上下
for (int j = 0; j < m; j++){
if (grid[0][j] == 1) dfs(grid,0,j);
if (grid[n-1][j] == 1) dfs(grid,n-1,j);
}
for (int i = 0; i < n; i++){
for (int j = 0; j < m; j++){
if (grid[i][j] == 1) num++;
}
}
return num;
}
};
257.二叉树的所有路径
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。
叶子节点 是指没有子节点的节点。
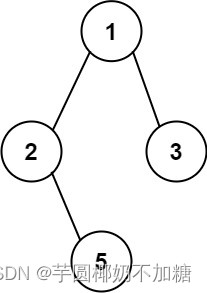
示例 1:
输入:root = [1,2,3,null,5]
输出:[“1->2->5”,“1->3”]
示例 2:
输入:root = [1]
输出:[“1”]
思路:
根据代码随想录的第一种解题思路,采用递归+回溯的方法。
前中后序遍历
前序(Preorder)、中序(Inorder)、后序(Postorder)的区别:
三者都基于DFS,唯一的区别是在遍历的过程中,它们什么时候会访问一个节点的内容。
因为对于二叉树,一个节点实际上被访问了3次,包括第一次DFS调用之前、每次DFS调用之后。
如中序遍历也是先访问根节点,再左子树,最后右子树,只是将**do something with root(对节点进行处理)**放在访问完左子树之后。
Preorder, Postorder and Inorder are all based on DFS.
The only difference is:
During the traversal, what time they will access the content of a node.
Because a node is actually visited 3 times for binary tree. They include: the time before the first DFS call, and the times after each DFS call.
前序遍历在第一次访问节点时访问节点的内容(在它的左孩子的 DFS 之前)。 它的实现如下:
The preorder traversal accesses the content of a node when it is first visited (before the DFS on his left child). It is implemented as follows:
Preorder (root) {
1. access content of root
2. Call Preorder(root.left)
3. Call Preorder(root.right)
}
后序遍历访问最后一次访问节点时的内容(在两个子节点上的 DFS 之后)。 它的实现如下:
The postorder traversal accesses the content of a node when it is last visited (after the DFS on both children). It is implemented as follows :
Postorder (root) {
1. Call Postorder(root.left)
2. Call Postorder(root.right)
3. access content of root
}
中序遍历在访问右孩子之前访问节点的内容, 实现如下:
The inorder traversal accesses the content of a node just before we visit right child. It is implemented as follows
Inorder (root) {
1. Call Inorder(root.left)
2. access content of root
3. Call Inorder(root.right)
}
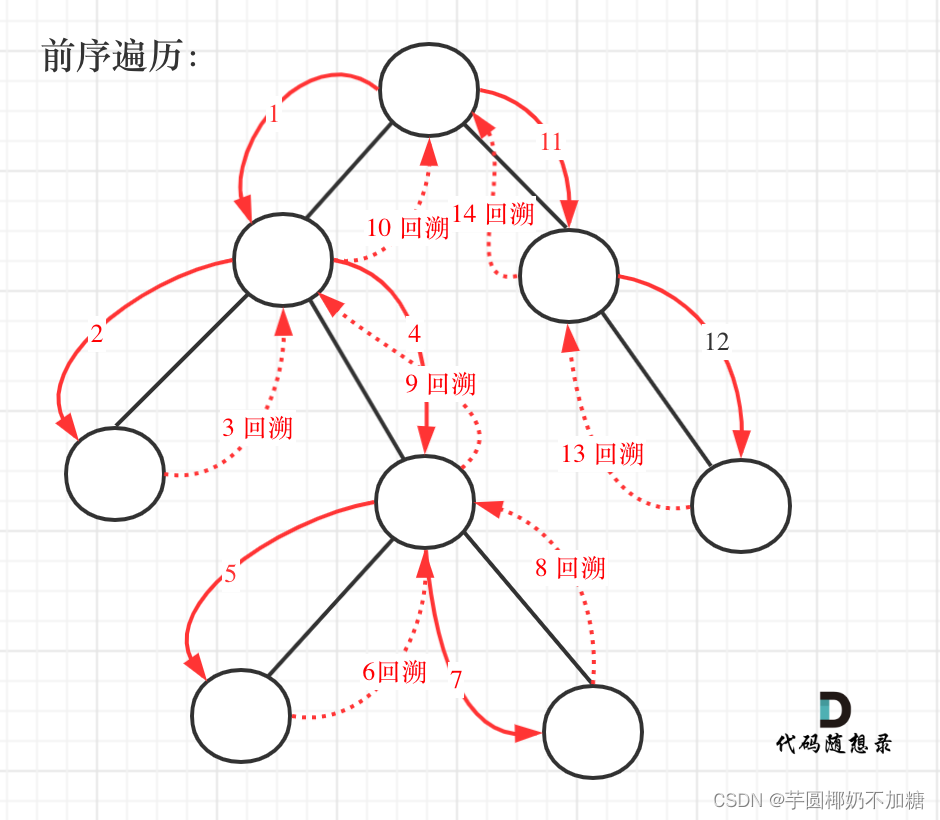
本题采用的遍历顺序为前序遍历,如下图所示:
- 确定函数参数:需要传入根节点、记录每条路径的path、存放结果集的result、不需要返回值;
- 确定递归终止条件:找到了叶子节点(没有子节点的节点),即当cur不为空,其左右子节点都为空的时候;
if(cur->left == NULL && cur->right == NULL){
//终止处理逻辑:将path里记录的路径转换为string格式
}
- 确定单层递归逻辑
前序遍历,先处理中间节点,放进path中,然后进行递归和回溯。
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
private:
void traversal(TreeNode* cur, vector<int>& path, vector<string>& result){
//前序遍历:中左右
path.push_back(cur->val);//中,中写在这里的原因是最后一个节点也要加入path中
//此时才到了叶子节点
if(cur->left == NULL && cur->right == NULL) {
string sPath;
for (int i = 0; i < path.size() - 1; i++){
sPath += to_string(path[i]);//to_string作用是把数值类型如int、double、long等转化为string
sPath += "->";
}
sPath += to_string(path[path.size() - 1]);
result.push_back(sPath);
return;
}
if(cur->left){ //左
traversal(cur->left, path, result);
path.pop_back(); //回溯
}
if(cur->right){ //左
traversal(cur->right, path, result);
path.pop_back(); //回溯
}
}
public:
vector<string> binaryTreePaths(TreeNode* root) {
vector<string> result;//存储结果
vector<int> path;//存储单条路径
if(root == NULL) return result;
traversal(root, path, result);
return result;
}
};
310. 最小高度树
树是一个无向图,其中任何两个顶点只通过一条路径连接。 换句话说,一个任何没有简单环路的连通图都是一棵树。
给你一棵包含 n 个节点的树,标记为 0 到 n - 1 。给定数字 n 和一个有 n - 1 条无向边的 edges 列表(每一个边都是一对标签),其中 edges[i] = [ai, bi] 表示树中节点 ai 和 bi 之间存在一条无向边。
可选择树中任何一个节点作为根。当选择节点 x 作为根节点时,设结果树的高度为 h 。在所有可能的树中,具有最小高度的树(即,min(h))被称为 最小高度树 。
请你找到所有的 最小高度树 并按 任意顺序 返回它们的根节点标签列表。
树的 高度 是指根节点和叶子节点之间最长向下路径上边的数量。
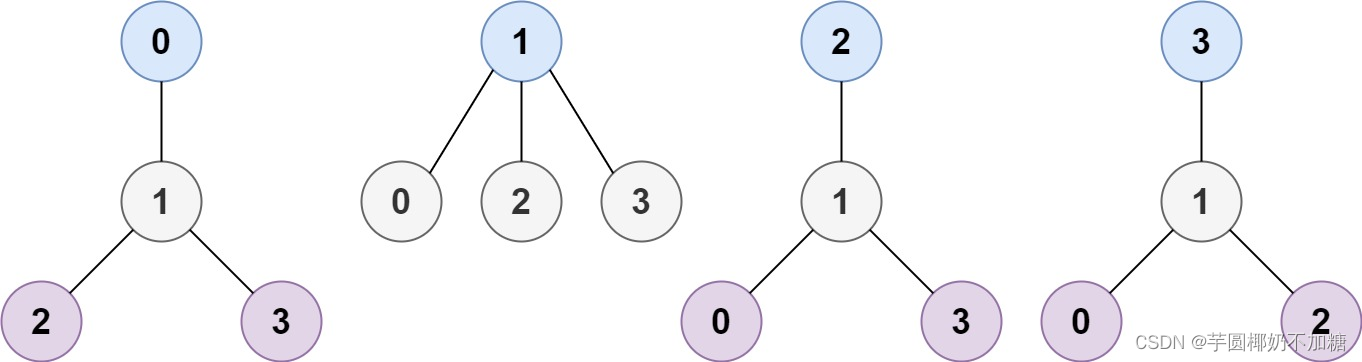
示例 1:
输入:n = 4, edges = [[1,0],[1,2],[1,3]]
输出:[1]
解释:如图所示,当根是标签为 1 的节点时,树的高度是 1 ,这是唯一的最小高度树。
示例 2:
输入:n = 6, edges = [[3,0],[3,1],[3,2],[3,4],[5,4]]
输出:[3,4]
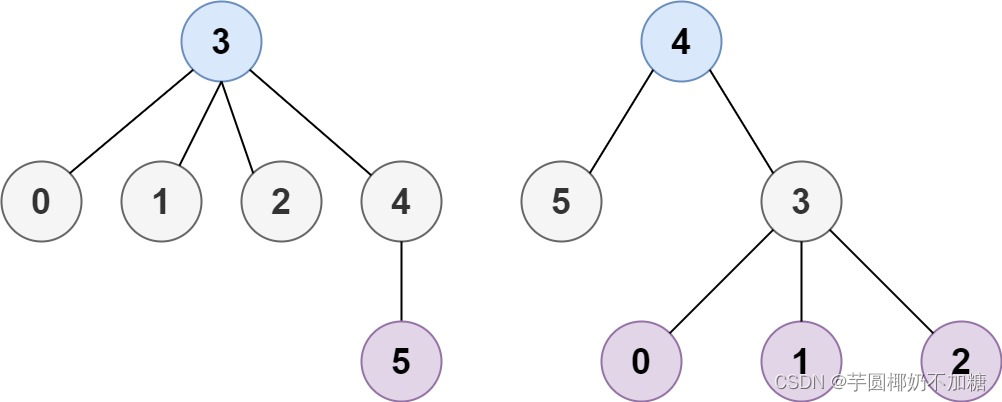
无向图
v
v
v的出度
d
+
(
v
)
d^+(v)
d+(v):v作为边的始点次数之和
v的入度
d
−
(
v
)
d^-(v)
d−(v):v作为边的终点次数之和
v的度数(度)
d
(
v
)
d(v)
d(v):v作为边的端点次数之和
i-- 表示先取值,再运算;--i表示先运算,再取值。
思路:
从所有的叶子节点一层层往里面找,找到最中间的节点就是所求最小高度树的根节点。
采用BFS。注意特殊情况。
图解:
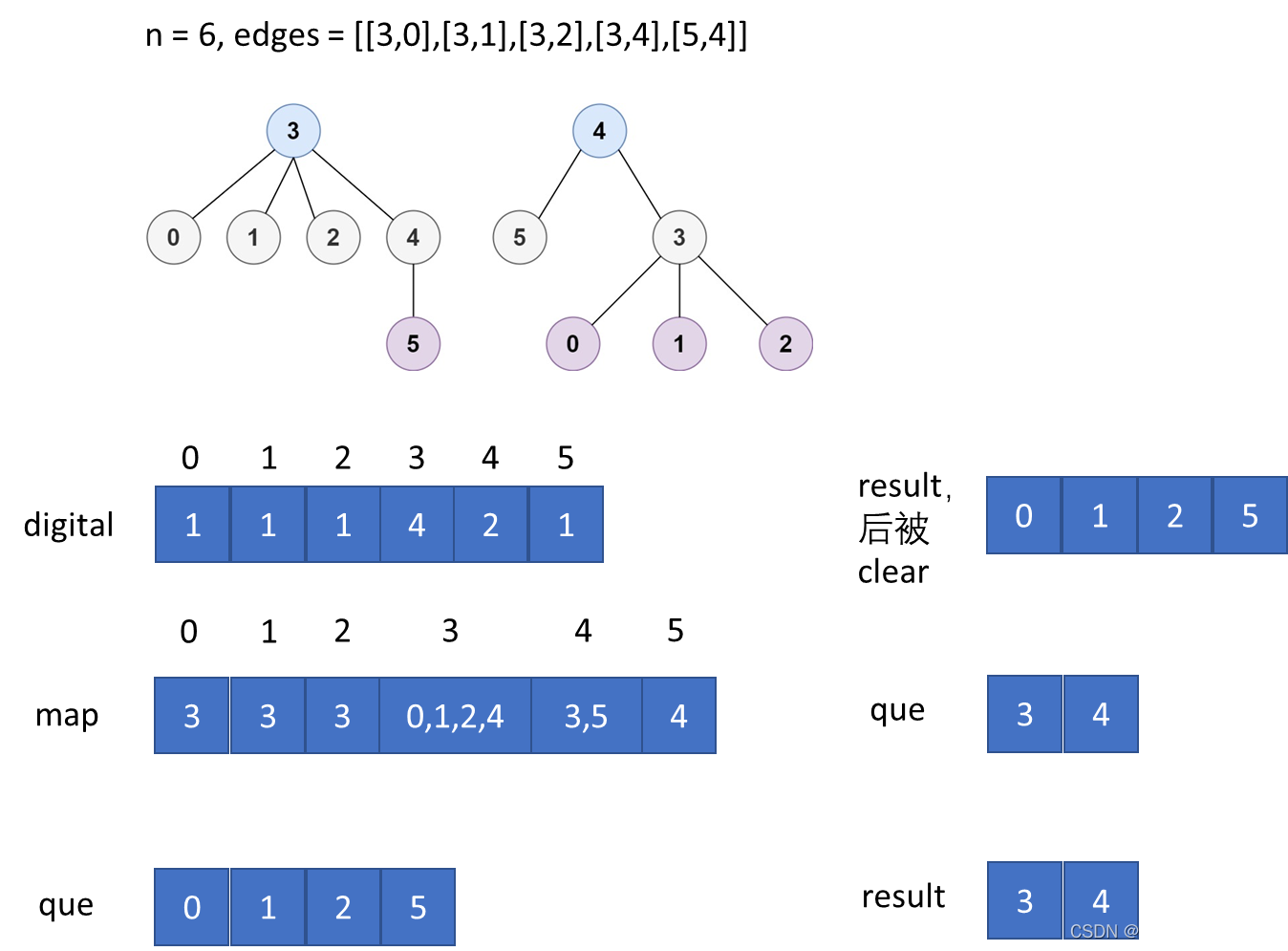
代码:
// BFS
//
// 越是靠里面的节点越有可能是最小高度树。
// 从边缘开始,先找到所有出度为1的节点(相连结点数为1),然后把所有出度为1的节点进队列,然后不断地bfs,最后找到的就是两边同时向中间靠近的节点,也就是到其他叶子节点最近的节点。
// 从外向内,一层一层剥离,得到的"最里层结点"就是目标结果
class Solution {
private:
vector<int> result;
public:
vector<int> findMinHeightTrees(int n, vector<vector<int>>& edges) {
if (n == 1) {
return { 0 };
}
vector<int> digital(n, 0); // 建立每个结点对应的度 (相连结点的个数)
vector<vector<int>> map(n); // 建立邻接表 (与其相连的结点的集合)
for (int i = 0; i < edges.size(); ++i) {
// 每个结点对应的度+1
++digital[edges[i][0]];//先遍历edges第一列的节点
++digital[edges[i][1]];
// 建立"每个结点相连的结点"组成的表
map[edges[i][0]].push_back(edges[i][1]);
map[edges[i][1]].push_back(edges[i][0]);
}
queue<int> que;
// 队列中存放外层叶子结点
for (int i = 0; i < n; ++i) {
if (digital[i] == 1) { // 叶子结点
que.push(i);
}
}
while (!que.empty()) {
result.clear(); // 更新result (如果不是最里层结点,就会被抛弃)
int size = que.size();
// 让外层叶子结点出队 (相当于剪去最外层叶子结点,从而露出新的叶子结点,即里层一点的结点)
while (size--) { // 经过第一轮的while循环 digital[3] = 1 digital[4] = 1
int leaft = que.front();
que.pop(); // 剪去该层叶子结点
result.push_back(leaft); // 将该层叶子结点加入结果,如果不是最里层,还是会清空的。直到找到最里层叶子结点,即结果
// 更新与 "被剪去的叶子结点" 相连的结点,如果因为该叶子结点被剪去,而使得其相连结点为"叶子结点",则将其相连结点入队 (一圈一圈剪,最终得到最里层,即结果)
for (auto lef : map[leaft]) {
--digital[lef];
if (digital[lef] == 1) {
que.push(lef);
}
}
}
}
return result;
}
};















 1428
1428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









