






目录
相关链接
- 【官】statements_4005 ANALYZE
- 1.Excel目录
- 2.如何找到Oralce存储过程——官方文档
- 3. Oracle执行计划之2_统计信息(Statistic)
- 4. 142-10 SYS.DBMS_STATS.delete_column_stats
- 5. 142-12 SYS.DBMS_STATS.delete_database_stats
- 6. 142-15 SYS.DBMS_STATS.delete_index_stats
- 7. 142-18 SYS.DBMS_STATS.delete_schema_stats
- 8. 142-21 SYS.DBMS_STATS.delete_table_stats
- 9. 142-39 SYS.DBMS_STATS.gather_database_stats
- 10. 142-42 SYS.DBMS_STATS.gather_index_stats
- 11. 142-43 SYS.DBMS_STATS.gather_schema_stats
- 12. 142-45 SYS.DBMS_STATS.gather_table_stats
- 13. 142-87 SYS.DBMS_STATS.set_column_stats
- 14. 142-90 SYS.DBMS_STATS.set_index_stats
- 15. 142-95 SYS.DBMS_STATS.set_table_stats
Summarize 总结
| Cpt 章节 | Classify_1st 1级分类 | Cly_2nd 2级分类 | Clf_3rd 3级分类 | Clf_4th 4级分类 | Function 功能介绍 | Example 演示用例 |
|---|---|---|---|---|---|---|
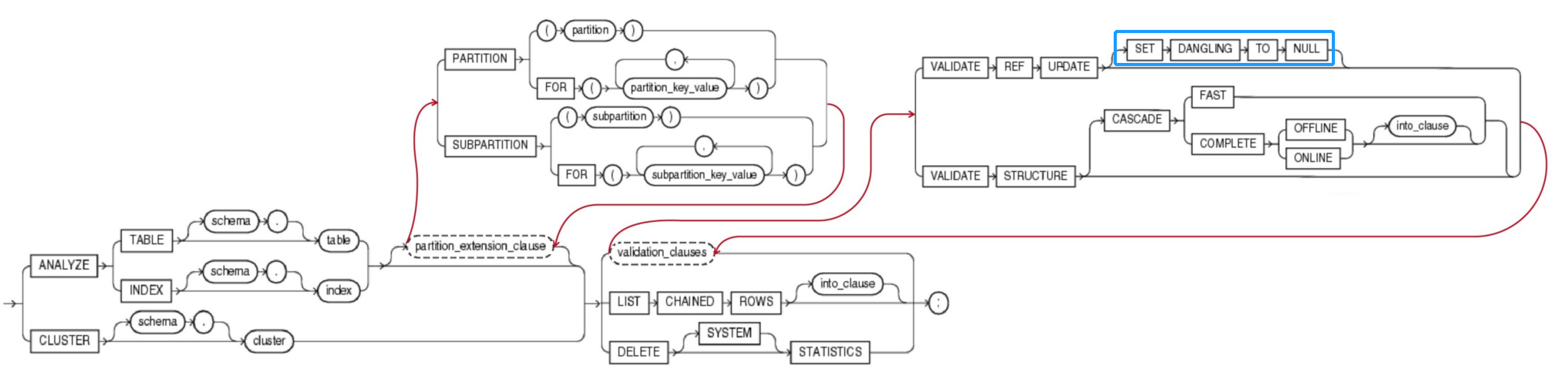
| 5 | 扩展分区子句 partition_extension_clause | - | - | - | partition_extension_clause 用来收集分区(partition)、子分区(subpartition)、分区值(partition value)、子分区值(subpartition value)相关统计信息,不可用于簇(cluster)。 | None |
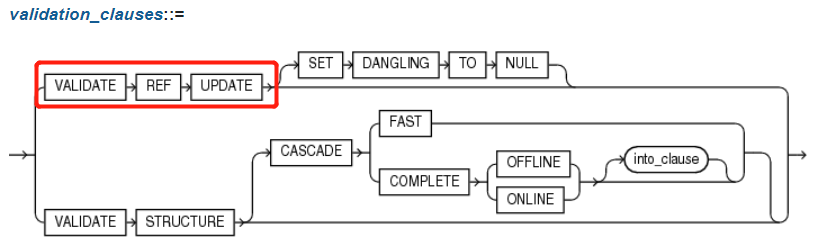
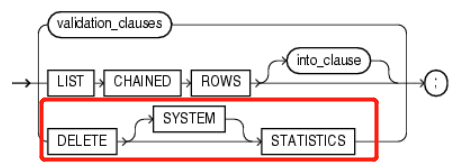
| 6 | 校验有效性的子句 validation_clauses | - | - | - | validation_clauses 用来检查各种隐患问题及错误信息。 | As follows: |
| 6.1 | 校验有效性的子句 validation_clauses | 校验游标有效性 VALIDATE REF UPDATE | - | - | VALIDATE REF UPDATE 使用关键字VALIDATE STRUCTURE校验,校验表(table)、索引(index)、簇(cluster)或物化视图(materialized view)结构的完整性。 | ANALYZE TABLE customers VALIDATE REF UPDATE; |
| 6.1.1 | 校验有效性的子句 validation_clauses | 校验游标有效性 VALIDATE REF UPDATE | 无效指针置空 SET DANGLING TO NULL | - | SET DANGLING TO NULL 校验出的那些无效游标(REF),那些指针指向了错误地址(rowid),表中找不到值的游标值都修改为NULL值。这样可以节省存储空间,加快查询效率。 | None |
| 6.2 | 校验有效性的子句 validation_clauses | 校验对象的结构是否有效 VALIDATE STRUCTURE | - | - | VALIDATE STRUCTURE 校验Analyze对象的结构是否有效。对象包括 表(table)、索引(index)、簇(cluster)、分区表(partitioned table)、临时表(temporary table)。 | ANALYZE INDEX inv_product_ix VALIDATE STRUCTURE; |
| 6.2.1 | 校验有效性的子句 validation_clauses | 校验游标有效性 VALIDATE STRUCTURE | CASCADE | - | CASCADE 级联模式,满门抄斩。添加 CASCADE 关键字可以同时校验指定对象所依赖的上游对象。校验对象多也会消耗大量资源。 | ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE; ------------ ANALYZE CLUSTER personnel VALIDATE STRUCTURE CASCADE; |
| 6.2.1+ | 校验有效性的子句 validation_clauses | 校验游标有效性 VALIDATE STRUCTURE | CASCADE | FAST | CASCADE FAST 快速优化模式。使用CASECADE校验会消耗大量资源。添加 FAST 关键字使用优化的检查算法来检查是否存在损坏,但是不报告有关损坏的细节。 | ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE FAST; |
| 6.2.1.1 | 校验有效性的子句 validation_clauses | 校验游标有效性 VALIDATE STRUCTURE | CASCADE COMPLETE | ONLINE OFFLINE | CASCADE COMPLETE ONLINE | OFFLINEdefault 指定 COMPLETE + ONLINE | OFFLINE关键字二选一可以选择在线/离线模式。 在线模式不会收集统计信息,不可用于簇(cluster)。 离线模式会校验结构的有效性,还会收集统计信息,而且在校验期间会锁表。 如果不指定默认模式是离线模式。 | ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE ONLINE; |
| 7 | INTO子句 into_clause | - | - | - | into_clause 指定输出检查结果到某个表中。可以省略。 ● 如果在 ⑧ LIST CHAINED ROWS 子句后面省略INTO子句,则校验结果默认输出到 INVALID_ROWS 表( INVALID_ROWS表 通过UTLVALID.SQL创建)。 ● 如果在 VALIDATE STRUCTRUE 子句后面省略INTO子句,则校验结果默认输出到CHAIN_ROWS 表 ( CHAIN_ROWS表 通过UTLCHAIN.SQL 或 UTLCHAIN1.SQL创建)。 | ANALYZE TABLE orders LIST CHAINED ROWS INTO chained_rows; |
| 8 | 检查行链接子句 LIST CHAINED ROWS 关于消除行链接及行迁移的方法 | - | - | - | LIST CHAINED ROWS 检查行链接子句(LIST CHAINED ROWS)分析表(table)或簇(cluster)中的迁移行(Migrated Rows)、链接行(Chained Rows)。检查行链接,消除行链接后可以提升性能。 | ANALYZE TABLE orders LIST CHAINED ROWS INTO chained_rows; |
| 9 | 删除统计信息子句 DELETE STATISTICS | - | - | - | DELETE STATISTICS 删除统计信息,这样Oracle生产执行计划时就没有信息可以参考。 | ANALYZE TABLE orders DELETE STATISTICS ; |
| - | 全表扫描 COMPUTE STATISTICS | - | - | - | COMPUTE STATISTICS 全表扫描是相对于抽样算法的概念,表示分析分析表时要读取表中所有数据。 | ANALYZE TABLE hr.employees COMPUTE STATISTICS; |
| - | 抽样算法 ESTIMATE STATISTICS SAMPLE xx PERCENT | - | - | - | ESTIMATE STATISTICS SAMPLE xx PERCENT xx表示0~100的数字。指定采样的比例,全表采样消耗资源更多,使用抽样算法按比例采样可以节省资源,但估算值可能不准确,最终导致执行计划也不准确。 | ANALYZE TABLE hr.employees ESTIMATE STATISTICS SAMPLE 10 PERCENT; |
关于 全表扫描 和 抽样算法 的语法来自网上,在Oracle官方文档中还未找到相关描述。
From SQL Statements: ALTER TRIGGER to COMMIT => statements_4005 ANALYZE
一、Purpose 目的
Use the ANALYZE statement to collect statistics, for example, to:
使用ANALYZE语句来收集统计信息,例如:
- Collect or delete statistics about an index or index partition, table or table partition, index-organized table, cluster, or scalar object attribute.
收集或删除以下统计信息:
索引(index)或索引分区(index partition)、
表(table)或表分区(table partition)、
索引组织的表(ndex-organized table)、
集群(cluster)或标量对象属性(scalar object attribute) - Validate the structure of an index or index partition, table or table partition, index-organized table, cluster, or object reference (REF).
校验以下对象的结构:
索引(structure )或索引分区(index partition)、
表(table)或表分区(table partition)、
索引组织的表(index-organized table)、
集群(cluster)或对象引用(REF)(object reference (REF)) - Identify migrated and chained rows of a table or cluster.
找出表(Table)/簇(Cluster)中 行迁移(Row Migration)/行链接(Row Chained)的行。
✎ Note:
:::::::::::::::::::::::::
For the collection of most statistics, use the DBMS_STATS package, which lets you collect statistics in parallel, collect global statistics for partitioned objects, and fine tune your statistics collection in other ways. See Oracle Database PL/SQL Packages and Types Reference for more information on the DBMS_STATS package.
大多数情况下,可以使用DBMS_STATS包(并行收集、收集分区对象的全局统计信息、其他方式优化)
- Use the ANALYZE statement (rather than DBMS_STATS) for statistics collection not related to the cost-based optimizer:
对于大多数统计信息的收集,可以使用DBMS_STATS包,DBMS_STATS可以并行收集统计信息、收集分区对象的全局统计信息,并以其他方式优化统计信息收集。有关DBMS_STATS包的更多信息,请参阅 Oracle数据库PL/SQL包和类型 。- To use the Validate1 or LIST Chained Rows2 clauses
使用 校验有效性子句(VALIDATE_CLAUSE) 或 行链接列表(LIST CHAINED ROWS)。
- To collect information on Freelist3 blocks
收集关于 自由列表块(freelist) 的信息
二、Prerequisites 前提条件
The schema object to be analyzed must be local, and it must be in your own schema or you must have the ANALYZE ANY system privilege.
要分析的模式(Schema)对象必须是本地的,并且在自己的模式(Schema)中,或者拥有 ANALYZE ANY 系统权限。
If you want to list chained rows of a table or cluster into a list table, then the list table must be in your own schema, or you must have INSERT privilege on the list table, or you must have INSERT ANY TABLE system privilege.
如果希望将表或集群中的迁移行(chained rows)列出到列表表中,列表表(list table)必须在自己的模式(Schema)中,或者对列表表(list table)具有INSERT特权,或者具有 INSERT ANY TABLE 系统权限。
If you want to validate a Partitioned Table4 , then you must have the INSERT object privilege on the table into which you list analyzed rowids, or you must have the INSERT ANY TABLE system privilege.
如果要校验 分区表(Partition Table) ,那么必须对列出已分析行的表具有 INSERT 对象权限,或者 INSERT ANY TABLE 系统权限。
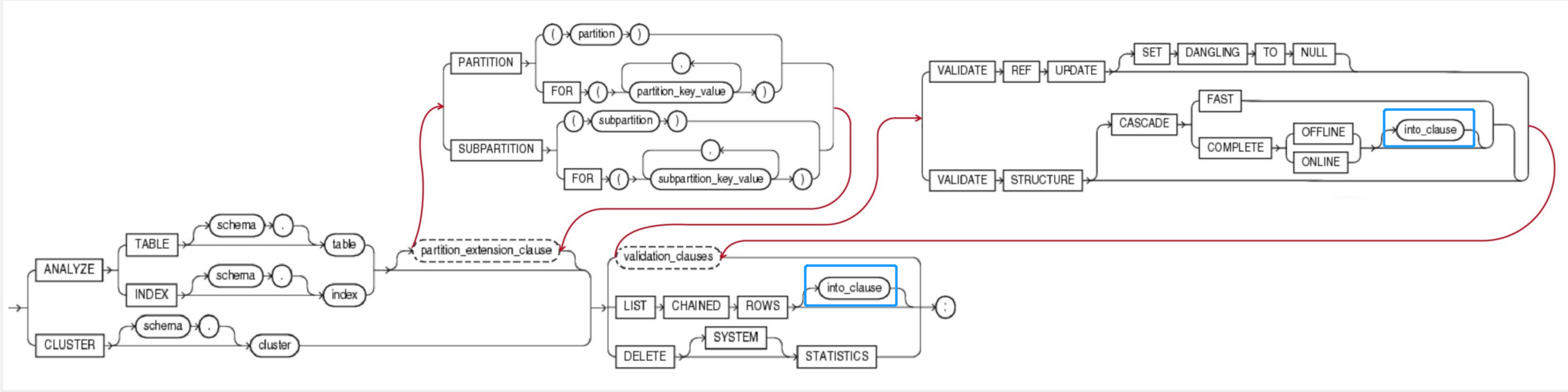
三、Syntax 语法树
3.1 analyze(分析)
- 使用analyze基础语句,来收集/删除表(table),索引(index),簇(cluster)等统计信息(Statistic),用于生成执行计划。
- Analyze基础语法搭配不同分支子句可以实现不同功能。
具体语法结构如下:
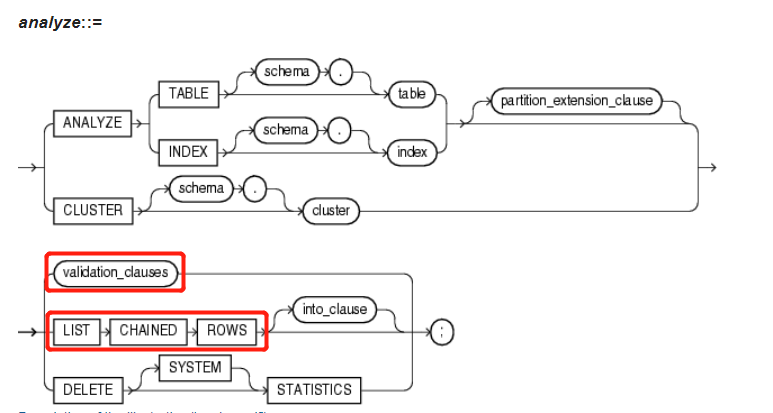
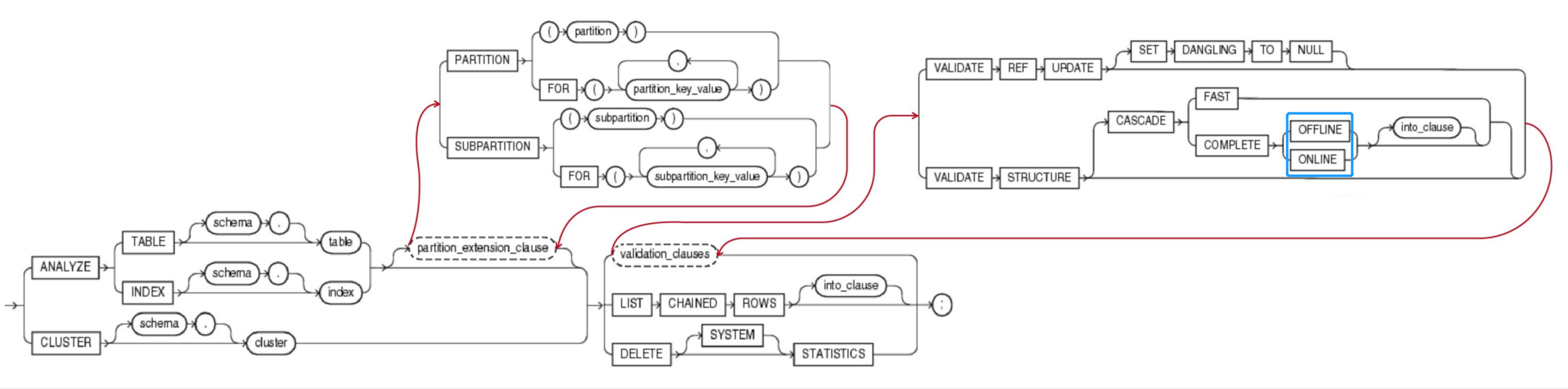
analyze::=5
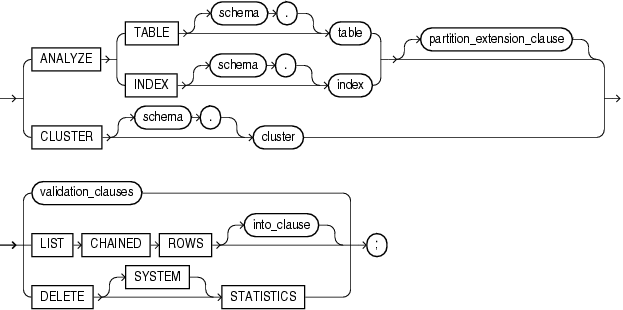
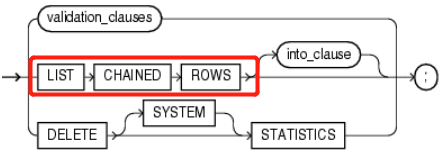
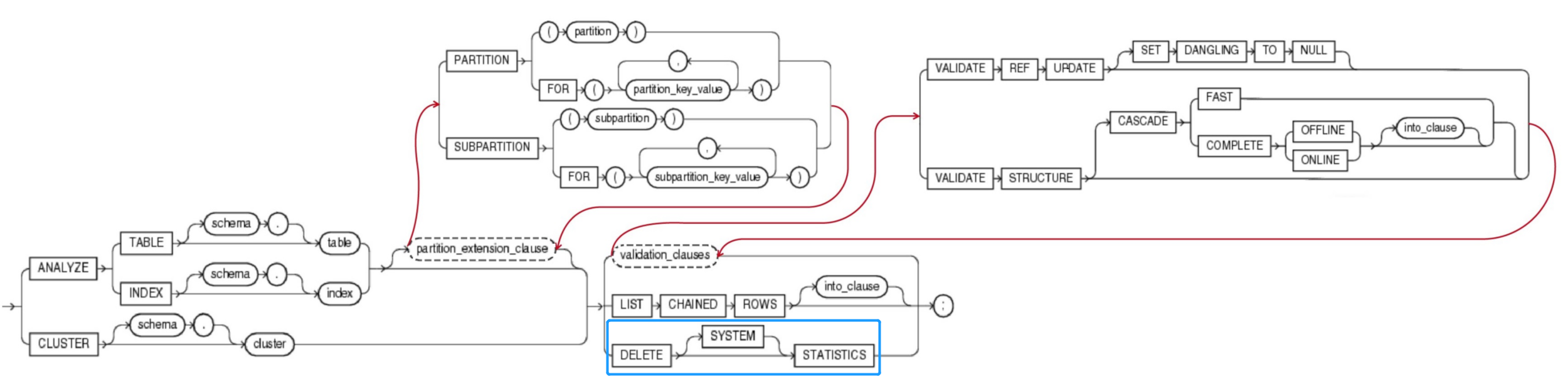
ANALYZE
{ { TABLE [ schema. ] table
| INDEX [ schema. ] index
} [ partition_extension_clause ] --详见3.2 partition_extension_clause 扩展分区子句
| CLUSTER [ schema. ] cluster
}
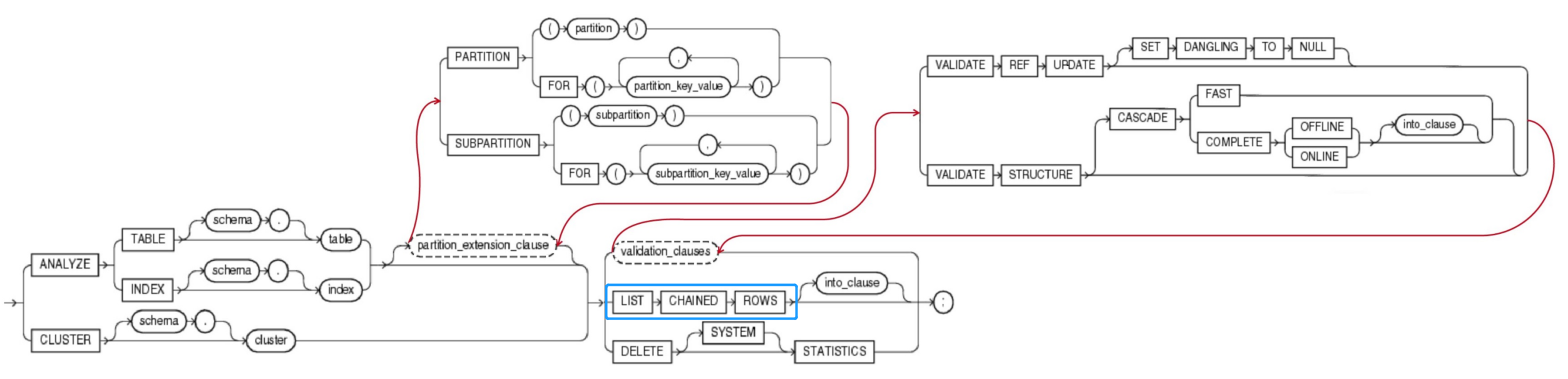
{ validation_clauses --详见4.5 validation_clauses 校验有效性的子句
| LIST CHAINED ROWS [ into_clause ]
| DELETE [ SYSTEM ] STATISTICS
} ;
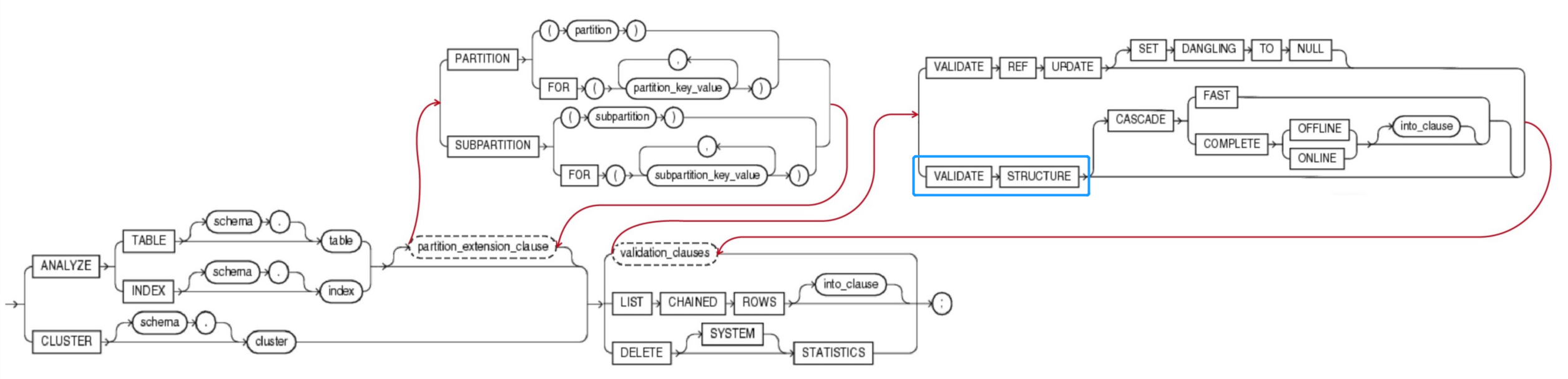
3.1.1 partition_extension_clause (扩展分区子句)
- Specify the partition or subpartition, or the partition or subpartition value, on which you want statistics to be gathered. You cannot use this clause when analyzing clusters.
指定在分区(partition)、子分区(subpartition)、分区值(partition value)、子分区值(subpartition value)上收集统计信息时,在分析集群时不能使用此子句。 - 如果需要收集分区信息,则在analyze语句中加入 扩展分区子句(partition_extension_clause ) 以实现此功能。
具体语法结构如下:
partition_extension_clause::=
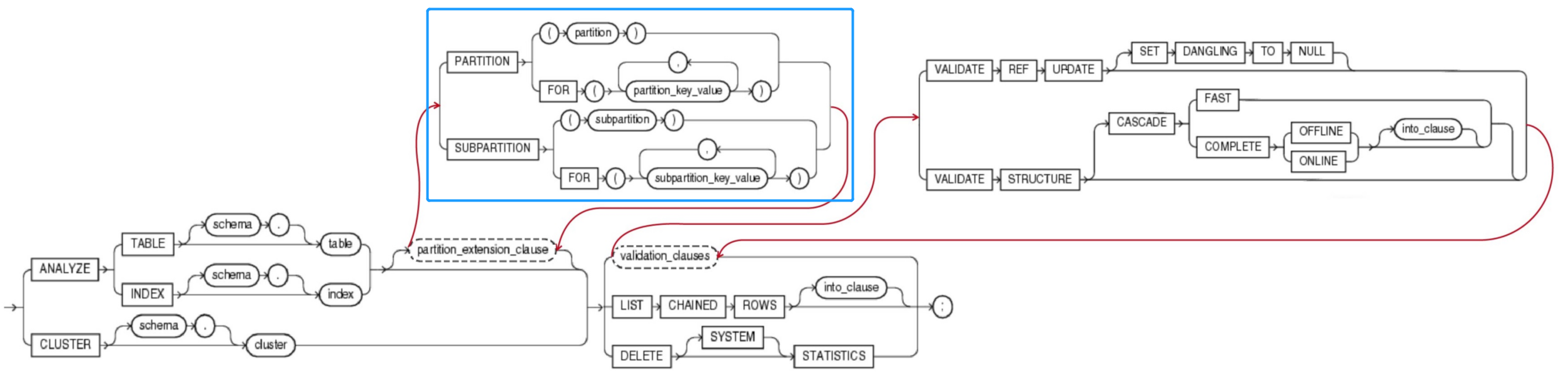
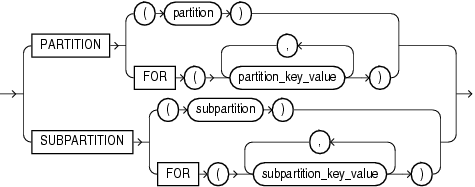
{ PARTITION (partition)
| PARTITION FOR (partition_key_value [, partition_key_value]...)
| SUBPARTITION (subpartition)
| SUBPARTITION FOR (subpartition_key_value [, subpartition_key_value]...)
}
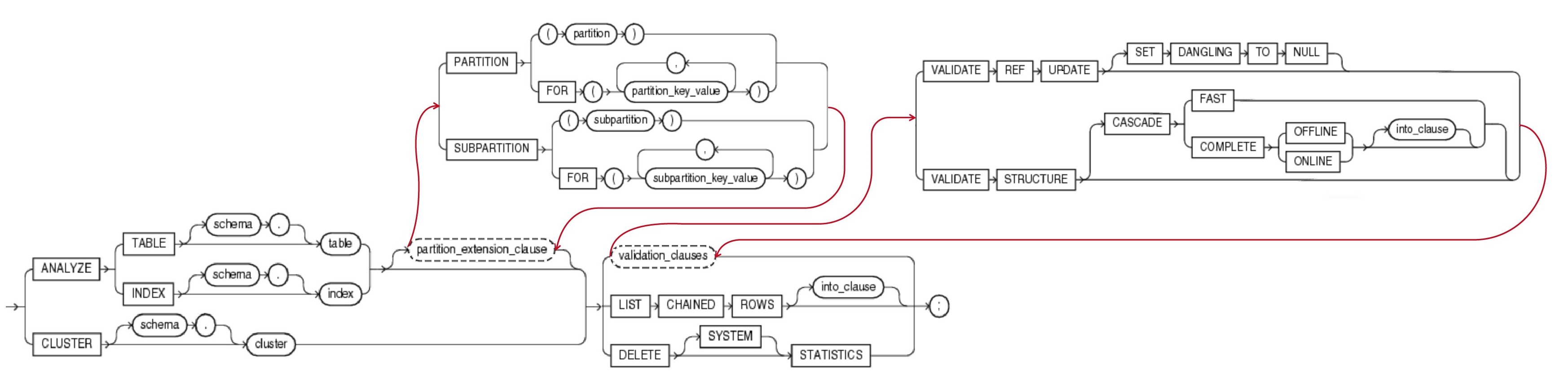
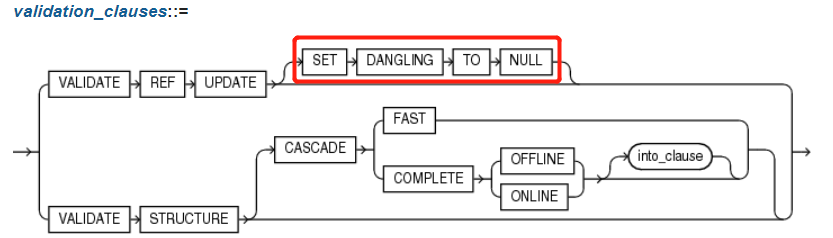
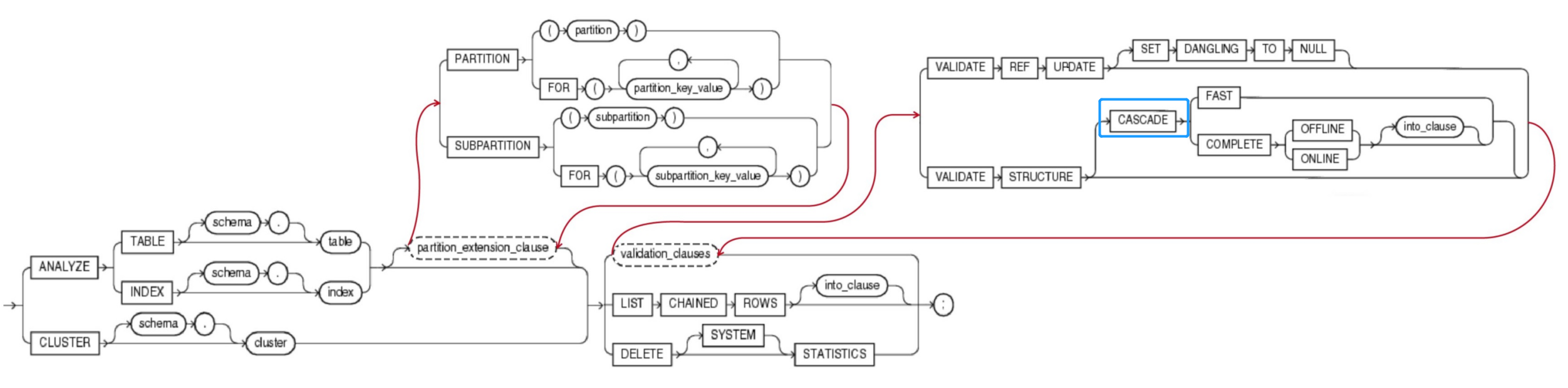
3.1.2 validation_clauses(校验有效性子句)
Oracle Database Administrator’s Guide for more information about validating tables, indexes, clusters, and Materialized Views.
关于校验表(validating tables)、索引、簇(cluster)和物化视图(materialized views)的更多信息,请参阅Oracle数据库管理员指南
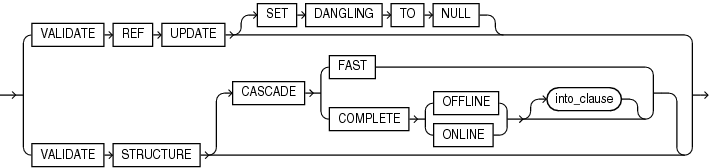
{ VALIDATE REF UPDATE [ SET DANGLING TO NULL ]
| VALIDATE STRUCTURE
[ CASCADE { FAST | COMPLETE { OFFLINE | ONLINE } [ into_clause ] } ] --详见4.6 into_clause
}
3.1.3 into_clause(into子句)
- 在不同子句后面加上INTO子句可以将检查的结果输出到指定表中。
- 1. validation_clauses(校验有效性子句)中,将校验结果(没有正确排序的分区的rowid)输出到指定table 。
- 此时INTO 子句仅适用于分区表(partition table)。
- 2. list chained rows (检查行连接子句)消除行级链接后数据导入到指定table。
- 1. validation_clauses(校验有效性子句)中,将校验结果(没有正确排序的分区的rowid)输出到指定table 。
- 无论在哪个子句中的INTO子句都不是一个必选项,如果省略INTO子句则会将结果输出到系统默认表。
具体语法结构如下:
into_clause::=

INTO [ schema. ] table --详见4.6 into_clause,如果省略schema,则默认schema为当前会话用户
四、Semantics 语义
4.1 schema 模式
Specify the schema containing the table, index, or cluster. If you omit schema, then Oracle Database assumes the table, index, or cluster is in your own schema.
指定表、索引或集群的模式(Schema)。如果省略模式(Schema),则Oracle默认模式(Schema)为当前用户。
4.2 table 表
Specify a table to be analyzed. When you analyze a table, the database collects statistics about expressions occurring in any Function-Based Indexes6 as well. Therefore, be sure to create function-based indexes on the table before analyzing the table. Refer to CREATE INDEX for more information about function-based indexes.
用analyze分析表时,会自动收集函数索引的信息。所以在用analyze收集统计信息前,要先在表上创建 基于函数的索引(Function-Based Indexes) 。
When analyzing a table, the database skips all Domain Indexes7 marked LOADING or FAILED.
用analyze分析表时,会跳过标记为LOADING或FAILED的 应用域索引(domain indexes) 。
For an Index-Organized Table8, the database also analyzes any mapping table and calculates its PCT_ACCESSS_DIRECT statistics. These statistics estimate the accuracy of guess data block addresses stored as part of the local rowids in the mapping table.
对于 索引组织表(index-organized table) ,analyze同时分析映射表并计算其 PCT_ACCESSS_DIRECT(这里不明白,应该是某个列名) 统计信息。这些统计信息估计作为映射表中本地行的一部分存储的猜测数据块地址的准确性。
Oracle Database collects the following statistics for a table. Statistics marked with an asterisk are always computed exactly. Table statistics, including the status of domain indexes, appear in the data dictionary views USER_TABLES, ALL_TABLES, and DBA_TABLES in the columns shown in parentheses.
Oracle为一个表收集以下统计信息:(星号 * 标记的是精确计算值)
表统计信息(包括索引状态)出现在USER_TABLES、ALL_TABLES和DBA_TABLES中的列(括号中所标记的列)
- Number of rows (
NUM_ROWS)
行数量(数据条数)。 - * Number of data blocks below the High Water Mark9—the number of data blocks that have been formatted to receive data, regardless whether they currently contain data or are empty (
BLOCKS)
(历史最)高水位( high water mark) (已格式化以接收数据的数据块的数量,无论它们当前是包含数据还是为空)标记数据块的数量。
BLOCKS + EMPTY_BLOCKS +1 = DBA_SEGMENTS.BLOCKS
这里有一个数据库块被保留用作segment header - * Number of data blocks allocated to the table that have never been used (
EMPTY_BLOCKS)
已分配给表但给从未使用过的数据块数。
BLOCKS + EMPTY_BLOCKS +1 = DBA_SEGMENTS.BLOCKS
这里有一个数据库块被保留用作segment header - Average available free space in each data block in bytes (
AVG_SPACE)
每个数据块的平均可用空闲空间(单位:字节)。 - Number of chained rows (
CHAIN_COUNT)
表中行链接(Chained Rows)的数量。 - Average row length, including the row Overhead10, in bytes (
AVG_ROW_LEN)
平均行长度,包括 块开销(overhead)(单位:字节)。
| Type 种类 | Description 描述 | SourceView 来源视图 | Seri 序号 | SourceColumn 来源列( * 是精确计算值) |
|---|---|---|---|---|
| 表统计信息 table statistics | Number of rows 行数量(数据条数)。 | ALL_TABLES | 20 | NUM_ROWS |
| Number of data blocks below the high water mark (高水位(high water mark) 标记数据块的数量 BLOCKS + EMPTY_BLOCKS +1 = DBA_SEGMENTS.BLOCKS 这里有一个数据库块被保留用作segment header。 | ALL_TABLES | 21 | *BLOCKS | |
| Number of data blocks allocated to the table that have never been used 已分配给表但给从未使用过的数据块数。 BLOCKS + EMPTY_BLOCKS +1 = DBA_SEGMENTS.BLOCKS 这里有一个数据库块被保留用作segment header。 | ALL_TABLES | 22 | *EMPTY_BLOCKS | |
| Average available free space in each data block in bytes 每个数据块的平均可用空闲空间(单位:字节)。 | ALL_TABLES | 23 | AVG_SPACE | |
| Number of chained rows 表中行链接(Chained Rows)的数量。 | ALL_TABLES | 24 | CHAIN_CNT | |
| Average row length, including the row overhead, in bytes 平均行长度,包括 块开销(overhead)(单位:字节)。 | ALL_TABLES | 25 | AVG_ROW_LEN |
Restrictions on Analyzing Tables 分析表的限制
Analyzing tables is subject to the following restrictions:
分析表格受以下限制:
- You cannot use
ANALYZEto collect statistics on Data Dictionary Tables11.
不能使用ANALYZE收集 数据字典表(data dictionary tables) 上的统计信息。 - You cannot use
ANALYZEto collect statistics on an External Table12. Instead, you must use theDBMS_STATSpackage.
不能使用ANALYZE收集 外部表( external table) 上的统计信息。必须使用DBMS_STATS包。 - You cannot use
ANALYZEto collect default statistics on a temporary table. However, if you have already created an association between one or more columns of a temporary table and a user-defined statistics type, then you can useANALYZEto collect the user-defined statistics on the temporary table.
不能使用ANALYZE收集 临时表 上的统计信息。但如果临时表的一列或多列与用户定义的统计数据类型之间创建了关联,则可以使用ANALYZE收集临时表上统计信息(用户定义的)。 - You cannot compute or estimate statistics for the following column types: REF Column Types13, Varrays14, Nested Tables15, LOB column types (LOB column types are not analyzed, they are skipped),
LONGcolumn types, or object types. However, if a statistics type is associated with such a column, then Oracle Database collects user-defined statistics.
不能 Analyze (Compute表示全表扫描,Estimate Statistics Sample 10 percent表示抽样10%数据进行分析)以下列类型的统计信息: REF游标(REF) 、变长数组(varrays) 、嵌套表(nested tables)、LOB列类型(CLOB,BLOB直接跳过)、LONG类型、对象(Object)类型。
但如果统计数据类型与这样的列相关联,那么Oracle将收集用户定义的统计数据。(?没看懂)
✎ See Also:
:::::::::::::::::::::::::::::::::::
- ASSOCIATE STATISTICS
关联数据- Oracle Database Reference for information on the data dictionary views
Oracle静态数据字典视图
partition_extension_clause 扩展分区子句
Specify the partition or subpartition, or the partition or subpartition value, on which you want statistics to be gathered. You cannot use this clause when analyzing clusters.
指定在分区(partition)、子分区(subpartition)、分区值(partition value)、子分区值(subpartition value)上收集统计信息时,在分析簇时不能使用此子句。
If you specify PARTITION and table is Composite-Partitioned16 , then Oracle Database analyzes all the subpartitions within the specified partition.
如果指定分区表是 复合分区(Composite-Partitioned) 的,那么Oracle将分析指定分区内的所有子分区。
4.3 index 索引
Specify an index to be analyzed.
指定要分析的索引。
Oracle Database collects the following statistics for an index. Statistics marked with an asterisk are always computed exactly. For conventional indexes, when you compute or estimate statistics, the statistics appear in the data dictionary views USER_INDEXES, ALL_INDEXES, and DBA_INDEXES in the columns shown in parentheses.
使用 analyze 将收集以下统计信息(星号 * 标记的统计数据为精确计算值)。对于常规索引,统计信息出现在数据字典视图USER_INDEXES、ALL_INDEXES和DBA_INDEXES中括号中显示的列中。
- * Depth Of The Index17 from its Root Block18 to its Leaf Blocks19 (
BLEVEL)
B-Tree索引中从 根块(root block) 到 叶块(left block) 的 索引深度(Depth of the index) (纵向IO次数)。 - Number of leaf blocks (
LEAF_BLOCKS)
叶块(leaf blocks)数量。 - Number of distinct index values (
DISTINCT_KEYS)
不同索引值的个数。 - Average number of leaf blocks for each index value (
AVG_LEAF_BLOCKS_PER_KEY)
每个索引值的平均叶块(leaf blocks)数。 - Average number of data blocks for each index value (for an index on a table) (
AVG_DATA_BLOCKS_PER_KEY)
每个索引值(用于表上的索引)的平均数据块数。 - Clustering Factor20 (how well ordered the rows are about the indexed values) (
CLUSTERING_FACTOR)
集群因子(Clustering Factor) (索引值的行有序程度)。
| Type 种类 | Description 描述 | SourceView 来源视图 | Seri 序号 | SourceColumn 来源列( * 是精确计算值) |
|---|---|---|---|---|
| 索引统计信息 index statistics | Depth of the index from its root block to its leaf blocks. B-Tree索引中从 根块(root block) 到 叶块(left block) 的 索引深度(Depth of the index) (纵向IO次数)。 | ALL_INDEXES | 24 | *BLEVEL |
| Number of leaf blocks. 叶块(leaf blocks)数量。 | ALL_INDEXES | 25 | LEAF_BLOCKS | |
| Number of distinct index values 不同索引值的个数。 | ALL_INDEXES | 26 | DISTINCT_KEYS 索引DISTINCT后个数 | |
| Average number of leaf blocks for each index value 每个索引值(用于表上的索引)的平均数据块数。 | ALL_INDEXES | 27 | AVG_LEAF_BLOCKS_PER_KEY 存放一个键值的平均叶块数 = LEAF_BLOCKS / DISTINCT_KEYS = 25 / 26 | |
| Average number of data blocks for each index value (for an index on a table) 集群因子(索引值的行有序程度)。 | ALL_INDEXES | 28 | AVG_DATA_BLOCKS_PER_KEY 单个索引引用的平均数据块数 = CLUSTERING_FACTOR / DISTINCT_KEYS = 29 / 26 | |
| Clustering factor (how well ordered the rows are about the indexed values) 集群因子(索引值的行有序程度)。 | ALL_INDEXES | 29 | CLUSTERING_FACTOR row存储的越有序,clustering factor的值越低 |
For domain indexes, this statement invokes the user-defined statistics collection function specified in the statistics type associated with the index (see ASSOCIATE STATISTICS). If no statistics type is associated with the domain index, then the statistics type associated with its indextype is used. If no statistics type exists for either the index or its indextype, then no user-defined statistics are collected. User-defined index statistics appear in the STATISTICS column of the data dictionary views USER_USTATS, ALL_USTATS, and DBA_USTATS.
域索引(domain indexes)的语句调用用户定义的统计信息(user-defined statistics)收集函数,在与索引关联的统计信息类型中指定该函数(查看关联统计信息)。如果没有与域索引相关联的统计数据类型,则使用与其索引类型相关联的统计数据类型。如果索引或其索引类型都不存在统计数据类型,则不收集用户定义的统计数据。
用户定义的索引统计信息出现在数据字典视图 USER_USTATS、ALL_USTATS、DBA_USTATS 的statistics列中。
✎ Note:
:::::::::::::::::::::::::
When you analyze an index from which a substantial number of rows has been deleted, Oracle Database sometimes executes a COMPUTE statistics operation (which can entail a full table scan) even if you request an ESTIMATE statistics operation. Such an operation can be quite time consuming.
分析一个已经删除了大量行的索引时,即使请求估算统计信息,Oracle有时也会计算全部统计信息(可能会全表扫描),这可能相当耗时。
Restriction on Analyzing Indexes 指标分析的限制
You cannot analyze a domain index that is marked IN_PROGRESS or FAILED.
无法分析状态为 IN_PROGRESS(运行中) 或 FAILED(失败)的域索引。
✎ See Also:
:::::::::::::::::::::::::::::::::::
When you analyze an index from which a substantial number of rows has been deleted, Oracle Database sometimes executes a COMPUTE statistics operation (which can entail a full table scan) even if you request an ESTIMATE statistics operation. Such an operation can be quite time consuming.
分析一个已经删除了大量行的索引时,即使请求估算统计信息,Oracle有时也会计算全部统计信息(可能会全表扫描),这可能相当耗时。
- CREATE INDEX for more information on domain indexes
查看创建索引 以获取关于域索引(domain )的更多信息- Oracle Database Reference for information on the data dictionary views
Oracle静态数据字典视图参考信息- “Analyzing an Index: Example”
使用Analyze获取索引统计信息的用例
4.4 cluster 簇(集群)
Specify a cluster to be analyzed. When you collect statistics for a Cluster21, Oracle Database also automatically collects the statistics for all the tables in the cluster and all their indexes, including the Cluster Index22.
收集 簇(cluster) 的统计信息时。Oracle也会自动收集以下信息:簇中所有簇中的表(Table of Cluster)、所有表簇相关表的索引(Cluster Tables Index)、表簇索引(Cluster Index) 。
These statistics appear in the data dictionary views ALL_CLUSTERS, USER_CLUSTERS, and DBA_CLUSTERS.
相关统计信息出现在以下静态数据字典中 ALL_CLUSTERS 、USER_CLUSTERS 、DBA_CLUSTERS 。
- For both indexed and hash clusters, the database collects the average number of data blocks taken up by a single Cluster Key23 (
AVG_BLOCKS_PER_KEY).
索引表簇(Indexed Cluster)和哈希表簇(Hash Cluster)中数据库收集单个 簇键(Cluster Key) 所占用的数据块的平均数量。
| Type 种类 | Description 描述 | SourceView 来源视图 | Seri 序号 | SourceColumn 来源列( * 是精确计算值) |
|---|---|---|---|---|
| 簇(集群)统计信息 cluster statistics | Number of blocks in the table divided by number of cluster keys. 表中块的数量除以 簇键(Cluster Key) 的数量 创建簇的参数SIZE,决定了每个簇键值可以关联多少字节的数据,进而计算出每个数据块能容纳多少个簇键。 当SIZE设置过高,单独的数据块可以容纳的簇键会减少,且对于单个簇键会占用比实际需求更多的空间,造成空间的浪费。 当SIZE设置过低,单个的簇键无法在单独的数据块中容纳一条完整的数据,进而导致溢出数据部分串联至新块,影响聚合度。 当SIZE设置为1024时,对于一个8K(8192)的标准块,由于数据块的pct_free,实际可容纳7个簇键。 | ALL_CLUSTERS | 16 | AVG_BLOCKS_PER_KEY = 表中块的数量 / 簇键的数量 |
✎ See Also:
:::::::::::::::::::::::::::::::::::
Oracle Database Reference for information on the data dictionary views and "Analyzing a Cluster: Example"
静态数据字典和使用Analyze收集Cluster统计信息的用例参考信息
五、partition_extension_clause 扩展分区子句
{ PARTITION (partition)
| PARTITION FOR (partition_key_value [, partition_key_value]...)
| SUBPARTITION (subpartition)
| SUBPARTITION FOR (subpartition_key_value [, subpartition_key_value]...)
}
来自 4.2 table 表
Specify the partition or subpartition, or the partition or subpartition value, on which you want statistics to be gathered. You cannot use this clause when analyzing clusters.
指定在分区(partition)、子分区(subpartition)、分区值(partition value)、子分区值(subpartition value)上收集统计信息时,在分析簇时不能使用此子句。
If you specify PARTITION and table is Composite-Partitioned , then Oracle Database analyzes all the subpartitions within the specified partition.
如果指定分区表是 复合分区(Composite-Partitioned) 的,那么Oracle将分析指定分区内的所有子分区。
六、 validation_clauses 校验有效性的子句
✎ See Also:
:::::::::::::::::::::::::::::::::::
Oracle Database Administrator’s Guide for more information about validating tables, indexes, clusters, and Materialized Views24
关于校验表(validating tables)、索引、簇(cluster)和 物化视图(materialized views) 的更多信息,请参阅Oracle数据库管理员指南
Oracle数据库管理员指南
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
To verify the integrity of the structure of a table, index, cluster, or materialized view, use the ANALYZE statement with the VALIDATE STRUCTURE option. If the structure is valid, no error is returned. However, if the structure is corrupt, you receive an error message.
要校验表(table)、索引(index)、簇(cluster)或物化视图(materialized view)结构的完整性,可使用带有VALIDATE structure选项的ANALYZE语句。如果结构有效,不返回值。结构无效则返回错误信息。
For example, in rare cases such as hardware or other system failures, an index can become corrupted and not perform correctly. When validating the index, you can confirm that every entry in the index points to the correct row of the associated table. If the index is corrupt, you can drop and re-create it.
例如,在硬件或其他系统故障等罕见情况下,索引可能会损坏并不能正确执行。在校验索引时会确认索引中的每个条目都指向相关表的正确行。如果索引损坏,可以通过删除并重新创建索引修复此问题。
If a table, index, or cluster is corrupt, you should drop it and re-create it. If a materialized view is corrupt, perform a complete refresh and ensure that you have remedied the problem. If the problem is not corrected, drop and re-create the materialized view.
如果表(table)、索引(index)或簇(cluster)损坏,应将其删除并重新创建。如果物化视图(materialized view)损坏,可以通过尝试刷新视图来修复。如果问题视图仍未修复,可以删除并重新创建物化视图(materialized table)。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
The following statement analyzes the emp table:
用以下语句分析emp表:ANALYZE TABLE emp VALIDATE STRUCTURE;You can validate an object and all dependent objects (for example, indexes) by including the CASCADE option. The following statement validates the emp table and all associated indexes:
可以通过包含CASCADE选项来校验对象和所有依赖对象(例如索引)。
用以下语句校验emp表和所有相关的索引有效性:ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE;By default the CASCADE option performs a complete validation. Because this operation can be resource intensive, you can perform a faster version of the validation by using the FAST clause. This version checks for the existence of corruptions using an optimized check algorithm, but does not report details about the corruption. If the FAST check finds a corruption, you can then use the CASCADE option without the FAST clause to locate it. The following statement performs a fast validation on the emp table and all associated indexes:
默认情况下,CASCADE选项执行完整的校验过程。因为这个操作会消耗大量资源,建议使用FAST子句的方式进行更快的校验。此方式使用优化的检查算法来检查是否存在损坏,但是不报告有关损坏的细节。如果FAST检查发现了损坏,可以再使用没有FAST子句的CASCADE选项来定位错误位置。
用以下语句对emp表和所有相关索引执行快速校验有效性:ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE FAST;You can specify that you want to perform structure validation online while DML is occurring against the object being validated. Validation is less comprehensive with ongoing DML affecting the object, but this is offset by the flexibility of being able to perform ANALYZE online. The following statement validates the emp table and all associated indexes online:
当数据操纵语言(DML)正在运行时,校验有效性这个过程可能不完整,但通过在线analyze语句可以对这种情况进行灵活的处理。
用以下语句在线校验emp表和所有相关的索引有效性:ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE ONLINE;
6.1 VALIDATE REF UPDATE Clause 校验游标更新有效性的子句
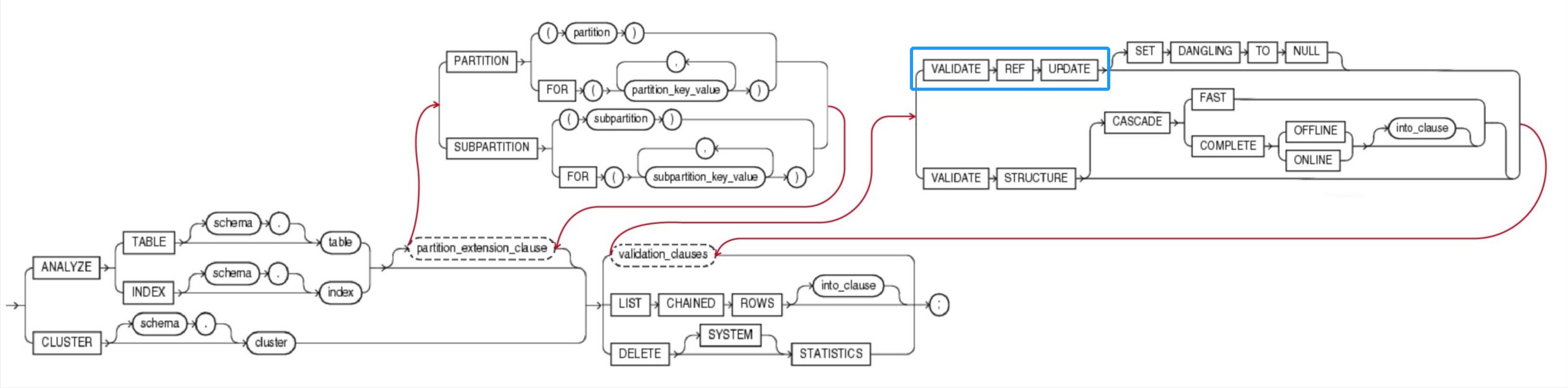
Specify VALIDATE REF UPDATE to validate the REF values in the specified table, check the Rowid25 portion in each REF, compare it with the true rowid, and correct it, if necessary. You can use this clause only when analyzing a table.
指定VALIDATE REF UPDATE来校验表中的游标(REF)值,检查每个游标(REF)中的 物理地址(Rowid) 与真实 物理地址(Rowid) 进行比较,并修复错误值。
If the owner of the table does not have SELECT object privilege on the referenced objects, then Oracle Database will consider them invalid and set them to null. Subsequently these REF values will not be available in a query, even if it is issued by a user with appropriate privileges on the objects.
如果表的所有者对引用的对象没有 SELECT 对象权限,那么Oracle将认为这些对象无效,并将其设置为null。即使有权限的用户重新发布了游标(REF)值,在之后查询中,这些游标(REF)值也不可用。
6.1.1 SET DANGLING TO NULL 设置无效指针为空子句
SET DANGLING TO NULL sets to null any REF values (whether or not scoped) in the specified table that are found to point to an invalid or nonexistent object.
将SET DANGLING TO NULL 的值设置为NULL,指定表中游标(REF)值无效的那些值将变为NULL(无论是否有作用域)。
6.2 VALIDATE STRUCTURE 校验结构有效性

Specify VALIDATE STRUCTURE to validate the structure of the analyzed object. The statistics collected by this clause are not used by the Oracle Database optimizer.
指定 VALIDATE STRUCTURE 来校验analyze对象的结构是否有效。
✎ See Also:
:::::::::::::::::::::::::::::::::::
“Validating a Table: Example”
使用Analyze校验表有效性的用例
-
For a table, Oracle Database verifies the integrity of each of the data blocks and rows. For an index-organized table, the database also generates compression statistics (optimal prefix compression count) for the primary key index on the table.
对于表,Oracle校验每个数据块和行的完整性。对于索引组织表(IOT),Oracle 还为表上的主键索引生成压缩统计信息(最优前缀压缩计数)。 -
For a cluster, Oracle Database automatically validates the structure of the cluster tables.
对于集群,Oracle会自动校验集群表的结构。 -
For a partitioned table, Oracle Database also verifies that each row belongs to the correct partition. If a row does not collate correctly, then its rowid is inserted into the
INVALID_ROWStable.
对于分区表,Oracle会校验每一行是否属于正确的分区。如果某一行没有正确排序,则将其rowid插入到 INVALID_ROWS(无效行)表中。 -
For a temporary table, Oracle Database validates the structure of the table and its indexes during the current session.
对于临时表,Oracle在当前会话期间校验表的结构及其索引。 -
For an index, Oracle Database verifies the integrity of each data block in the index and checks for block corruption. This clause does not confirm that each row in the table has an index entry or that each index entry points to a row in the table. You can perform these operations by validating the structure of the table with the CASCADE clause.
对于索引,Oracle会校验索引中每个数据块的完整性,并检查块损坏。此子句不校验数据的有效性(表中的是否每一行都有一个索引项,或是否每个索引项都指向表中的一行)。可以通过6 validation_clauses 中的CASECADE子句来校验数据的有效性。 -
Oracle Database also computes compression statistics (optimal prefix compression count) for all normal indexes.
Oracle还会计算所有正常索引的压缩统计数据(最佳前缀压缩计数)。 -
Oracle Database stores statistics about the index in the data dictionary views
INDEX_STATSandINDEX_HISTOGRAM.
Oracle在静态数据字典 INDEX_STATS 和 INDEX_HISTOGRAM 中存储关于索引的统计信息。✎ See Also:
:::::::::::::::::::::::::::::::::::
Oracle Database Reference for information on these views
相关视图的信息,请参考Oracle数据库
If Oracle Database encounters corruption in the structure of the object, then an error message is returned. In this case, drop and re-create the object.
如果Oracle对象结构损坏,则返回一条错误消息。这种情况需要删除并重新创建对象。
6.2.1 CASCADE 级联
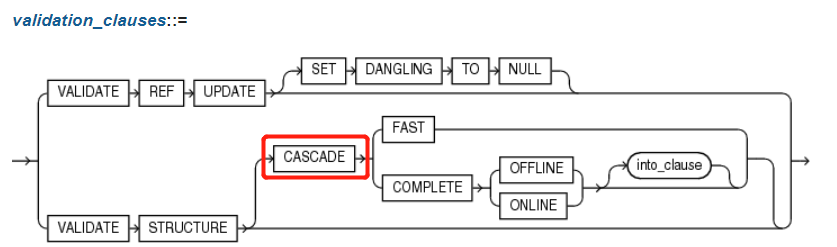
Specify CASECADE26 if you want Oracle Database to validate the structure of the indexes associated with the table or cluster. If you use this clause when validating a table, then the database also validates the indexes defined on the table. If you use this clause when validating a cluster, then the database also validates all the cluster tables indexes, including the cluster index.
如果希望Oracle校验表或集群关联的索引结构有效性,可指定 CASECADE 参数。
如果在校验表有效性时使用这个子句,会同时校验表上定义的索引的有效性。
如果在校验簇(cluster)有效性时使用这个子句,会同时校验所有表簇相关表的索引(Cluster Table Index),包括索引表簇(Cluster Index)的有效性。
By default, CASCADE performs a COMPLETE validation, which can be resource intensive. Specify FAST if you want the database to check for the existence of corruptions without reporting details about the corruption. If the FAST check finds a corruption, you can then use the CASCADE option without the FAST clause to locate and learn details about it.
默认情况下,CASCADE选项执行完整的校验过程。因为这个操作会消耗大量资源,建议使用FAST子句的方式进行更快的校验。此方式使用优化的检查算法来检查是否存在损坏,但是不报告有关损坏的细节。如果FAST检查发现了损坏,可以再使用没有FAST子句的CASCADE选项来定位错误位置。
用以下语句校验emp表和所有相关的索引有效性:
ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE;用以下语句对emp表和所有相关索引执行快速校验有效性:
ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE FAST;
If you use this clause to validate an enabled (but previously disabled) function-based index, then validation errors may result. In this case, you must rebuild the index.
如果使用此子句校验启用(但之前禁用)的基于函数的索引,则可能会导致校验发生错误(没有获取到最新的函数状态,Oralce仍然认为函数不可用)。在这种情况下必须重新构建索引。
6.2.1.1 ONLINE | OFFLINE(DEFAULT) 【在线 | 离线(默认值)】
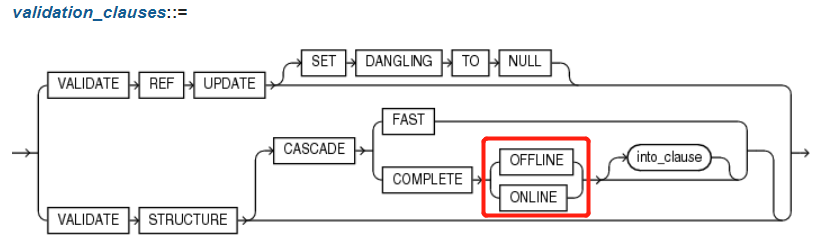
Specify ONLINE to enable Oracle Database to run the validation while DML operations are ongoing within the object. The database reduces the amount of validation performed to allow for concurrency.
指定在线(ONLINE)analyze时,允许对校验对象进行DML(INSERT、UPDATE、DELETE)操作。
用以下语句在线校验emp表和所有相关的索引有效性:
ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE ONLINE;
✎ Note:
:::::::::::::::::::::::::
When you validate the structure of an objectONLINE, Oracle Database does not collect any statistics, as it does when you validate the structure of the objectOFFLINE.
指定离线(OFFLINE)analyze时,收集统计信息。
指定在线(ONLINE) analyze时,则不会。
Specify OFFLINE, to maximize the amount of validation performed. This setting prevents INSERT, UPDATE, and DELETE statements from concurrently accessing the object during validation but allows queries. This is the default.
指定离线(OFFLINE)analyze时,禁止对校验对象进行DML(INSERT、UPDATE、DELETE)操作,但允许查询。
如果不指定则默认为离线(OFFLINE)。
用以下语句离线校验emp表和所有相关的索引有效性:
ANALYZE TABLE emp VALIDATE STRUCTURE CASCADE;
Restriction on ONLINE 在线(ONLINE)校验的限制
You cannot specify ONLINE when analyzing a cluster.
使用analyze分析簇(Cluster)时,不能使用在线(ONLINE)方式。
七、into_clause INTO子句
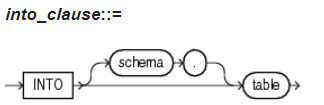
The INTO clause of VALIDATE STRUCTURE is valid only for partitioned tables. Specify a table into which Oracle Database lists the rowids of the partitions whose rows do not collate correctly. If you omit schema, then the database assumes the list is in your own schema. If you omit this clause altogether, then the database assumes that the table is named INVALID_ROWS. The SQL script used to create this table is UTLVALID.SQL.
validation_caluse子句中的INTO子句仅对分区表有效。Oracle校验没有正确排序的分区的rowid。输出到指定的schema.表名。
- 如果不指定schema则默认schema为当前会话用户。
- 如果在LIST CHAINED ROWS子句后面省略INTO子句,则校验结果输出到默认表 INVALID_ROWS( INVALID_ROWS表 通过UTLVALID.SQL创建)。
- 如果在VALIDATE STRUCTRUE子句后面省略INTO子句,则校验结果输出到默认表 CHAIN_ROWS( CHAIN_ROWS表 通过UTLCHAIN.SQL 或 UTLCHAIN1.SQL创建)。
八、LIST CHAINED ROWS 检查行链接子句
chained row (行链接)对性能影响很大,通过analyze可以检查行链接的情况,将统计信息保存到一个表里。 这个表默认为CHAINED_ROWS ,如果通过INTO子句指定其他表,需要自己先把该表创建好。
LIST CHAINED ROWS lets you identify migrated and chained rows of the analyzed table or cluster. You cannot use this clause when analyzing an index.
通过检查行链接子句(LIST CHAINED ROWS)分析表(table)或簇(cluster)中的迁移行(Migrated Rows)、链接行(Chained Rows)。
检查行连接(LIST CHAINED ROWS)不支持索引(index)。
In the INTO clause, specify a table into which Oracle Database lists the migrated and chained rows. If you omit schema, then the database assumes the chained-rows table is in your own schema. If you omit this clause altogether, then the database assumes that the table is named CHAINED_ROWS. The chained-rows table must be on your local database.
在INTO子句中,指定一个表,Oralce将检查出的迁移行(Chained Rows),迁移列(Migrated Rows)输出到INTO子句指定的 shcema.table 中。
如果不指定schema,则默认schema为当前会话用户。
如果完全省略INTO子句,则输出到默认表 CHAINED_ROWS 中
You can create the CHAINED_ROWS table using one of these scripts:
使用以下任一脚本创建 CHAINED_ROWS 表:
UTLCHAIN.SQLuses Physical Rowids27 . Therefore it can accommodate rows from Conventional Tables28 but not from index-organized tables. (See the Note that follows.)
UTLCHAIN.SQL,使用 物理地址(Physical Rowid)。可以存储 常规表(conventional table) 的检查结果,不能存储索引组织表(index-organized tables)的行链接检查结果。(详见下面See Also中的说明)UTLCHN1.SQLuses Universal Rowids29 , so it can accommodate rows from both conventional and index-organized tables.
UTLCHAIN1.SQL,使用 通用地址(Logical Rowid 的数据类型简称 UROWID ) ,可以存储来自常规表(conventional table)和索引组织表(index-organized tables)的行链接检查结果。
If you create your own chained-rows table, then it must follow the format prescribed by one of these two scripts.
如果创建自己的chained-rows表(这里说的是创建自己的目标表并使用INTO子句将analyze检查结果输入到其中,代替系统默认的chained-rows表).
这个表必须遵循以上两脚本之一的规定格式。
If you are analyzing index-organized tables based on primary keys (rather than universal rowids), then you must create a separate chained-rows table for each index-organized table to accommodate its primary-key storage. Use the SQL scripts DBMSIOTC.SQL and PRVTIOTC.PLB to define the BUILD_CHAIN_ROWS_TABLE procedure, and then execute this procedure to create an IOT_CHAINED_ROWS table for each such index-organized table.
如果使用analyze检查索引组织表(Index-Organized Tables)的行链接情况。索引组织表(Index-Organized Tables)需要创建一个自己的chained-rows表(这里说的是创建自己的目标表并使用INTO子句analyze检查将结果输入到其中,代替系统默认的chained-rows表)。调用 DBMSIOTC.SQL 和 PRVTIOTC.PLB 定义存储过程 BUILD_CHAIN_ROWS_TABLE,然后执行该过程为每个索引组织表(Index-Organized Tables)创建 IOT_CHAINED_ROWS 表。
✎ See Also:
:::::::::::::::::::::::::::::::::::
- Oracle Database Performance Tuning Guide information about these scripts and about eliminating chained rows
《Oracle数据库性能调优指南》提供了有关这些脚本和消除链接行的信息- The
DBMS_IOTpackage in Oracle Database PL/SQL Packages and Types Reference for information on the packaged SQL scripts
Oracle数据库PL/SQL包和类型参考中的 DBMS_IOT 包提供了打包SQL脚本的信息- “Listing Chained Rows: Example”
使用Analyze检查行链接的用例
九、DELETE STATISTICS 删除统计信息子句
Specify DELETE STATISTICS to delete any statistics about the analyzed object that are currently stored in the data dictionary. Use this statement when you no longer want Oracle Database to use the statistics.
DELETE STATISTICS 可删除静态数据字典中关于被分析对象的任何统计信息。如果不希望Oracle数据库使用统计信息时,使用此语句。
When you use this clause on a table, the database also automatically removes statistics for all the indexes defined on the table. When you use this clause on a cluster, the database also automatically removes statistics for all the cluster tables and all their indexes, including the cluster index.
对 表 使用 DELETE子句时,Oralce还会自动删除该表上定义的所有索引的统计信息。
对集群使用DELETE子句时,Oracle还会自动删除所有簇表(cluster tables)及其索引、簇索引(cluster index)的统计信息。
Specify SYSTEM if you want Oracle Database to delete only system (not user-defined) statistics. If you omit SYSTEM, and if user-defined column or index statistics were collected for an object, then the database also removes the user-defined statistics by invoking the statistics deletion function specified in the statistics type that was used to collect the statistics.
如果DELETE STATISTICS子句中
不指定SYSTEM,则会删除系统统计信息和用户自定义统计信息。
若指定SYSTEM,则只会删除系统统计信息。
✎ See Also:
:::::::::::::::::::::::::::::::::::
“Deleting Statistics: Example”
使用Analyze删除统计信息的用例
十、Examples 演示用例
10.1 Deleting Statistics: Example 删除统计信息的演示用例
The following statement deletes statistics about the sample table oe.orders and all its indexes from the data dictionary:
Delete statistic演示用例:删除 oe.orders 表及其索引的统计信息。
ANALYZE TABLE orders DELETE STATISTICS;
10.2 Analyzing an Index: Example 收集索引统计信息并校验有效性的演示用例
The following statement validates the structure of the sample index oe.inv_product_ix:
Analyze index演示用例:校验 oe.inv_product_ix 索引的有效性。
ANALYZE INDEX inv_product_ix VALIDATE STRUCTURE;
10.3 Validating a Table: Example 收集表统计信息并校验相关对象有效性的演示用例
The following statement analyzes the sample table hr.employees and all of its indexes:
Validating a Table 演示用例之1:校验 hr.employees 表及其所有索引。
ANALYZE TABLE employees VALIDATE STRUCTURE CASCADE;
For a table, the VALIDATE REF UPDATE clause verifies the REF values in the specified table, checks the rowid portion of each REF, and then compares it with the true rowid. If the result is an incorrect rowid, then the REF is updated so that the rowid portion is correct.
VALIDATE REF UPDATE子句验证指定表中的 游标(REF) 值,检查每个游标中指向的物理地址(rowid)是否真实存在,如果不存在则会更新游标(REF)值,使其指向正确地址(rowid)。
The following statement validates the REF values in the sample table oe.customers:
Analyze index演示用例之2:校验 customers 表游标的有效性。
ANALYZE TABLE customers VALIDATE REF UPDATE;
The following statement validates the structure of the sample table oe.customers while allowing simultaneous DML:
Analyze index演示用例之3:校验 oe.customers 表结构有效性,使用在线(ONLINE)模式,Analyze时可以对表进行DML操作。
ANALYZE TABLE customers VALIDATE STRUCTURE ONLINE;
10.4 Analyzing a Cluster: Example 校验
The following statement analyzes the personnel cluster (created in “Creating a Cluster: Example”), all of its tables, and all of their indexes, including the cluster index:
Analyze a Cluster演示用例:校验 personnel 簇中的簇表(cluster table),簇表索引(cluster table index),簇索引(cluster index)
这里校验的是在"Creating a cluster: Example"中创建的簇
/*
--创建簇
CREATE CLUSTER personnel
(department NUMBER(4))
SIZE 512
STORAGE (initial 100K next 50K);
*/
ANALYZE CLUSTER personnel
VALIDATE STRUCTURE CASCADE;
10.5 Listing Chained Rows: Example
The following statement collects information about all the chained rows in the table orders:
Listing Chained Rows演示用例:
ANALYZE TABLE orders
LIST CHAINED ROWS INTO chained_rows;
The preceding statement places the information into the table chained_rows. You can then examine the rows with this query (no rows will be returned if the table contains no chained rows):
上面的语句将信息放入chained_rows行链接表中。可以通过以下SQL检查链接的行信息(如果表中没有行链接,则不会返回任何值):
SELECT owner_name, table_name, head_rowid, analyze_timestamp
FROM chained_rows
ORDER BY owner_name, table_name, head_rowid, analyze_timestamp;
OWNER_NAME TABLE_NAME HEAD_ROWID ANALYZE_TIMESTAMP
---------- ---------- ------------------ -----------------
OE ORDERS AAAAZzAABAAABrXAAA 25-SEP-2000
- 以下示例内容来自网上他人文章,未经测试不保证准确性
表(如行数多少等,不涉及到表字段)
- 收集表统计信息
analyze table table_name compute statistics;- 收集表,表字段,索引统计信息
analyze table table_name compute statistics;- 删除表统计信息
analyze table table_name delete statistics;- 删除表,表字段,索引统计信息
analyze table table_name delete statistics for table for all indexes for all indexed columns;
字段
- 收集表表字段信息(user_tab_columns)
analyze table table_name compute statistics for all columns;
索引
- 收集表索引统计信息(user_indexes)
analyze table table_name compute statistics for all indexes;- 收集表中索引所在的字段信息(user_tab_columns)
analyze table table_name compute statistics for all indexed columns;
行链接
- 链表行分析(检查行链接)
analyze table table_name list chained rows into chained_rows;
20/12/10
M
Validate :校验有效性(Validate) ,这里指的是校验有效性的子句validation_clauses。 ↩︎
Chained Rows :行链接(Chained Rows) ,当某个数据块存储不下一条数据时会有两种处理方式,分别是行链接(Chained Rows)和行迁移(Chained Migration)。
● 行链接(Chained Rows)会发生在当插入(INSERT)数据的过程中。由于某行太长而不能容纳在一个数据块中时,就会发生行链接(Chained Rows)。在这种情况下,oracle会使用与该块链接的一块或多块数据块来容纳该行的数据。行连接经常在插入比较大的行时才会发生,如long, long row, lob等类型的数据。
● 行迁移(Chained Migration)会发生在更新(UPDATE)数据过程中。当update后的行长度大于修改前的行长度,并且该数据块中的自由空间(Free List)已经比较小而不能完全容纳该行的数据时,就会发生行迁移(Chained Migration)。在这种情况下,Oracle会将整行的数据迁移到一个新的数据块上,而将该行原先的空间只放一个指针,指向该行的新的位置,注意,即使发生了行迁移,发生了行迁移的行的rowid 还是不会变化。
无论是行链接(Chained Rows)和行迁移(Chained Migration),都会导致在一次读取过程中读取多个数据块,引起I/O性能下降。
图 12-14 Row Chaining(行链接)
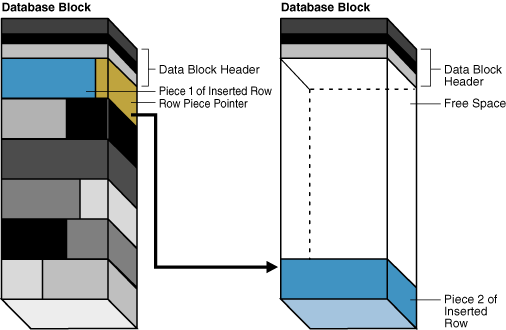
图 12-14 Row Migration(行迁移)
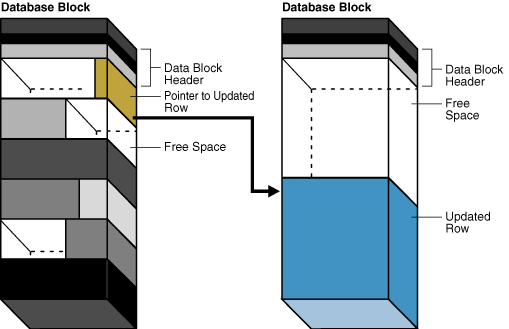
图片来自 Logical Storage Structures(逻辑存储结构)
● 消除行链接可以执行以下语句
sql analyze table table_name list chained rows into chained_rows;
↩︎Freelist :自由列表块(Freelist) 。单向链表用于定位可以接收数据的块,在字典管理方式的表空间中,Oracle使用free list来管理未分配的存储块(见上图所示Free Space部分)。Oracle记录了有空闲空间的块用于insert或Update。空闲空间来源于两种方式:1.段中所有超过HWM的块,这些块已经分配给段了,但是还未被使用。2.段中所有在HWM下的且链入了free list的块,可以被重用。 ↩︎
Partitioned Table :分区表(Partitioned Table) 。分区表就是通过使用分区技术,将一张大表,拆分成多个表分区(独立的segment),从而提升数据访问的性能,以及日常的可维护性。
分区表中,每个分区的逻辑结构必须相同。如:列名、数据类型。
分区表中,每个分区的物理存储参数可以不同。如:各个分区所在的表空间。
对于应用而言完全透明,分区前后没有变化,不需要进行修改。 ↩︎::= 的意思是被定义为,这是巴科斯范式的用法。 ↩︎
Function-based indexes :基于函数的索引(Function-based indexes) Oracle的索引类型有以下几种,基于函数的索引 (Function-based indexes)为其中的一种
● B-tree indexes(平衡二叉树-默认索引类型)
● B-tree cluster indexes(cluster的索引类型 )
● Bitmap indexes(位图索引,索引列的值属于一个很小的范围)
● Domain indexes(应用程序域索引)
● Function-based indexes(基于函数的索引 )
● Global and local indexes(分区表相关的索引)
● Hash cluster indexes(cluster的哈希索引类型)
● Reverse key indexes(反向索引) ↩︎Domain Indexes :应用程序域索引(Application Domain Indexes) ,应用域索引是特定于应用程序的自定义索引。 Oracle提供了可扩展的索引来执行以下操作:
向用户提供有关复杂数据类型的索引的定义,例如文档,空间数据,图像和视频剪辑
可以查看官方文档如何创建应用程序索引。 ↩︎Index-Organized Table :索引组织表(Index-Organized Table) 简称 IOT 。
Oracle数据表三种基本类型:堆表Heap Table、索引组织表IOT 、聚簇表Cluster。
索引组织表(index-organized table)完全由主键组成或者只通过主键来访问一个表。使用 ↩︎High Water Mark :HWM(High Water Mark) 是一个标记,用来说明已经有多少没有使用的数据块分配给这个segment。HWM通常增长的幅度为一次5个数据块,原则上HWM只会增大,不会缩小,即使将表中的数据全部删除,HWM还是为原值,由于这个特点,使HWM很象一个水库的历史最高水位,这也就是HWM的原始含义,当然不能说一个水库没水了,就说该水库的历史最高水位为0。但是如果我们在表上使用了truncate命令,则该表的HWM会被重新置为0。
BLOCKS 列代表该表中曾经使用过得数据库块的数目,即水线。
EMPTY_BLOCKS 代表分配给该表,但是在水线以上的数据库块,即从来没有使用的数据块。 ↩︎Overhead :块开销(Overhead),Oracle使用块开销(Overhead)来管理数据块自身。块开销不用于存储用户数据。 ↩︎
Data Dictionary Tables :静态数据字典(Data Dictionary Tables) ,存放了Oracle的数据库信息,用户可以通过数据字典来查看这些信息。数据字典是只读的,它是Oracle的最重要的部分之一,是由一组只读的表及其视图组成。 ↩︎
External Table :外部表(External Table) ,是指不存在于数据库中的表。通过向Oracle提供描述外部表的元数据,我们可以把一个操作系统文件当成一个只读的数据库表,就像这些数据存储在一个普通数据库表中一样来进行访问。外部表是对数据库表的延伸。 ↩︎
REF Column Types : REF游标(REF) ,游标是一种引用类型,引用类型与指针相同,它可以在程序运行时指定不同的存储位置。 在运行时游标变量也可以与不同的语句关联。游标变量类似于PL/SQL变量,可以在运行时接纳不同的值。静态游标类似于PL/SQL常量,因为它们只能与一个运行时查询关联。 ↩︎
Varrays :变长数组(Varrays) ,是一个存储有序的元素集合,而其每个元素都有一个相关索引,该索引相对应元素在数组中的位置。变长数组存在大小的限制,但是可以动态进行更改。 ↩︎
Nested Tables : 嵌套表(Nested Tables) ,嵌套表是表中之表。一个嵌套表是某些行的集合,它在主表中表示为其中的一列。对主表中的每一条记录,嵌套表可以包含多个行。在某种意义上,它是在一个表中存储一对多关系的一种方法。 ↩︎
Composite-Partitioned :复合分区(Composite-Partitioned) ,Oralce提供了以下几种分区方法:范围分区(Range-Partitioning)、列表分区(List-Partitioning)、哈希分区(Hash-Partitioning)、复合分区(Composite-Partitioned)。
如下图所示 前三个分区结构: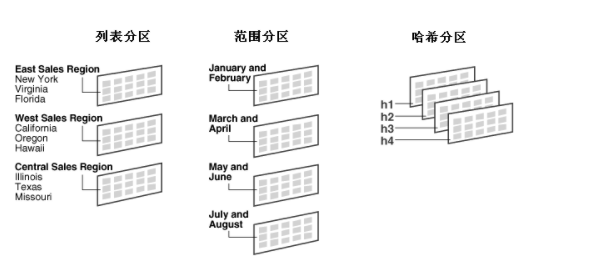
其中复合分区(composite partitioning)首先根据范围(range)进行分区,再使用哈希或列表方式创建子分区。复合范围-哈希分区既能够发挥范围分区的可管理性优势,也能够发挥哈希分区的数据分布(data placement),条带化(striping),及并行化(parallelism)优势。复合范围-列表分区能够发挥范围分区的可管理性优势,也能利用列表分区的显示控制能力。如下图所示复合分区(Composite-Partitioned)结构:
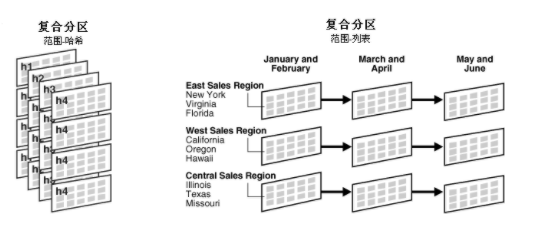
图片来自
↩︎Depth Of The Index :索引深度(Depth Of The Index) ,如下图所示为一个 3 阶的 B-Tree:,每次查询数据需要3次磁盘I/O操作,和3次内存查找操作。
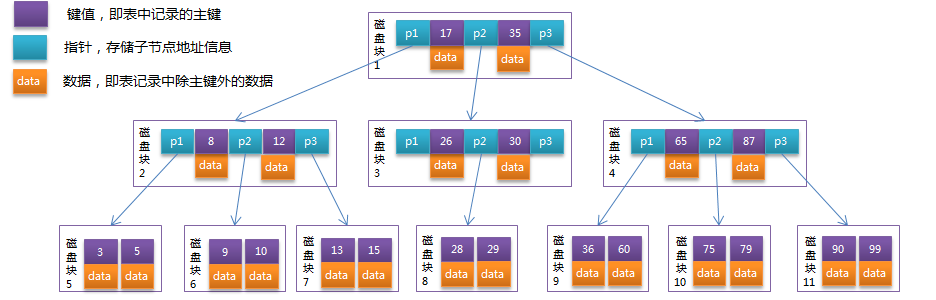
图片来自 ↩︎Root Block :根块(Root Blocks),B-Tree设计模仿植物的根茎叶关系,详见left block。 ↩︎
Leaf Blocks :叶子块(Leaf Blocks) ,Oracle 数据库使用 B-trees 存储索引,来加速数据访问。索引中的数据块,其树形结构分为三层:root block 根块、branch block 枝块、leaf block 叶块。其中枝节点用来检索,可以有多层(层数取决于数据量)。叶块特点为:①最低级别的索引块、②leaf block包含索引列和指向表中每个匹配行的ROWID值、③对于唯一索引, 每个rowid指向对应唯一地址。非唯一索引,按索引键和 rowid 排序、④由于平衡扩张特点,所有叶子节点索引深度相同、⑤双向链表:整个叶子节点部分是一个双向链表、⑥系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来。 ↩︎
Clustering factor :集群因子(Clustering Factor ),表示 熵-混乱程度,该值越低,表示存储的索引键的存储越有序。
Clustering Factor的计算方式如下:
(1)、扫描一个索引(large index range scan);
(2)、比较某行的rowid和前一行的rowid,如果这两个rowid不属于同一个数据块,那么cluster factor增加1;
(3)、整个索引扫描完毕后,就得到了该索引的clustering factor。
如果clustering factor接近于表存储的块数,说明这张表是按照索引字段的顺序存储的。
如果clustering factor接近于行的数量,那说明这张表不是按索引字段顺序存储的。
在计算索引访问成本的时候,这个值十分有用。Clustering Factor乘以选择性参数(selectivity)就是访问索引的开销。
如果这个统计数据不能真实反映出索引的真实情况,那么可能会造成优化器错误的选择执行计划。另外如果某张表上的大多数访问是按照某个索引做索引扫描,那么将该表的数据按照索引字段的顺序重新组织,可以提高该表的访问性能。 ↩︎Cluster :簇/集群(Cluster) 全称 表簇(Cluster Table) ,表簇(Cluster Table)是一组通过相同公共列-簇键(Cluster Key),构成的表的集合。
当构成表簇后,一个单独的数据块会包含多个表的数据行信息。
Oracle支持两种表簇,分别为索引表簇(Index Cluster)以及哈希表簇(Hash Cluster ) ↩︎Cluster Index :索引表簇(Cluster Index),
,构成的表的集合。
当构成表簇后,一个单独的数据块会包含多个表的数据行信息。
Oracle支持两种表簇,分别为索引表簇(Index Cluster)以及哈希表簇(Hash Cluster )
● 索引表簇(Index Cluster):oracle使用簇索引,将簇键键值与相应数据所在数据块地址(DBA)关联进行数据定位。
● 哈希表簇(Hash Cluster )哈希聚簇:oracle使用散列函数替代索引,计算出相应数据的物理存储位置,减少了针对索引块的I/O,进而实现了更快地定位。 ↩︎Cluster Key :簇键(Cluster Key),在1个簇表(Cluster Table)内,簇键(Cluster Key) 是指各簇键列(Cluster Key Column)的值。1个簇内有多个簇表(Cluster Table),簇表(Cluster Table)内各个数据行使用相同的簇键列(Cluster Key Column),在簇表(Cluster Table)及索引表簇(Cluster Index)中只会被存储1次。因此与非簇表(Nonclustered Table)相比,簇表(Cluster Table)存储表和表数据所需的空间会减少。每个簇键(Cluster Key) 的值只会存储1次,簇表(Cluster Table)中相关表所包含的相同簇键值的数据共享同1个簇键(Cluster Key)。 ↩︎
Materialized Views :物化视图(Materialized Views) ,视图模式的一种,将某个查询的结果集形成缓存,可以直接调用该结果集,加快查询效率。更新操作可以通过定时任务来调度,或当系统检测到原始数据的变化时触发。在其他情况下,可能需要手动重新生成视图。 ↩︎
Rowid :行主键-物理地址(Rowid) ,这里动态游标(REF)中通过指针指向表中的某一行数据,每行数据的主键都会有一个唯一的物理地址(rowid),游标(REF)中的地址(rowid)将会和实际表中的地址(rowid)进行比较,检查指针是否正确(是否能通过rowid找到表中某一行数据)。 ↩︎
Casecade :级联(Casecade) ,命令的一种。两张表通过主外键关联时,删除或更新主表时自动删除或更新从表中匹配的行。 ↩︎
Physical Rowids :物理地址(Physical Rowids) 。
Oracle使用rowid数据类型存储行地址,rowid可以分成2种,分别适于不同的对像
● 1. 物理地址(Physical rowids) :存储ordinary table,clustered table,table partition and subpartition,indexe,index partition and subpartition
● 2. 逻辑地址(Logical rowids) :存储索引组织表(IOT)的行地址
其中
用于存储物理地址(Physical rowids)的数据类型叫做 ROWID
用于存储逻辑地址(Logical rowids)的数据类型叫做Universal Rowid(UROWID),支持上述 物理地址(physical rowids) 和逻辑地址(logical rowids),并且支持非oracle table,即支持所有类型的rowid,但COMPATIBLE必须在8.1或以上. ↩︎Conventional Table :常规表(Conventional Table) 。这里指的应该是Oralce三种表:堆表Heap Table、索引组织表IOT 、聚簇表Cluster 中的【堆表Heap Table】 ↩︎
Universal Rowids :存储逻辑地址(Logical Rowids)的数据类型(Universal Rowids 或 UROWID),也可以叫通用地址 、全局地址。
Oracle使用rowid数据类型存储行地址,rowid可以分成2种,分别适于不同的对像
● 1. 物理地址(Physical rowids) :存储ordinary table,clustered table,table partition and subpartition,indexe,index partition and subpartition
● 2. 逻辑地址(Logical rowids) :存储索引组织表(IOT)的行地址
其中
用于存储物理地址(Physical rowids)的数据类型叫做 ROWID
用于存储逻辑地址(Logical rowids)的数据类型叫做 Universal Rowid(UROWID),支持上述 物理地址(physical rowids)和逻辑地址(logical rowids),并且支持非oracle table,即支持所有类型的rowid,但COMPATIBLE必须在8.1或以上.
● UROWID定义:
UROWID(可以称为通用ROWID,逻辑ROWID,全局ROWID), 表的行地址,表指的是index-organized tables。IOT中物理rowid是可能变化的,另外Oracle要依靠rowid来建立表的索引,所以对索引组织表(IOT)来物理rowid就不行了。Oracle以表的主键为基础引入UROWID,在物理rowid基础上建立了第二个索引。每一个逻辑rowid使用一个第二索引和一个物理推测(IOT中标识块的行)。
上面所说物理地址(Physical Local)不支持索引组织表(IOT)。是因为更新IOT的主键可能导致ROWID改变(ROWID改变即物理地址发生变化),但UROWID(逻辑地址)不会变化。 ↩︎















 1840
1840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









