







目录
相关链接
Teradata数据中心 —— 采集流程优化
首先大致简单介绍一下背景。
目前工作中,负责数据平台(数据仓库)的搭建。作为金融证券公司,这里使用的是Teradata数据库。跑批时任务调度工具为Automation。
作为数仓的第一步就是要统一数据源,将各类异构数据库(各上游柜台系统出现频率为 Oracle(贵,稳定) > SQLServer贵,稳定> MySQL开源,便宜> PostGreSQL开源,便宜> H2几乎没见过 > DB2几乎没见过;这里体现了金融机证券构不缺钱,只需要系统稳定)统一数据源为 Teradata 。而这里就会出现许多问题,例如:
- 1.异构数据库兼容问题
- 1.1 数字类型
- 支持数据范围不同
- MySQL(8) :DECIMAL(M,N) M最大值为65。
- Teradata :DECIMAL(M,N) M最大值为38。
- 这里就需要采集之前,调研人员需要确认如何存储,这里可以用VARCHAR类型去加载到数仓中,但不方便下游使用数据。或者很了解这个字段的业务情况,确定该值最大不会超过38位,那么也可以用DECIMAL(38,0)去加载上游的DECIMAL(65,0)。但依然有加载失败的风险。
- 支持数据范围不同
- 1.2 时间类型
- 支持数据范围不同
- MySQL(8) :中 DATETIME 类型(YYYY-MM-DD hh:mm:ss)可以存储 ‘0000-00-00 00:00:00’ (虽然看到参考文章中支持范围是1000-01-01 到 9999-12-31,但加载中确实遇到了0000-00-00 00:00:00 这样的数据,可能是版本迭代问题吧) 。
- Teradata :中 TIMESTAMP(0) 类型 (YYYY-MM-DD hh:mm:ss)不能加载 ‘0000-00-00 00:00:00’
- 需要在抽取数据时用CASE WHEN 判断数据,将不能加载的异常数据处理为NULL 。
CASE WHEN COL_DATETIME <= '0000-00-00 00:00:00' THEN NULL -- 这里不确定会不会出现负数,万一出现负数也处理掉 ELSE COL_DATETIME END AS COL_DATETIME
- 数据格式不同
- SQLServer :某些日期类型(没有具体研究)数据格式为YYYY-MM-DD 。
- Teradata :TIMESTAMP(6) 数据格式为 YYYY-MM-DD,查询时显示格式为 YYYY/MM/DD,但加载数据文件时需要格式为 YYYYMMDD(这里也没搞懂)。
- 由于带 - 符号不能加载,所以需要在抽数脚本中将-处理掉。
REPLACE(COL_DATETIME,'-','')
- 支持数据范围不同
- 1.3 LOB类型
- 加载问题
- Oralce(11g):LOB类型支持2GB存储空间;CLOB、NCLOB支持4GB存储空间。
- Teradaata :CLOB类型支持4GB存储空间,但加载使用 FASTLOAD不支持CLOB类型。
- 大部分CLOB类型默认不采集(一些无用信息或xml信息),但也有特殊情况,则需要在抽数脚本中单独进行处理。
- 加载问题
- 其他类型
- 不支持加载
- Oralce(11g):XML_TYPE、RAW
- SQLServer :bit、text、ntext、varchar(max)、nvarchar(max)
- MySQL(8) :TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT
- 以上类型Teradata不支持存储,或text这种过长类型采集容易报错,非业务必要字段一般直接置空处理。
- 不支持加载
- 1.1 数字类型
- 2.其他问题
- 2.1 自定义数据类型
- SQLServer :可以自定义数据类型,直接查看DBeaver看到的数据类型是不能用的。

- 通过sql查询系统表 dbo.systypes.name 字段可以拿到原始类型
- SQLServer :可以自定义数据类型,直接查看DBeaver看到的数据类型是不能用的。
- 2.2 Schema问题
- Schema(模式),在一个库下可以多个Schema,默认Schema为dbo,以下为统计目前遇到的情况(不代表所有)
SQLServer √,Oracle × ,MySQL × ,PostGreSQL × - 抽数脚本中需要用 FROM 库名.模式名.表名 才可以
- Schema(模式),在一个库下可以多个Schema,默认Schema为dbo,以下为统计目前遇到的情况(不代表所有)
- 2.3 大小写敏感问题
-
一些上游系统大小写敏感,则抽数脚本(SQL)中需要字段及库名的大小写与上游保持一致
常见于SQLServer数据库,偶尔Mysql数据库也会出现。 -
以SQLServer为例:SQL查询sys.databases表,name为库名,collation_name为排序规则 ,可通过以下SQL获取,或人工测试SQL大小写是否敏感。
CASE WHEN sys.databases.collation_name like '%[_]CI[_]%' THEN 'Y' --ignore WHEN sys.databases.collation_name like '%[_]CS[_]%' THEN 'Y' --sensitive WHEN sys.databases.collation_name like '%[_]BIN%' THEN '二进制排序,Y' ELSE NULL END AS "大小写敏感"
-
- 2.1 自定义数据类型
以上只列举了一些场景问题,还有许多非常见问题还需要单独处理。
- 特殊问题
- 这里只遇到过一次,Mysql数据库中 BIGINT 类型范围-263到263-1(即-9,223,372,036,854,775,808 到 9,223,372,036,854,775,807) ,上游使用某字段存储密码(就假设字段为COL_PWD),COL_PWD中出现了 9,223,372,036,854,775,807 这个值(最大值),由于全量抽取时在ODS任务逻辑中会对数字+1(大致是为了处理0和NULL,与之前的数据进行比较看有无重复数据,如果是重复数据则不入到ODS层,而0和NULL不能进行比较,所以这里+1)后溢出,导致ODS任务失败
- CASE WHEN特殊处理异常数据
CASSE WHEN COL_PWD = 9223372036854775807 THEN 9223372036854775806 ELSE COL_PWD END AS COL_PWD
-----------------------------------------------------------分割线-----------------------------------------------------------
而之前处理流程的怎么样的呢?
1. 调研人员连接上游系统(使用开源工具DBevaer)
=> 2. 拍照获取表结构 (这里如SQLServer的自定义类型就会出问题;或者需要采集的是视图,视图类型的表结构是数据库自动生成,仅供参考的,如果以此为标准整理表结构则大部分表结构都是错的)
=> 3. 整理表结构文档 (手敲,常见问题有 中文逗号,中文括号,数据类型少参数,如DECIMAL(2),还会出现串行,或字段名称打错的问题)
=> 4. 提供采集方式(增量、全量、滑动)以及增量条件(这里经常只给增量字段,一般为日期,但没有给增量条件,就可能导致抽取报错,采集jar包中的增量字段为TX_DATE_Ext,格式为’YYYYMMDD’ ,增量字段格式需要和其保持一致,否则抽取可能会报错)
=> 5. 提供表结构给数据开发人员,制作采集投产包(需要自己转字段类型,如NUMERIC(5,2) 替换为(DECIMAL(5,2) )
=> 6.出现各种问题,建表失败(如上游字段为Teradata关键字,建表语句中有中文逗号 括号等)
=> 7.测试环境反复测试(只能测试建表及调度配置,大部分系统没有测试环境不能测试抽取过程)
=> 8.实际投产又遇到新问题,抽数失败(字段名称不对),数据加载失败(上游varchar类型,调研给出integer),字段溢出(上游TEXT类型,调研给出VARCHAR(4000),但仍不够),数据量过大,任务长时间跑不完(大概每日日终表S层跑批时间都不会超过十分钟,时间过长就要改增量或滑动了)。
=> 9.反复调试,直到投产成功(这里需要反复删表,建表,删加载日志,手动修改任务上次跑批时间,重新抽取,重新触发任务,查看报错日志,查看报错文件,找到报错字段……,就算投产成功,因为有些表是新表,数据量不大,当时没有报错,跑批几天后某条数据溢出又会开始报错。)
-----------------------------------------------------------分割线-----------------------------------------------------------
经过优化后的处理方式
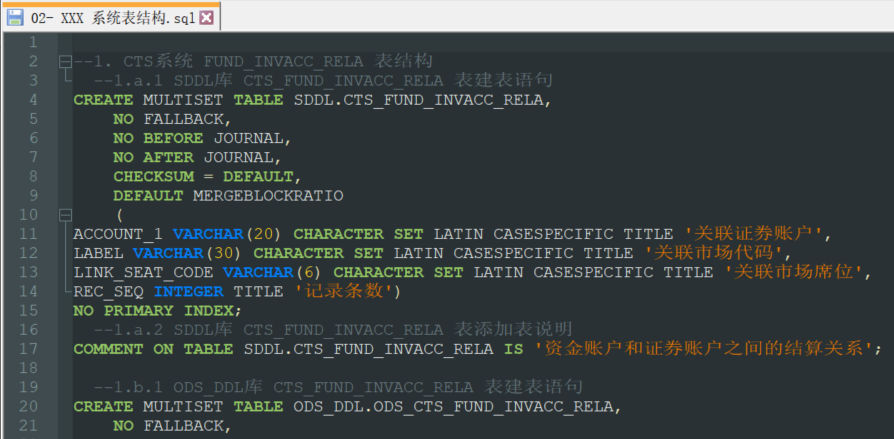
1.使用SQL获取表结构,各数据库查询字段保持一致(每个数据库系统表都不一样,需要挨个百度,反复测试后才可投入使用。目前已有的Oracle,SQLServer,MySQL,快要完成的有PostGreSQL)。
=>2.如果是表则可以直接使用,如果是视图则需要同时下载DDL(建视图语句)及DDL中出现所有表的表结构,手动整理(在SQL中直接查出表类型,所以可以方便获取,这里杜绝了下载表结构时不知道是表还是视图,按视图提示字段直接提供调研文档的问题)。
=>3.检查提示为???的字段,并手动提供字段类型(异构数据库支持范围不同,需要查看实际数据确认,极端情况可能用字符类型来接收数值类型保证数据不会溢出)
=>4.使用模板 【00.调研表结构转换模板】
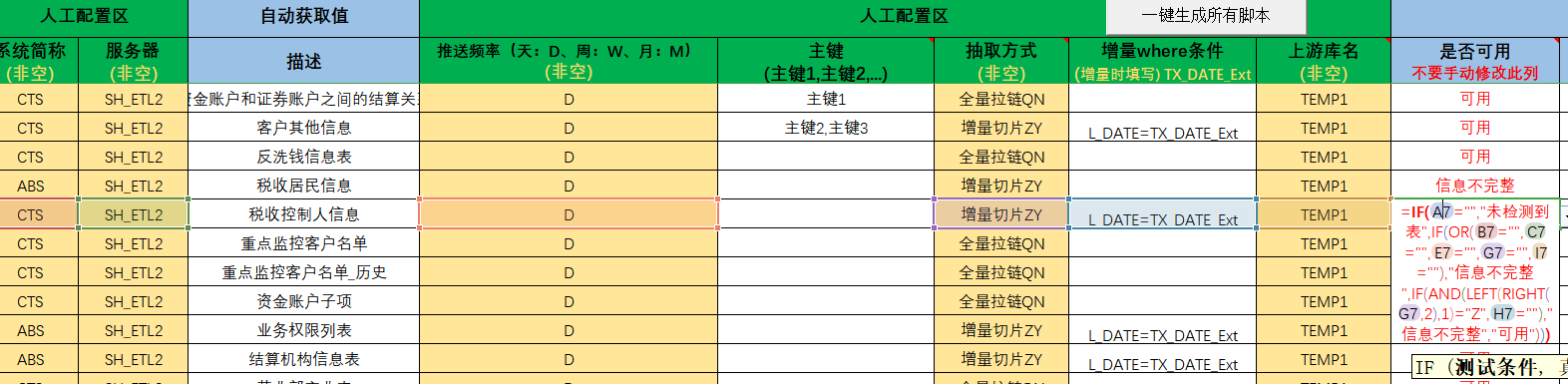
(自研开发。这里数据格式均来自SQL查询获取。按照颜色填写绿色列,蓝色列为相应逻辑判断抑或拼接SQL的公式。
如下图,使用EXCEL函数及VBA功能,自带校验功能,还可以将最终表结构,采集方式都输出为本地文件,便于下一步使用)
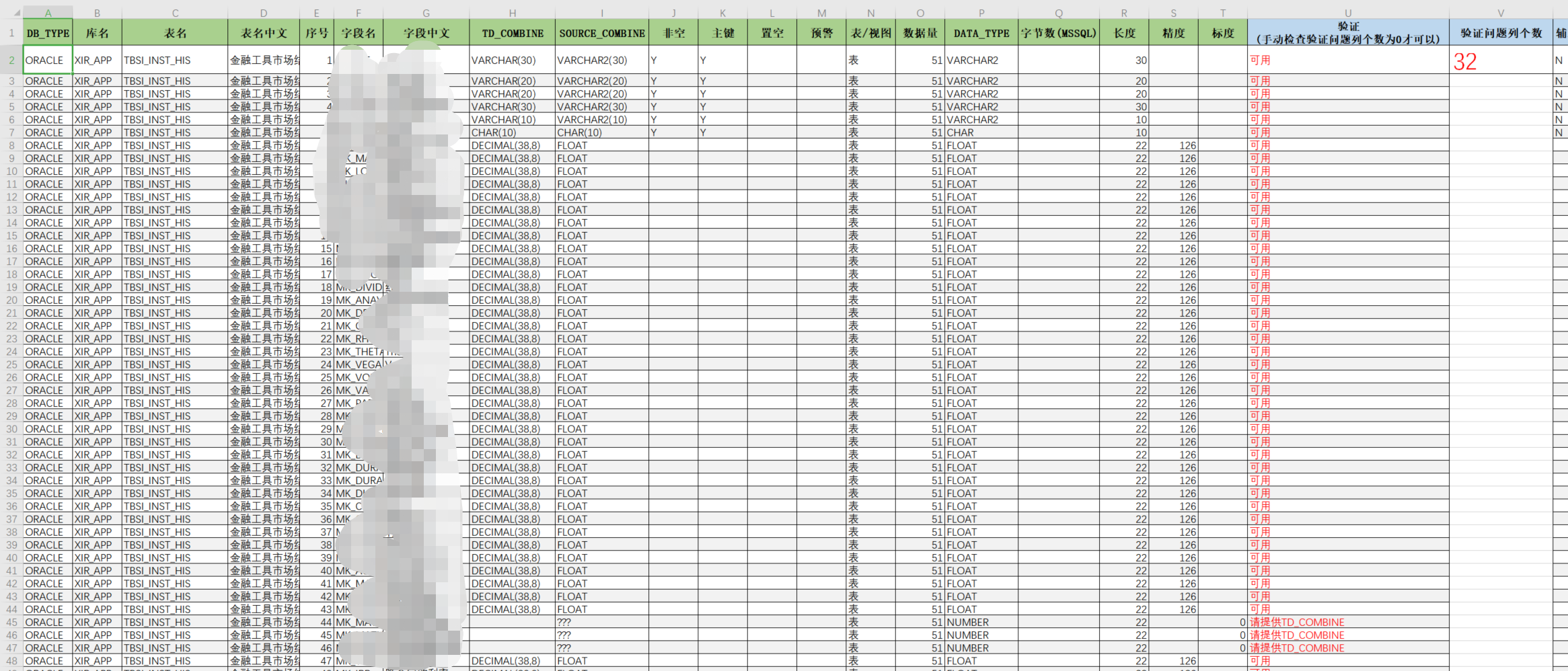
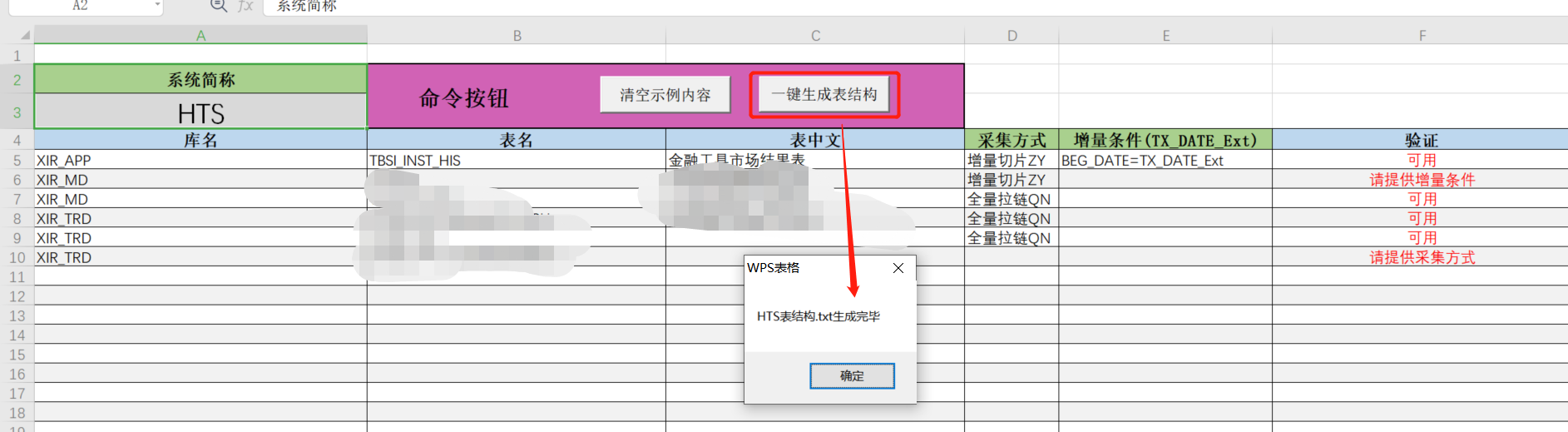
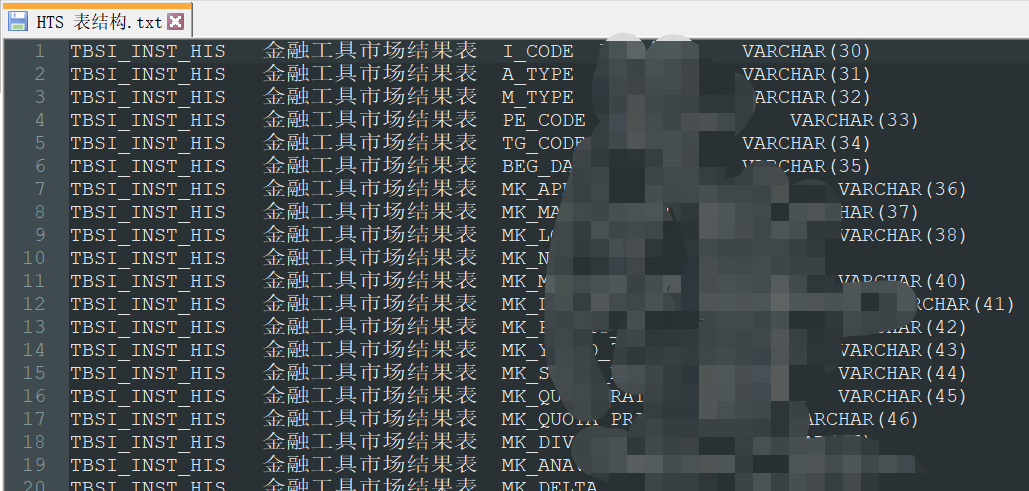

=>5.使用模板【01.采集模板】(自研开发。将生成的 表结构.TXT、表结构-表头.TXT 文件直接粘入采集模板中,填入相应信息,这里仅需要按照颜色填写绿色列,蓝色列为相应逻辑判断抑或拼接SQL的公式)
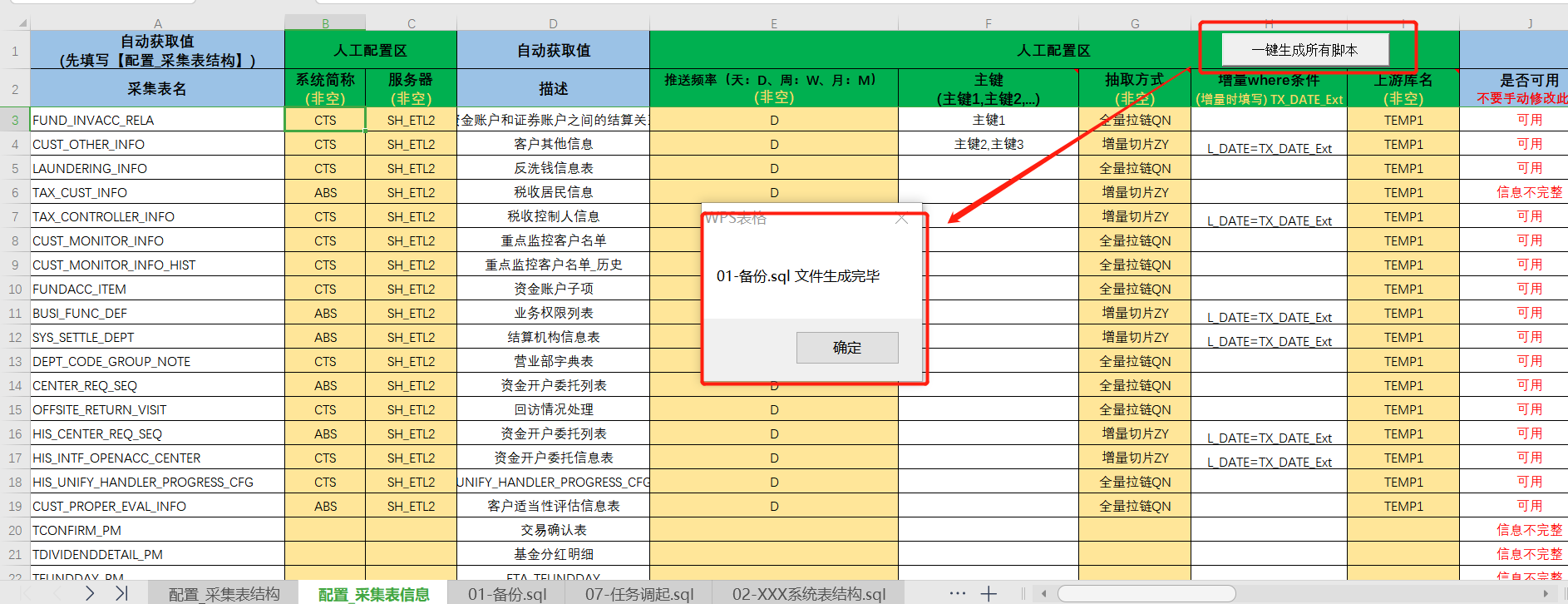
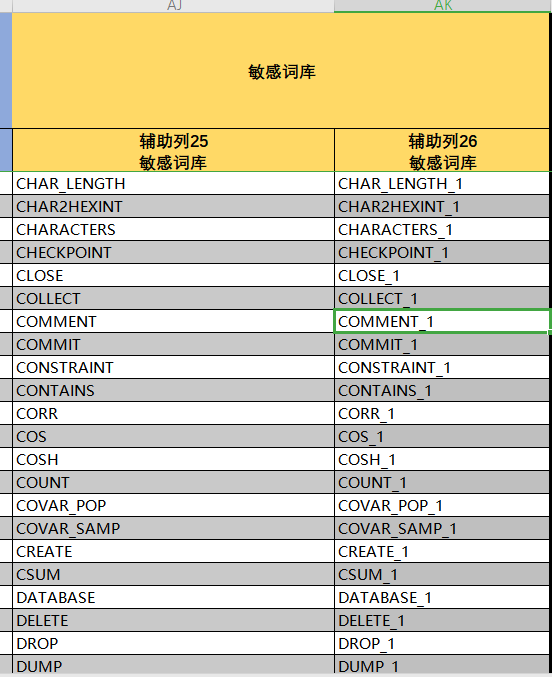
各类逻辑校验,包括Teradata关键字也需要判断,这里采用了VLOOKUP查询到关键字词库中与上游表结构中字段一致,需要建表时为表名拼接_1 (这里需要注意原表抽数脚本SQL还是要用原始名称)
=>6.到这基本上不会出现什么问题,唯一可能出问题的地方有【视图类型】或表中【???类型】的字段(人工调研的字段类型)
=>7.所有操作都用命令完成,包括人物调起,修改增量条件等,投产效率及正确率UPUPUP
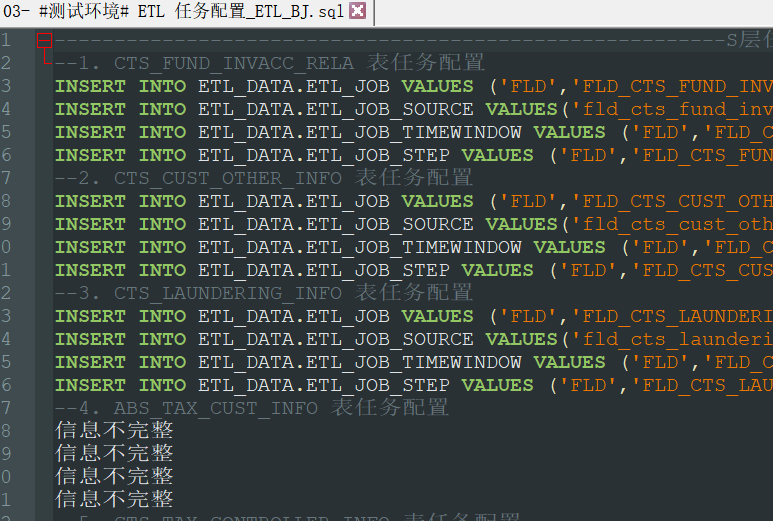
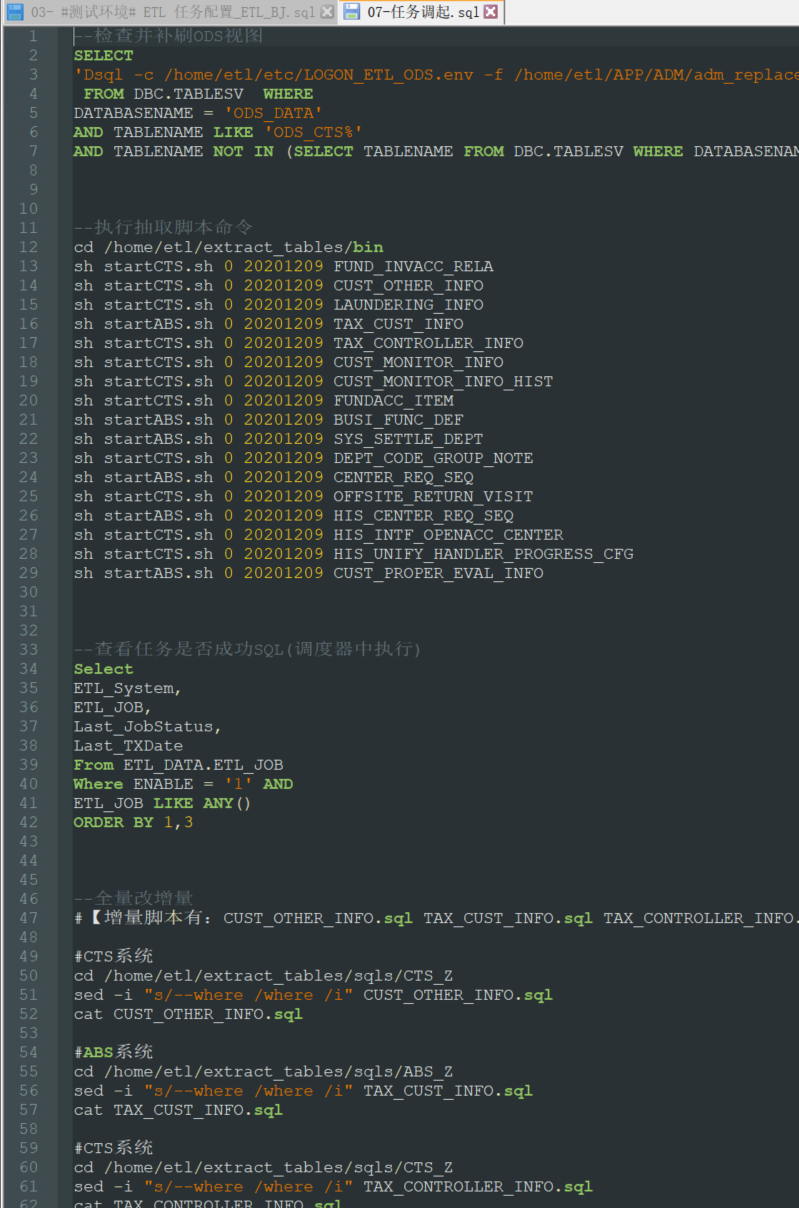
至此,从调研到规范步骤及避开各种坑,对比上述所有的问题,基本都已解决。
-----------------------------------------------------------分割线-----------------------------------------------------------
除此以外,推送,变结构变更,数据脱敏,包括KETTLE推送任务都自研模板(【kettle竟然记事本就可以编辑? KETTLE码表及原理】)
投产基本一次通过,发现问题维护EXCEL模板就好了,从此凭实力过上了从来不加班的快乐生活(还有时间写写博客)
20/12/30
M















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









