







字符串驻留
对相同的字符串只保留一份拷贝,后续创建的相同字符串 不会开辟空间 而是把该字符串的地址赋给新创建的变量
因为python会把创建的字符串放在字符串池中 需要时就拿出来使用 避免频繁创建和销毁
拼接时join比+好 因为join()会先计算出所有字符中的长度再拷贝 只new一次对象
a = 'asd'
b = "asd"
c = '''asd'''
a is b# true
b is c# true
发生驻留的集中情况
1.字符串的长度为0或1时
2.符合标识符的字符串(编译器可以忽略这个)
a = '123%'
b = '123%'
a is b#false 因为%不是标识符 标识符是字母数字下划线
3.字符串只在编译时进行驻留 运行时不驻留
a = 'abc'
b = 'ab'+'c'#在运行之前就已经连接完毕了
c = ' '.join(['ab','c'])#输出也是abc 程序运行的时候才合并的
a is b#true
b is c#false
4.[-5,256]之间的整数数字
查找
count(查找有几个)
a.cout(‘想要找的字符’,起始点,终止点)#[起始点,终止点]
a = "abada"
a.count('a')#3
a.cout('a',0,2)#2
find(查找在哪)
a = "ababa"
a.find("b")#1从左往右
a.rfind("b")#3从右往左找第一个
index和find的区别在于如果没找到index直接抛出ValueError异常 find返回-1
index和find找出字串第一次出现的位置 rindex和rfind找出最后一次出现的位置 返回的是负索引
startswith(查找第一个是否是这个字符串)
endswith同样 查找
startswith(“a”,1,4)#从这个区间开始算是否是第一个
x = "abcdefg"
x.startswith("abc")#true
x.startswith("bc",1,3)#true
x.startswith("f",2,5)#true包括最后一个
使用方法
x = "小明参加了活动"
if s.startswith(("小明","小红","效率")):
print("有人参加活动")#有人参加活动
常用操作
转换
upper 全转大
lower 全转小
swapcase 大转小 小转大
capitalize 第一个字符变大写 其他小写
title 每个单词的第一个字符变大写 其余变小写
istitle 判断每个单词的第一个字符是大写吗
isupper 判断所有字母是否都是小写
可以s.upper().isupper()#一定是true
isalpha 判断字符串是否全是由字母构成
isspace 判断字符串是否为空字符串 " \n\t"#true 空格制表符和他们俩的转义字符都算空白字符
isprintable 判断字符串是否能打印 含有转义字符是不能打印的 返回false
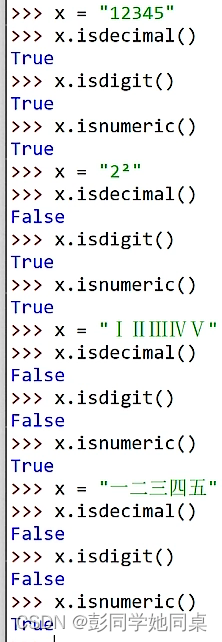
判断字符串中是否全是数字
isalnum 集大成者 只要是isalpha,isdecimal,isdigit,isnumeric中任何一个返回的是true 他就是true
isdecimal 只能容忍1234这样的是数字
isdigit 能容忍数学符号和1234
isnumeric 什么都能容忍 罗马数字 中文数字 1234 繁体都行
这些转化后都是新的字符对象
expendtabs(4)将字符串中的tab转换成4个空格
replace(old,new,count) 将字符串中old字符串替换成new字符串 替换count次 默认值count是-1 也就是默认替换全部
translate(转换表格) 根据转化表格对字符串进行替换
str.maketrans(要被替换字符串,替换字符串,要被忽略字符串)
table = str.maketrans("abcdefg","1234567","不要不要")#这个置换表格表示了 a要替换成1 b要替换成2 c要替换成3以此类推依次替换 并且忽略"不要不要"
"我不要不要是第a个,快来啊第cde个".translate(table)#我是第1个,快来啊第345个
对齐
center 居中 第一个参数指定宽度 第二个参数指定填充符号 默认是空格
ljust左对齐
rjust右对齐
zfill 右对齐 左边用0填充 只接受一个参数
分割
split(sep, maxsplit) 左边分割 默认以空格作为分割 返回列表
sep为分隔符 maxsplit最大分割次数
str = 'abcabca'
print(str.split('a'))#['', 'bc', 'bc', '']
#输入时用空格分割
a,b,c = map(int, input().split())
partition()以某个指定字符做分割
从左往右找这个字符 然后进行依次分割
"www.baidu.com".patition(".")#("www",".","baidu.com")
"www.baidu.com".rpatition(".")#("www.baidu",".","com")
strip()剔除
默认是剔除空格
" 左侧不留空白".lstrip()#左侧不留空白
" 右侧不留空白 ".rstrip()#右侧不留空白
" 左右不留空白 ".strip()#左右不留空白
指定剔除
左右的剔除规则是
例如lstrip(“wcom.”) 是从最左边开始匹配 逐字符找是否和wcom.中的字符匹配的 只要有就剔除 直到找到第一个不匹配的就停止
str = "www.ilovefishc.com"
str.lstrip("wcom.");#ilovefishc.com
str.rstrip("wcom.");#www.ilovefishc
str.strip("wcom.");#ilovefishc
sep指定分割符 maxsplit指定最大分割次数
rsplit 右边分割
连接
join()
".".join(["www","baidu","com"])#"www.baidu.com"
"".join(("aaa","bbb"))#aaabbb
#等价于 但是下面这种效率更低
x = "aaa"
y ="bbb"
s = x+y
判断

替换
replace()
第一个参数指定被替换字串
第二个参数指定替换字串的字符串
第三个参数指定最大替换次数
原字符串不变 产生新的字符串
s = 'abcbaccd'
b = s.replace('c','bbb',3)
print(s)#abcbaccd
print(b)#abbbbbabbbbbbd
join()
将列表或元组中的字符串合并成一个字符串
获得原始值ord()和原始值的字符chr()
print(ord('a'))# 97
print(chr(97))# a
切片
s[起始点:终止点:步长]
s = 'abcde'
ss = s[2:]#cde
a = s[::-1]#edcba
格式化
name = '张三'
age = 13
print('我叫%s,今年%d岁'%(name,age))
print('我叫{0},今年[1]岁'.format(name,age))
print(f'我叫{name},今年{age}岁')
print('{0:10.3}'.format(age))#10表示宽度 .3表示只显示三位数 .3f才是显示三位小数
ord()将单个字符转换成编码
print(ord('a'))#97
填充
format(可以被f替换)
f字符串
下面的一切都可以被f替换
name = "张三"
age = 12
sex = "男"
"我叫{},我今年{}岁了,我是{}生".format(name,age,sex)#我叫张三,我今年12岁,我是男生
# 可以被写成
f"我叫{name},我今年{age}岁了,我是{"男"}生"#我叫张三,我今年12岁,我是男生
fill = '+'
align = '^'
width = 10
prec = 3
ty = 'g'
"{:{fill}{align}{width}.{prec}{ty}}".format(3.1415,fill,align,width,prec,ty)#+++3.14+++
f"{3.1415:{fill}{align}{width}.{prec}{ty}}"#+++3.14+++
索引
name = "张三"
age = 12
"我叫{},我今年{}岁了,我是{}生".format(name,age,"男")#我叫张三,我今年12岁了,我是男生
#可以填入索引
"我叫{1},我今年{1}岁了,我是{0}生".format(name,age,"男")#我叫12,我今年12岁了,我是张三生
# 关键字
"我叫{name},我今年{age}岁了,我是{sex}生".format(name = "张三",age = "12",sex = "男")#我叫张三,我今年12岁了,我是男生
# 可以混合使用
"我叫{name},我今年{1}岁了,我是{sex}生".format(name = "张三",age = "12",sex = "男")#我叫张三,我今年12岁了,我是男生
{}中的格式
填充和对齐
"{1:%>10}{0:q<10}.format(111,000)"#%%%%%%%000111qqqqqqq
"{:0=10}".format(-520)#-0000000520也就是-号为符号 520是数字 所以0在这之间进行填充
第一个1表示用索引1的对象 也就是111
第二个:表示后面规定格式
%表示用%来填充多余位置
>表示向左对齐 <表示向左对齐 ^表示居中 =表示将填充放置在符号(如果有)之后但是在数字之前的位置
10表示占是10个位置
正负号显示
"{:+}{:+}".format(1,-1)#+1-1
"{:-}{:-}".format(1,-1)#1-1 这种是默认的
"{: }{: }".format(1,-1)# 1-1
分隔符
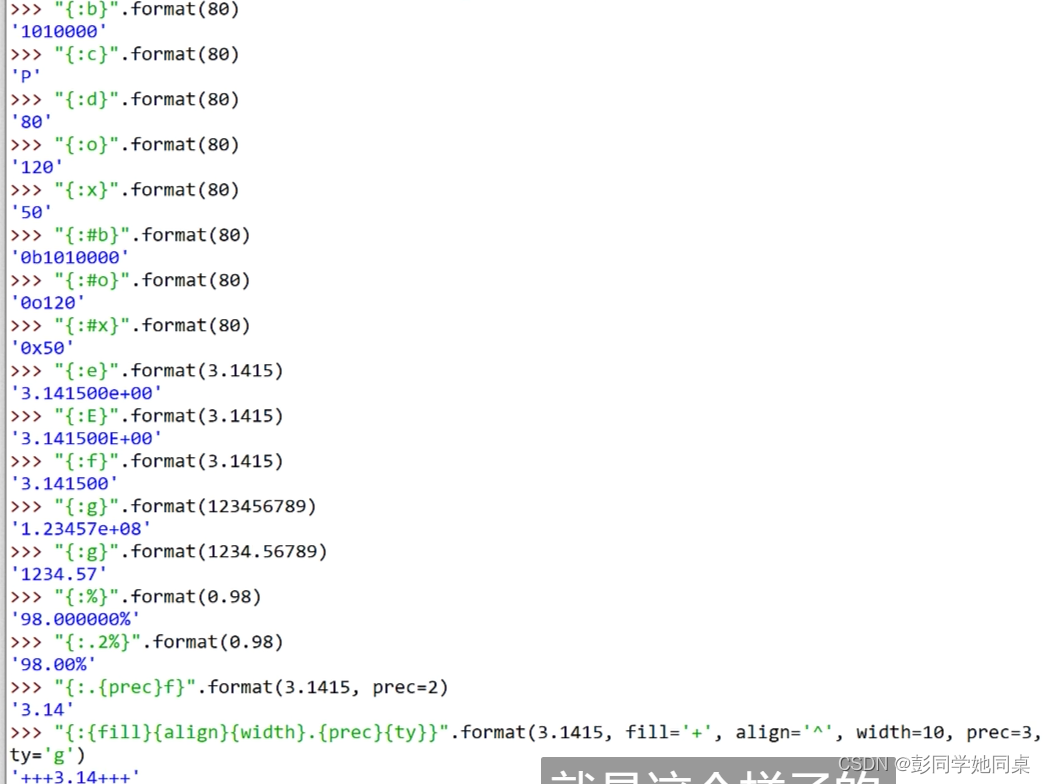
“{:,}”.format(12345678)#12,345,678 千位进行分割
“{:_}”.format(12345678)#12_345_678 千位进行分割
显示多少位
“{:.2f}”.format(3.14)#3.14表示小数点后只能显示2位
“{:.2g}”.format(3.14)#3.1表示小数点前后只能显示2位
“{:.4}”.format(“abcdefg”)#abcd表示截取4位
“{:.2}”.format(312334)#报错 不能用于整数
输出格式

map()
返回的是迭代器 迭代器只能使用一次
长度不一致选短的
a,b = map(int,input.split())//多对象输入
x = map(ord,"FishC")//将"FishC"字符串执行ord函数 ord就是转换成ascall码表的数
print(list(x)) #[70,105,115,104,67]
x = map(pow,[1,2,3])# 执行pow函数 [1,4,9]
x = map(pow,[2,3,10],[5,2,3])#[32,9,1000]
filter()
返回迭代器
与map的区别是 只有结果是true的才会被筛选出来
x = filter(str.islower,"Fish")#['i','s','h']只有小写能被筛选出来















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









