







Leader-Based Multi-Scale Attention Deep Architecture for Person Re-Identification
Architecture for Person Re-Identification)
3 MULTI-SCALE DEEP ARCHITECTURE (MUDEEP)
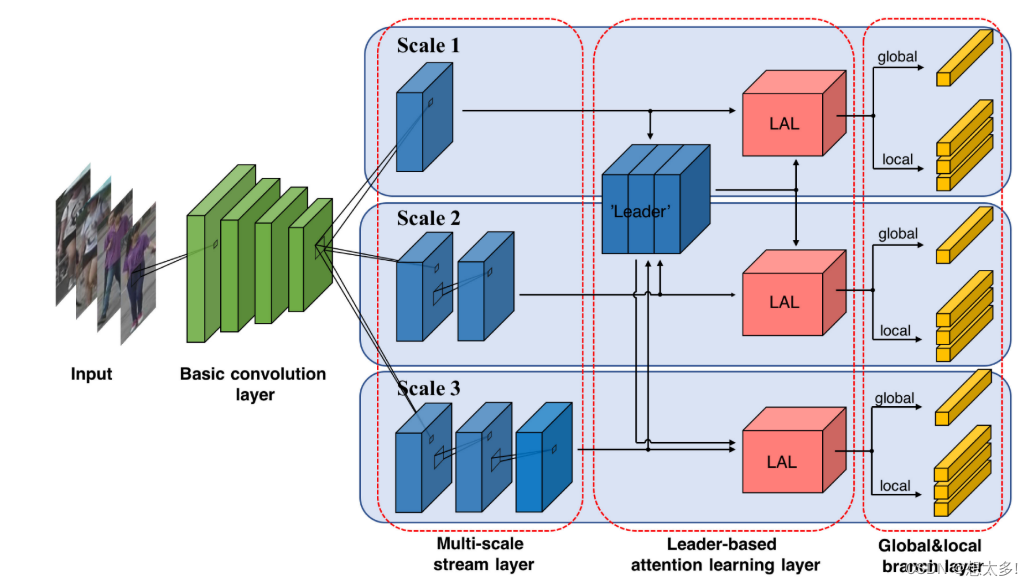
3.1 Basic Convolution Layer
Fig. 3
- Applied here to extract the middle-level featuresof input person images
- we apply ResNet-50 as our basic convolution layer,but remove the last block of ResNet-50,our basic convolution layer only consists of the con1, res2, res3 and res4 blocks.
Fig. 3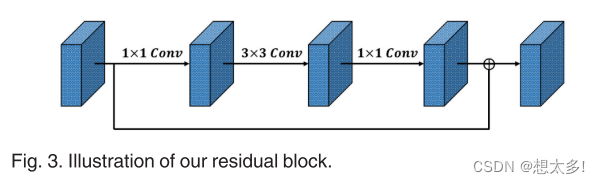
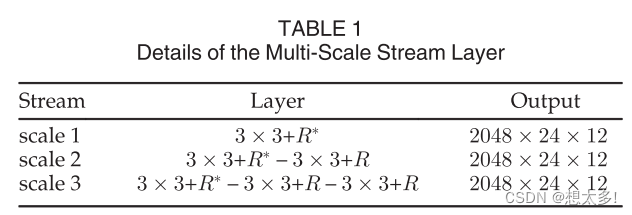
3.2 Multi-Scale Stream Layer

- 在三个尺度上分别是1个3x3的过滤器,2个级联的3x3过滤器,3个级联的3x3过滤器
- 开始有一个1x1卷积层压缩和提炼关键特征,最后另一个1x1卷积层将特征图恢复到原始的通道数。
TABLE 1,Details of the Multi-Scale Stream Layer
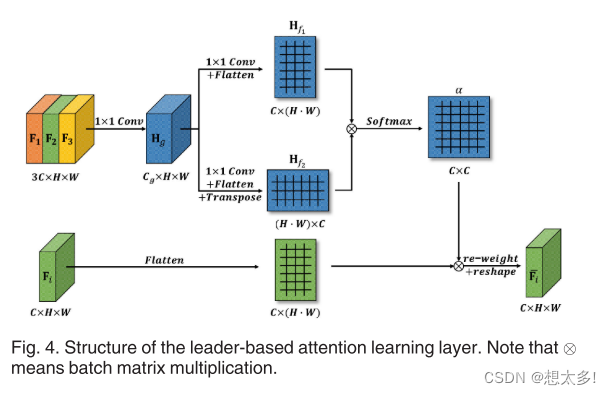
3.3 Leader-Based Attention Learning Layer
Question:the resulting data channels at different scales may have redundant information
Solution:利用基于领导者的注意学习机制来引导多尺度流层的输出,并自动发现和强调具有更有区别性特征的通道
Fig. 4, Fi 是第 i 个数据流的特征图
- F1、F2和F3的特征图首先连接形成“Leader”,因为它需要从多个尺度看到图像。
- 然后通过卷积层,与引导通道Cg生成引导特征Hg
- 接着,用自注意力机制计算来自两个特征空间的注意力图α
- 最后,利用Soft-max函数对Fi重新加权
3.4 Global and Local Branch Layer

3.4.1 Global branch
全局特征是直接从全局平均池化中提取的
3.4.2 Local branch
局部分支:在特征映射上水平应用全局平均池的操作——水平的全局平均池化,提取M个局部特征(M x C x 1 x 1)。
最后,在所有特征后使用一个1x1的卷积层用来降维,因此,在全局和局部分支层之后,每个尺度都将得到一个全局特征和M个局部特征


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









