







随着多媒体内容的爆炸式增长,视频分析的重要性日益凸显。传统的2D图像处理技术虽然在空间特征提取方面表现出色,但在处理时间连续性方面却显得力不从心。来自Facebook AI Research和达特茅斯学院的研究团队提出了使用 3D卷积网络(3D ConvNets) 来学习视频的时空特征,这一创新方法在多个视频分析基准测试中展现了优越的性能。
3D卷积与池化
3D卷积网络的关键特点在于能够同时捕捉空间和时间的信息,与传统的2D卷积有显著不同。
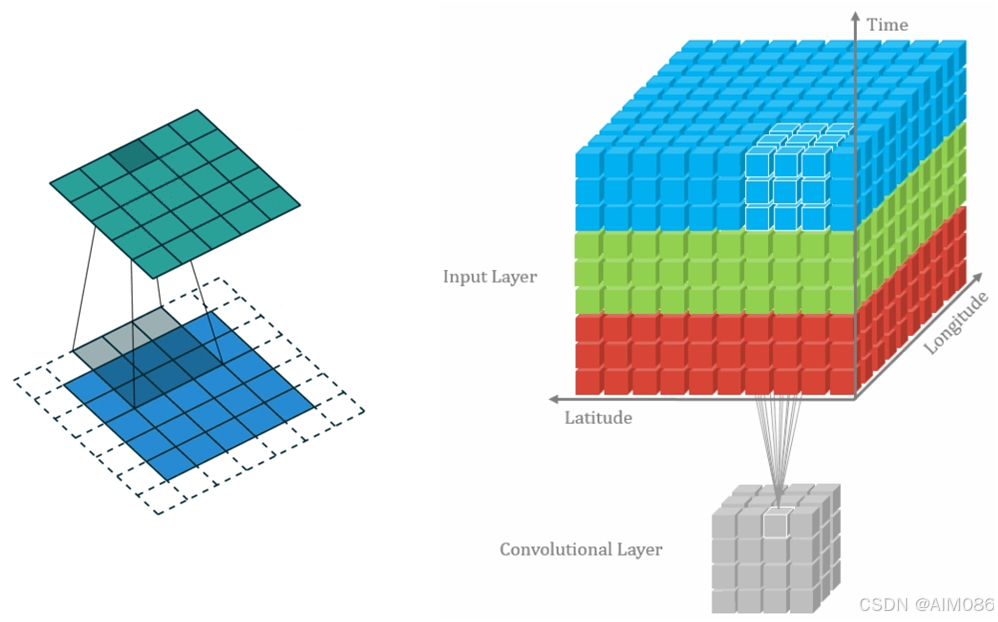
原理:在视频处理中,一个 的三维卷积核被应用于
大小的视频数据块(三维体)。在卷积操作中,卷积核覆盖的每个
的立方体区域内的 27 个像素值与卷积核的27 个权重相乘后求和,生成对应的新特征图中的单个像素值。随后,卷积核按照设定的步长在视频数据的高度、宽度和时间轴上滑动,重复上述操作。与2D卷积核不同,它只在图像的高度和宽度方向上滑动,3D卷积核还需在时间轴方向上进行滑动,从而有效捕捉视频内容随时间的变化,进一步丰富了模型的时空表征能力,能够更有效地捕捉运动和动态特征。
2D卷积的局限性:
- 2D卷积处理的是单帧的空间信息,输出的仍然是单帧图像。
- 即使将多帧作为输入(例如将帧叠加成多个通道),2D卷积在第一层卷积后会丢失时间维度信息。
3D卷积的优势:
- 3D卷积在空间和时间三个维度上操作,输出的是一个包含时序信息的体积。
- 3D池化与3D卷积配合,能够在整个网络中保留时间维度信息,而非仅限于初始层。
探索卷积核的时间深度
文章通过实验探索了不同时间深度卷积核对3D卷积神经网络性能的影响。
先说结论:使用 卷积核的小感受野架构效果最好。
实验前提:输入视频被处理为大小为 (通道数、帧数、高度和宽度)的片段,网络由5层卷积层(每层后接池化层)组成,空间卷积核大小固定为
,时间深度分别设置为1、3、5和7。
实验设计:实验设计了两种架构:均匀深度(如 仅depth-1 或 仅depth-3)和层间变化深度(如从depth-3到depth-7递增或从depth-7到depth-3递减)。实验结果显示,depth-3 的准确率最高,depth-1(相当于2D卷积)表现最差,原因在于无法有效建模时间信息。最终得出结论:采用小感受野的 卷积核能够最好地捕捉时空特征。
C3D
通过探索卷积核的时间深度和网络架构设计,作者提出了一种标准化的3D ConvNet架构(命名为 C3D),能够有效捕捉视频的时空特征。

C3D网络包括了 8层卷积、5层最大池化和2个全连接层,最后是softmax输出层。卷积核大小固定为 ,步幅为1,每个框中都标明了卷积核的数量。除了第一个池化核是
之外(第一层池化在时间维度为 1),其他池化核大小为
。
为训练C3D网络,作者使用了包含110万段视频的 Sports-1M数据集,并采用数据增强方法对输入数据进行随机裁剪和水平翻转,生成大小为 的子片段。优化过程中,使用随机梯度下降(SGD),初始学习率为0.003,每15万次迭代减半,从而使模型能够高效捕获视频的时空特征。
实验表明,C3D 网络在建模运动和外观信息上表现出色,并且对多种视频分析任务具有良好的通用性。

















 1108
1108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









