







文章目录
- Hive中函数有4类:单行函数、聚合函数、炸裂函数、窗口函数。
用户定义函数(UDF:User-Defined Functions)
按输入行数与输出行数的对应关系:

1. 单列函数 (UDF - 一进一出)
单列函数在前面已经介绍过:【Hive—10】单列函数『字符串函数 | 日期函数 | 数学函数 | 集合函数 | 条件函数 | 数据脱敏函数 | 其他函数(反射、加密解密、等等)』
2. 聚合函数 (UDAF - 多进一出)
group by关键字和聚合函数是一对好基友。一般有group by关键字就会使用聚合函数。
2.1 基础聚合函数
基础的聚合函数有:sum()、count()、max()、min()、avg()
-
没有group by 关键字就是对整个表聚合;有group by 就是对每个组聚合。
-- 1. 分组聚合:统计男同学、女同学人数 select count(*) from student group by sex; -- 2. 表聚合:统计全班人数 select count(*) from student; -
①
count(*)等价于count(1):统计所有行,包括含有null值的行
②count(col):只会对col中非null进行统计。其他的基础聚合函数也一样的,对字段聚合处理,若存在该字段值为null,则忽略该行。【巧用这一点可以解题:1.3 变形例题】
③count(只能传入一个参数),如果要传入多个参数,可以count(distinct col1, col2),只要去重对结果没有影响就可以这样。【因为distinct本质是一个函数,将多列转成了单列】 -
聚合函数内:
- 可以
搭配 if()、case when ... then else end、isnull()这种 单列函数 使用。但是 聚合函数 内不可搭配 聚合函数 。对于聚合函数内搭配单列函数,是这样执行的:先对每组数据内的所有行都执行单列函数,再对每组数据进行聚合 【例题:SQL34 统计复旦用户8月练题情况】
- 可以搭配
distinct关键字去重–>count(distinct col)【例题:SQL22 统计每个学校的答过题的用户的平均答题数】
- 可以
-
聚合函数内使用struct集合数据类型,是对其第一个列操作。
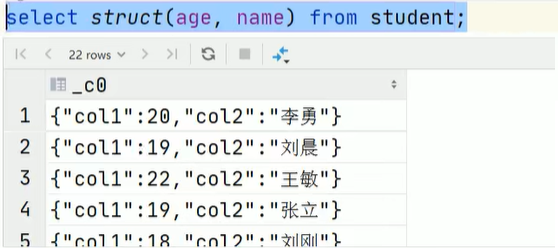
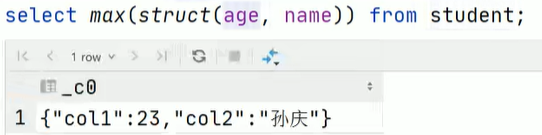
因此,可以实现:分别查找男生女生年龄最大的人的姓名select sex, max(struct(age, name)).col1 as age, max(struct(age, name)).col2 as name from student group by sex;
2.2 高级聚合函数
- collect_list() :收集并形成list集合,结果不去重
- collect_set():收集并形成set集合,结果去重
- 案例:
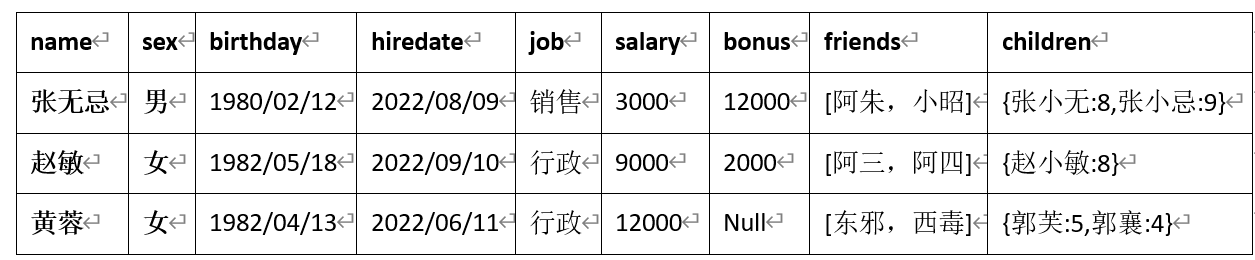
select sex, collect_list(job) as job from employee group by sex -- 结果: sex job 男 ["销售"] 女 ["行政","行政"]select sex, collect_set(job) as job from employee group by sex -- 结果: sex job 男 ["销售"] 女 ["行政"]
2.2 增强聚合函数
2.2.1 grouping sets()
https://blog.csdn.net/qq_43546676/article/details/128291169
2.2.2 with cube() 与 with rollup()
https://blog.csdn.net/qq_43546676/article/details/128291559
3 表生成函数 (UDTF - 一进多出)
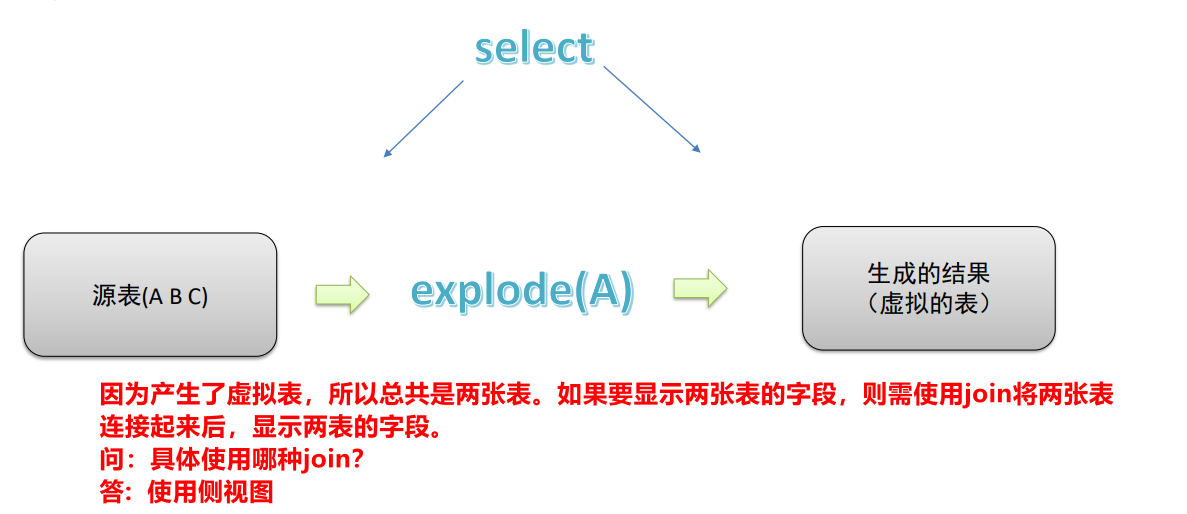
UDTF与侧视图是一对好基友,往往一起使用。因为,在select后面使用UDTF(a.col_name)函数时,不可以在select后面再出现表字段,只有结合侧视图使用时才能出现表字段。【原因以及例子可见3.1节】。
3.1 explode()炸裂函数
Lateral View explode 源码解析
如果开启了谓词下推,则会先过滤再裂开:Hive Lateral View Explode with where clause - what runs first
-
explode()函数的参数只能是
array或map类型
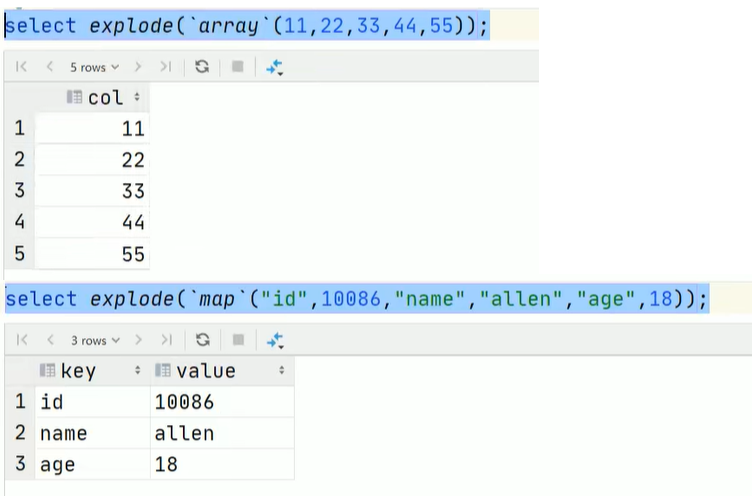
-
由于explode()函数属于UDTF,所以在select后面使用explode(a.col_name)函数时,不可以在select后面再出现表字段,只有结合侧视图使用时才能出现表字段。比如:
① 有文件The_NBA_Championship.txt:Chicago Bulls,1991|1992|1993|1996|1997|1998 San Antonio Spurs,1999|2003|2005|2007|2014 Golden State Warriors,1947|1956|1975|2015 Boston Celtics,1957|1959|1960|1961|1962|1963|1964|1965|1966|1968|1969|1974|1976|1981|1984|1986|2008 L.A. Lakers,1949|1950|1952|1953|1954|1972|1980|1982|1985|1987|1988|2000|2001|2002|2009|2010 Miami Heat,2006|2012|2013 Philadelphia 76ers,1955|1967|1983 Detroit Pistons,1989|1990|2004 Houston Rockets,1994|1995 New York Knicks,1970|1973② 需求:使用Hive建表映射成功数据,对数据拆分,要求拆分之后数据如下所示:

③ 建表加载数据:--step1:建表 create table the_nba_championship( team_name string, champion_year array<string> ) row format delimited fields terminated by ',' collection items terminated by '|'; --step2:加载数据文件到表中 load data local inpath '/root/hivedata/The_NBA_Championship.txt' into table the_nba_championship; --step3:验证 select * from the_nba_championship;④ 实现需求 【问题的关键点】
-- 错误:因为在select后面使用explode对the_nba_championship表的列进行了炸裂,所以在select后面不能再出现该表的字段。所以team_name不应该出现 select team_name,explode(champion_year) from the_nba_championship; -- 正确:使用侧视图 select a.team_name,b.year from the_nba_championship a lateral view explode(champion_year) b as year order by b.year desc;- 为什么上面的是错的?
- 因为不能直接显示两张表的字段。
-
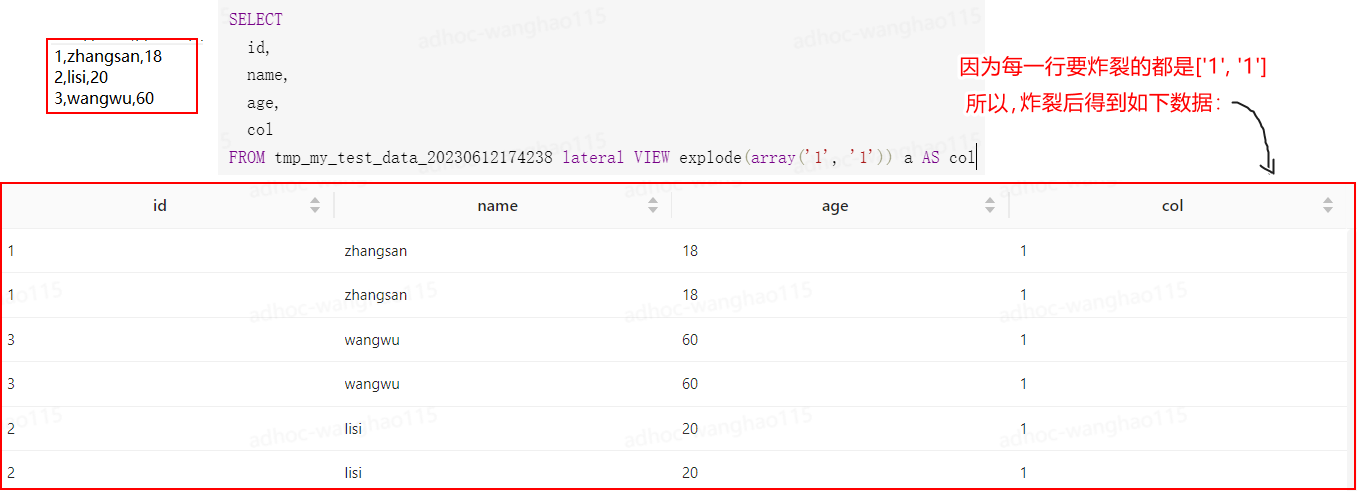
炸裂的过程:数据是一行一行炸裂的,炸裂当前行时,才会看当前行有什么要炸裂。几个例子:
- 例子一:
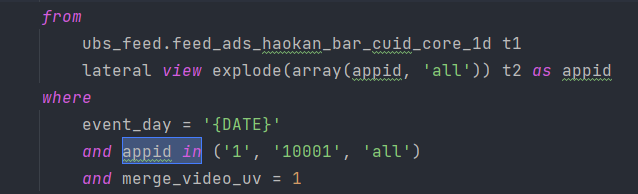
- 例子二:分维度 与 总维度
select appid, sum(click_cnt) from feed_dwd_pub_log_hi lateral view explode(array(appid, 'all')) as appid where event_day = 'XXXX' and event_action = 'click' and is_spam = 0 group by appid - 例子三:当这一行
r_detail没有数据,当前行待炸裂的是[{'1', '1'}],炸裂后还是一行;当r_detail有数据时,当前行待炸裂的是[{...}, {...}],炸裂后就是多个行。select ...... from hpb_dwd_log_di lateral view explode(case when size(r_detail)=0 or r_detail is null then array(map('1','1')) else r_detail end)B as item
- 例子一:
-
可以多次炸裂,写炸裂的视图可以取相同的名字
-- 多次炸裂,视图名字不同 select .... from ubs_feed.feed_ads_haokan_bar_cuid_core_1d A lateral view explode(array('all', appid)) B as appid lateral view explode(array('all', os)) C as os -- 多次炸裂,视图名字相同 select .... from ubs_feed.feed_ads_haokan_bar_cuid_core_1d A lateral view explode(array('all', appid)) B as appid lateral view explode(array('all', os)) B as os
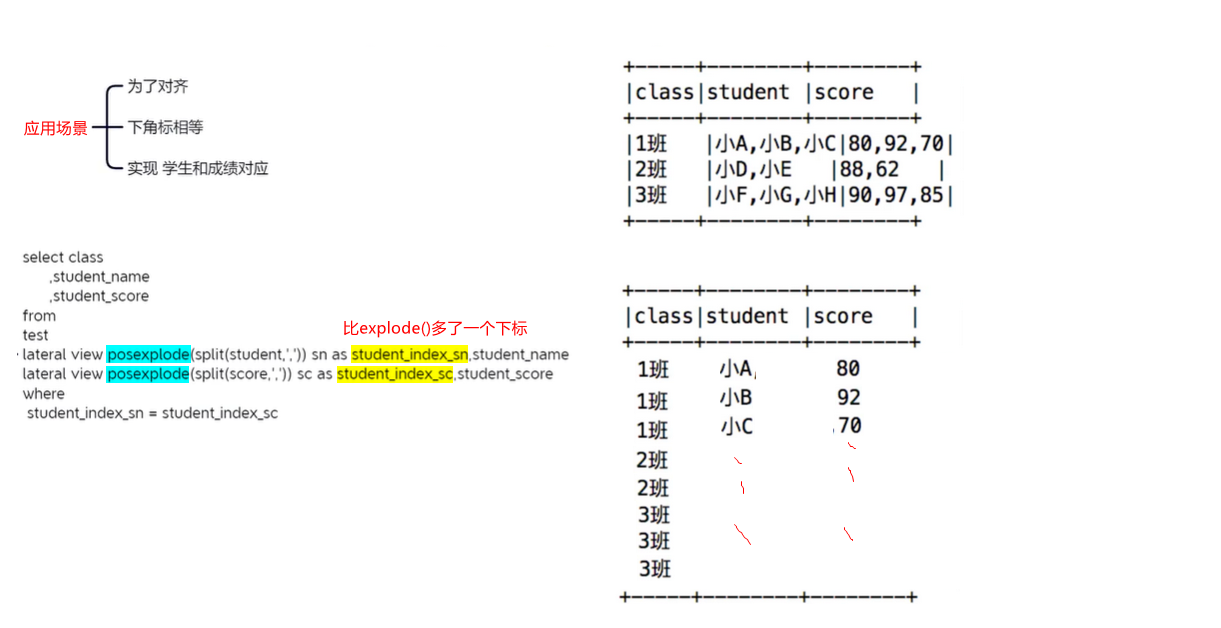
3.2 posexplode()炸裂函数
3.2 parse_url_tuple()函数
https://blog.csdn.net/qq_43546676/article/details/128319768
3.3 json_tuple()函数
https://blog.csdn.net/qq_43546676/article/details/128331146
3.4 侧视图(lateral view)
UDFT与侧视图是好基友,一般只要使用UDTF,就会固定搭配lateral view使用。
-
原理:将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表。这样就避免了UDTF的使用限制问题。
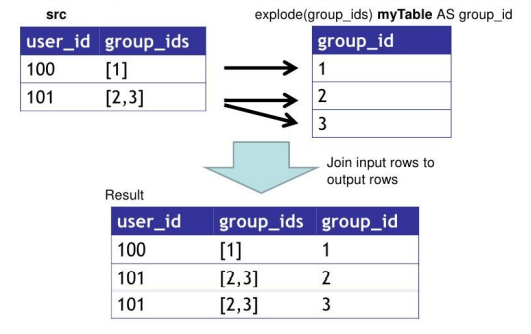
-
语法:
select …… from tabelA lateral view UDTF函数(列名) 拼接后的表别名 as 列别名;- 拼接后的表别名:因为UDTF函数炸裂之后生成的是一个视图,与原表拼接后需要为新表取名
- 列别名:因为传入的列被炸裂了,炸裂的列没有取代了原本的列,但需要重新命名
- 如果要炸开多个列:
- 方式一:可以同时炸裂多个列:比如 col1,col2,…都是array或map类型
select …… from tabelA lateral view UDTF函数(col1, col2,...) 拼接后的表别名 as col1列的别名, col2列的别名,...;- 方式二:一个炸裂列对应一个侧视图:比如 col1,col2,…都是array或map类型
select …… from tabelA lateral view UDTF函数(col1) 拼接后的表别名 as col1列的别名 lateral view UDTF函数(col2) 拼接后的表别名 as col2列的别名;
-
例子:
--根据年份倒序排序 select a.team_name ,b.year from the_nba_championship a lateral view explode(champion_year) b as year order by b.year desc; --统计每个球队获取总冠军的次数 并且根据倒序排序 select a.team_name ,count(*) as nums from the_nba_championship a lateral view explode(champion_year) b as year group by a.team_name order by nums desc;
------- 3个注意点
-
在select后面使用UDTF函数,则在select后不可以查询原表的列名。比如:
-- 错误:因为使用explode对the_nba_championship表的列进行了炸裂,所以不能再出现该表的字段。所以team_name不应该出现 select team_name,explode(champion_year) from the_nba_championship; -- 正确:在select后面使用UDTF函数,则在select后不可以查询原表的列名 select explode(champion_year) as y from the_nba_championship; -- 正确:使用侧视图 select a.team_name,b.year from the_nba_championship a lateral view explode(champion_year) b as year order by b.year desc; -
在from后面使用UDTF函数与侧视图,则在select后可以查询原表的列名,比如:
UDTF函数一旦侧视图结合,放在from后,那么就变为了视图-- 例子1: select b.y as y from the_nba_championship a lateral view explode(champion_year) b as y; -- 例子2: select b.host as host, b.path as path from tb_url a lateral view parse_url_tuple(tb_url.url, "host", "path") b as (host, path); -
UDTF函数有个坑:
- 如果每一行经过UDTF函数后都为null,那么最终返回0行数据,并不会保存原始数据。如果只是存在某行或多行经过UDTF函数后为null,则不会这样。
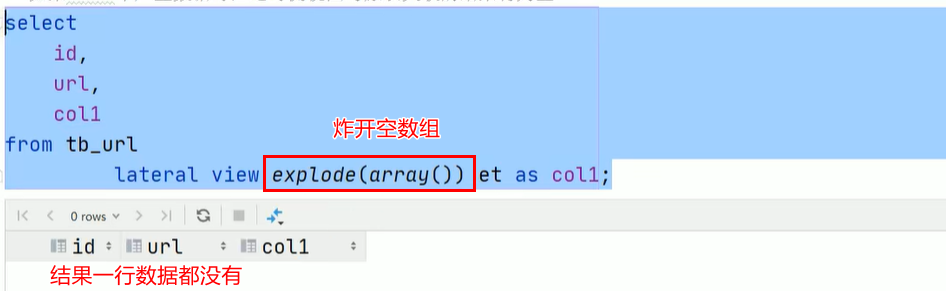
- 如果想要避免这种情况,在每一行经过UDTF函数炸开后都为null的情况下,返回原始数据+null,只需要在
lateral view后面加上outer关键字即可:
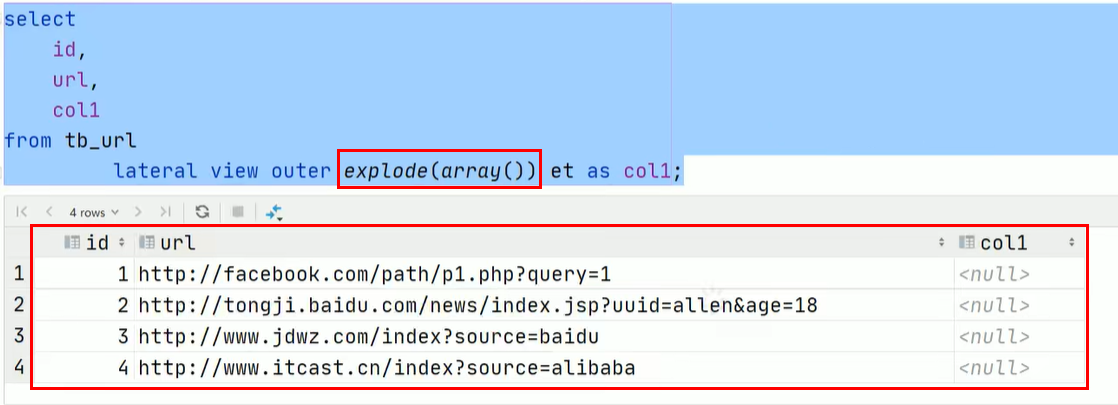
- 如果每一行经过UDTF函数后都为null,那么最终返回0行数据,并不会保存原始数据。如果只是存在某行或多行经过UDTF函数后为null,则不会这样。
4. 自定义函数 (不推荐)
自定义函数要使用java类基础UDF类,打包后导入hive,再运行。不常用。详细信息见:https://www.bilibili.com/video/BV1L5411u7ae?p=98&vd_source=5534adbd427e3b01c725714cd93961af

















 2585
2585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











