







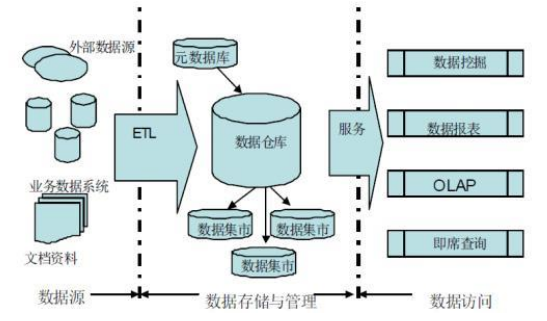
1. 应用场景
我们知道Hive在实际工作中主要用于构建离线数据仓库,定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用。
而拉链表就是来解决其中的 数据同步 问题。
现在有如下需求:
-
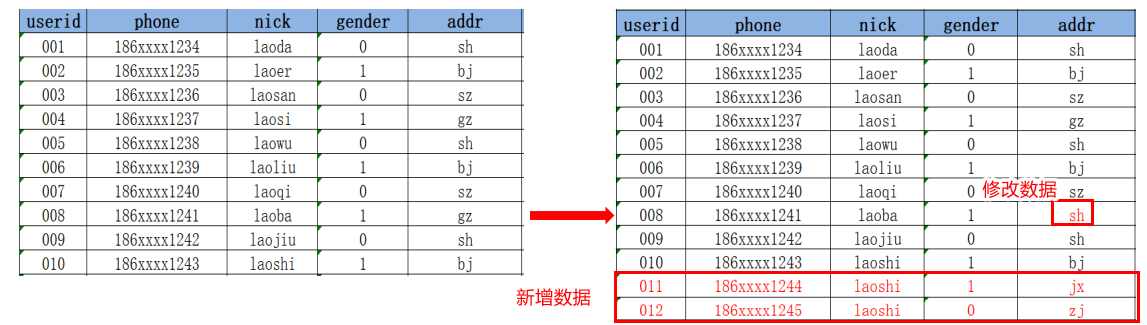
需求:每天需要从MySQL中同步某用户的信息到数据仓库中,那么在同步mysql数据时数据变化在于
① 增加新数据:新增用户
② 删除数据:用户注销
③ 修改数据:修改昵称,修改家庭住址等
-
解决方法:
- 对于 增加数据 ,直接 增加数据。
- 对于 删除数据,不会真正删除数据,而是 修改其结束时间,表示已删除。也就是说删除数据本质上是修改数据。
- 而对于 修改数据 不好处理:
- 直接用新数据覆盖旧数据,那么会丢失修改之前的信息,即丢失历史信息。
- 每次同步数据时若数据改变,则创建一张新表来保存数据,这样旧表就还在。但是这样虽然保留了历史信息,每次数据改变就新增一张表,最后会导致数据非常冗余。
- 因此,① 既要增加修改后的行数据;② 同时又要对修改之前的行数据,修改其结束时间,表示已删除。
-
总的来说:① 对于 增加数据 、 删除数据、 修改数据 都需要添加到表中;② 另外,对于 删除数据、 修改数据还需要修改 结束时间,以表示 旧数据已删除。
2. 拉链表概述
- 作用:专门用于解决在数据仓库中如何存储发生变化的数据。
- 具体做法:拉链表相对于MySQL业务数据库中多了 开始时间 和 结束时间间 两个字段,从而做到 ① 数据没有冗余存储 ② 历史状态依然清晰可见
注意:结束时间为9999-12-31的行,表示该行正在使用;否则表示该行数据被修改过。
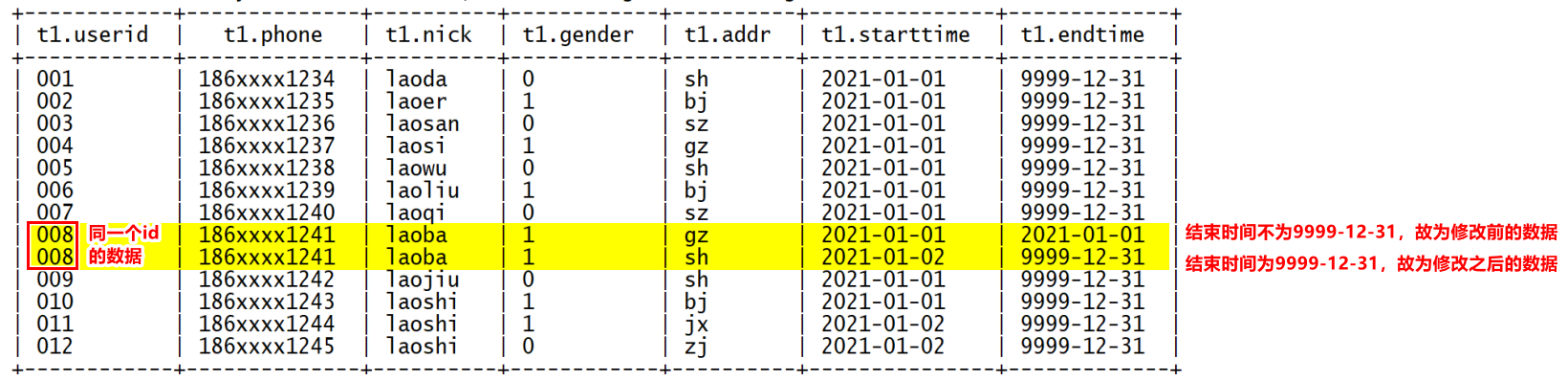
- 在拉链表中维护着两种数据:
endtime == "9999-12.31":表示 当前正在生效的数据endtime < "9999-12.31":表示 历史数据
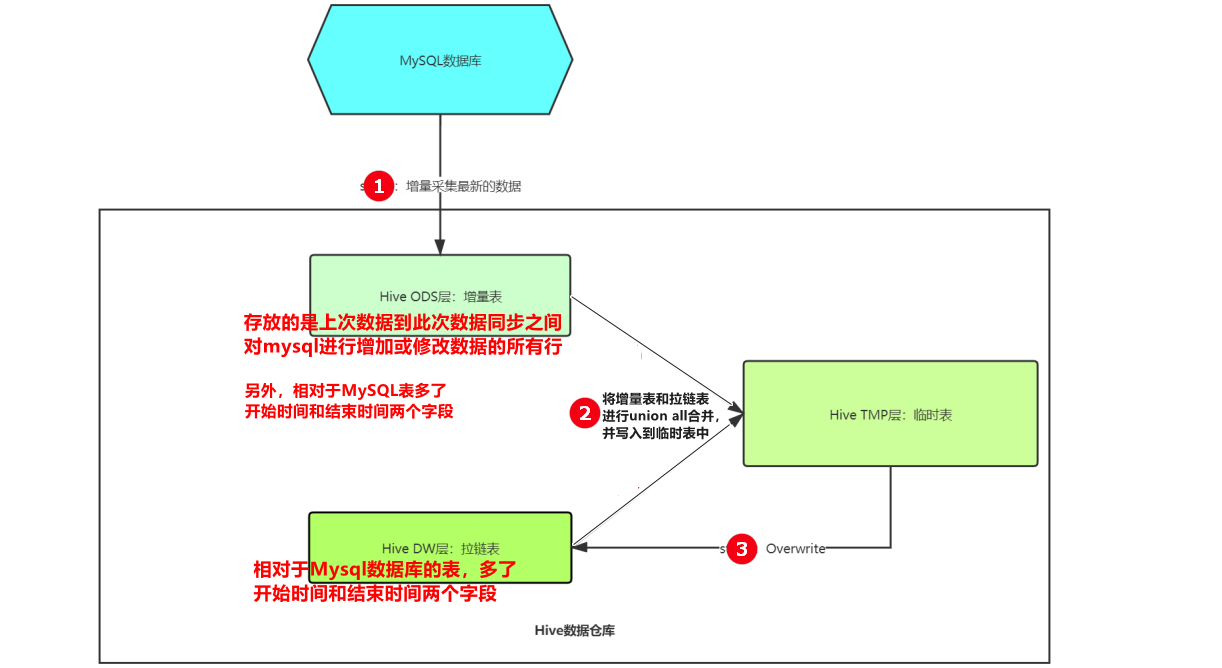
3. 实现过程
-
从MySQL业务日志中拉取从上次数据同步到此次数据同步之间的所有数据,并覆盖写入 增量表 中。

-
拉链表对 修改 和 删除 的数据做修改,再与增量表进行
union all合并(因为增量表中的数据都需要添加到拉链表中),并覆盖写入临时表中。 -
将临时表中的数据覆盖的写入到拉链表。
4. 例子
-
假设从MySQL拉去到的数据已经放入到增量表
ods_zipper_update中,其数据如下:

-
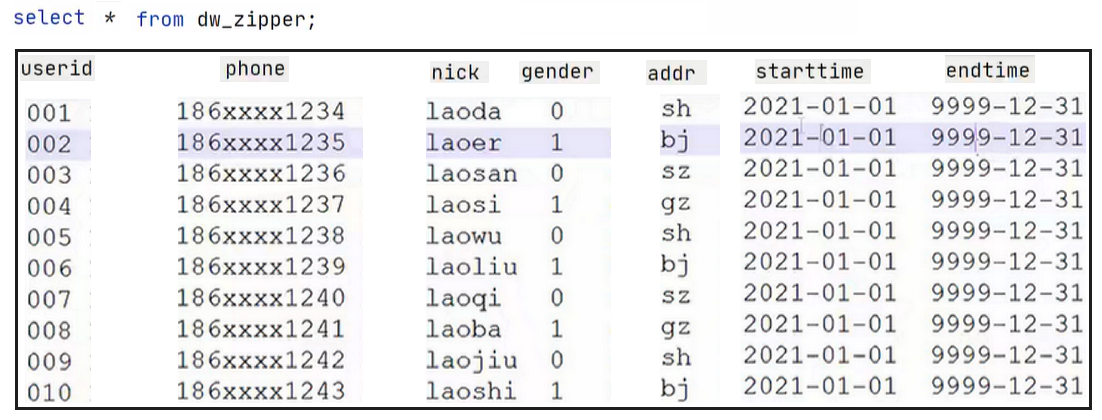
假设此时存放上一次数据的拉链表
dw_zipper为:
-
将增量表和拉链表进行
union all合并后写入临时表tmp_zipper中:insert overwrite table tmp_zipper select userid, phone, nick, gender, addr, starttime, endtime from ods_zipper_update union all select a.userid, a.phone, a.nick, a.gender, a.addr, a.starttime, -- 如果此次这个id的数据没有更新 或者 此次该id的数据更新了但是是历史信息 -- 则保留原来行, -- 否则就改为新数据的开始时间-1 if(b.userid=null or a.endtime < "9999-12-31", a.endtime, date_sub(b.starttime, 1)) as endtime from dw_zipper a left join ods_zipper_update b on a.userid=b.userid;- 解释:

- 两个点:
left join和union all
- 解释:
-
将临时表中的数据写入拉链表中。
















 1507
1507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











