






神经网络
一、非线性假设
对于之前的线性回归等,一般特征数比较有限,可能只有几个,但是对于神经网络来说,特征数可能有上百万个。比如一副50 * 50的RGB图像,它的像素点有50 * 50 * 3 个,这些都是特征值。因此用线性回归、Logistic回归并不能很好的解决这样的问题,因为特征太多了。
因此采用神经网络,可以很好的应对这些特征很多的特征空间。
二、神经元
以下是一个神经元的基本结构:

在这幅图中,神经元带有的sigmoid函数称为“激活函数”(指代非线性函数)。
这里
Θ
\Theta
Θ可以称为参数或权重(有时候用w表示)。
也可以在输入多加一个
x
0
x_0
x0,可以称为“偏置单元”。
三、神经网络结构
由一组神经元组成的就是基本的神经网络结构:

Layer1称为“输入层”,Layer2称为“隐藏层”(可以理解为,中间既不是输入也不是输出,我们也看不见,就是隐藏在中间的层),Layer3是“输出层”。
其中例如
a
1
(
2
)
{a}_{1}^{(2)}
a1(2)称为 “激活项” ,激活项就是由一个具体的神经元计算并输出的值。

g()就是激活函数,也可以说是logistic函数(sigmoid函数)。其中x0是偏置单元,图中未画出。
如果第j层有
s
j
s_j
sj个神经元,第j+1层有
s
j
+
1
s_{j+1}
sj+1个神经元,则
Θ
j
\Theta^j
Θj的shape将会是
s
j
+
1
∗
(
s
j
+
1
)
{s}_{j+1} * (s_{j}+1)
sj+1∗(sj+1)
Θ
j
\Theta^j
Θj是权重矩阵来控制从第j层到第j+1层的映射。
四、前向传播
前向传播可以用向量计算来实现,把所有输入单元的输入看作一个向量,再乘上权重矩阵得到第一层输出,再传给第二层计算…

前向传播的过程依赖于网络结构,上面的例子都是全连接,也就是每一个输入单元都与下一层的神经元相连接。
五、如何利用神经网络计算复杂的非线性函数
想要利用下面三个函数来实现异或

1)先实现和

2)再实现第二个函数

3)第三层输出

因此,想要实现更加复杂的非线性函数,都是得到前面层的输出再输入到下一层。
六、如何利用神经网络解决多分类问题
类似于Logistic回归的多分类问题,采用一对多的思想,对于4个类,就训练4个分类器。

得到了4个输出,4个输出组成一个向量。例如:
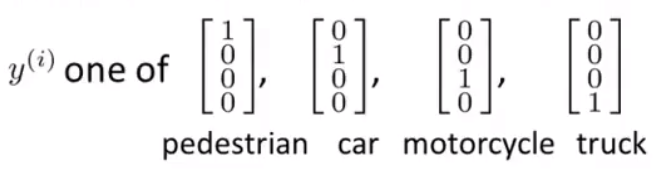
神经网络的学习过程:对神经网络输入
x
(
i
)
x^{(i)}
x(i),可以得到输出
h
Θ
(
x
(
i
)
)
h_{\Theta}(x^{(i)})
hΘ(x(i)),网络不断学习使得
h
Θ
(
x
(
i
)
)
h_{\Theta}(x^{(i)})
hΘ(x(i))约等于
y
(
i
)
y^{(i)}
y(i)
七、代价函数
首先是Logistic回归的代价函数:
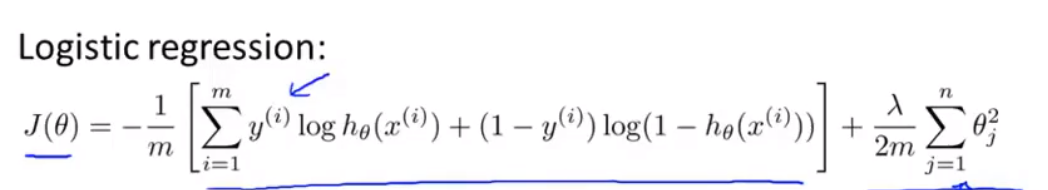 注意这里没有对
Θ
0
\Theta_{0}
Θ0的惩罚,这是约定俗成。
注意这里没有对
Θ
0
\Theta_{0}
Θ0的惩罚,这是约定俗成。
然后是神经网络的代价函数:

表示有K个类别。
注意里面有k从1~K的求和,这是把k个输出的代价都加起来,得到总的代价。后面正则化项是对权重矩阵中i,j对应的位置进行求和。
八、代价函数最小化
我们已经知道了代价函数J(
Θ
\Theta
Θ),目标是求出
Θ
\Theta
Θ来最小化J(
Θ
\Theta
Θ)。
因此我们需要计算J(
Θ
\Theta
Θ)和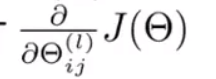
前向传播可以计算出每层神经元的激活值,然后就需要反向传播来最小化损失函数。

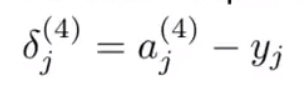
δ
j
(
4
)
\delta_{j}^{(4)}
δj(4)指的是第j层的第4个神经元的误差。
则相应的,把第4层每个误差放一起看作一个向量:
δ
(
4
)
\delta^{(4)}
δ(4) =
a
(
4
)
a^{(4)}
a(4) - y
同样的计算第2、3层误差:
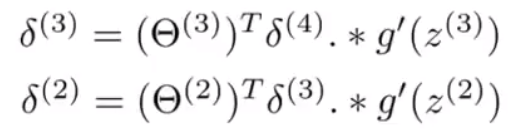
可以发现第3层误差是由第4层计算出来的,第2层的是由第3层计算出来的,所以是反向传播计算误差的过程。(第1层是输入,所以没有误差)
有了误差就可以计算偏导项(用来最小化):
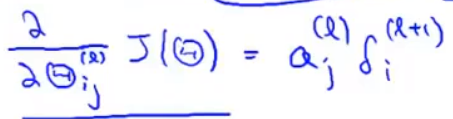
由于一般高级优化函数中的参数要求向量形式,而我们在前传和后传计算是用矩阵计算,这里就需要矩阵和向量的相互转换。只需要提取矩阵中全部元素放入向量中即可,反过来,提取向量中i~j位置的元素reshape成矩阵。
九、梯度检验
反向传播算法可能会出现一些问题,我们需要进行梯度检验来确保反向传播算法的正确。
1、估计偏导数:
对于取值实数
Θ
\Theta
Θ,可以求出偏导数
∂
∂
Θ
J
(
Θ
)
\frac{\partial}{\partial {\Theta}}J(\Theta)
∂Θ∂J(Θ)。那么现在取
Θ
\Theta
Θ左右两点,
Θ
−
ϵ
\Theta - \epsilon
Θ−ϵ、
Θ
+
ϵ
\Theta + \epsilon
Θ+ϵ来估计偏导数。

可以得到:
∂
∂
Θ
J
(
Θ
)
≈
J
(
Θ
+
ϵ
)
−
J
(
Θ
−
ϵ
)
2
ϵ
\frac{\partial}{\partial {\Theta}}J(\Theta) ≈ \frac{J({\Theta + \epsilon}) - J(\Theta - \epsilon)}{2{ \epsilon}}
∂Θ∂J(Θ)≈2ϵJ(Θ+ϵ)−J(Θ−ϵ)
那么从实数推广到n维向量:
需要for循环 1~n

2、验证导数
用我们上述计算出来的偏导数,和反向传播算法计算得到的导数相比较,看看是否近似相等,来验证反向传播是否正确。
反向传播的导数Dvec=(两层之间的权重 * 后一层的
δ
\delta
δ)再求和 (Dvec就是把导数矩阵展开成向量)
3、关闭梯度检验
当确定反向传播正确后,应该关闭梯度检验,也就是不要用估计偏导数,因为这个计算导数的过程太复杂了,反向传播计算导数比较高性能。因此之后的导数都用反向传播计算即可。
十、随机初始化
对于梯度下降或者其他一些高级优化算法,需要对
Θ
\Theta
Θ做初始化赋值。
对于神经网络来说,
Θ
\Theta
Θ的初值不能全为0,因为这样相邻两层就没有变化了。不管迭代多少轮,网络权重都不会更新变化。因此需要采用随机初始化的思想。
可以随机初始化
Θ
\Theta
Θ为介于【-e,e】的,分布在0附近的值。
十一、总结 神经网络实现过程
1、选择网络架构
要明确特征维数和种类数量。
【注】若是多分类问题,有5类。y ∈ {1,2,3,4,5},不要写成y=1、y=2这样,要用向量形式y1=[1,0,0,0,0]、y2=[0,1,0,0,0]。
2、训练网络
1)随机初始化权重
2)执行前向传播算法,对于输入的
x
i
x^i
xi,有对应输出
h
Θ
(
x
(
i
)
)
h_{\Theta}(x^{(i)})
hΘ(x(i))
3)计算代价函数J(
Θ
\Theta
Θ)
4)执行反向传播算法,计算偏导项
∂
∂
Θ
J
(
Θ
)
\frac{\partial}{\partial {\Theta}}J(\Theta)
∂Θ∂J(Θ)
对于第一次实现反向传播算法的话,可以对m个样本进行for循环:对每一个样本i进行一次前传和后传。熟悉以后,可以对m个样本向量化,这样就不需要for循环。
5)使用梯度检验。上一步对训练集执行了一次反向传播,这里用梯度检验确定是能够计算出正确的偏导,就可以停止梯度检验,然后再不停迭代反向传播直到收敛。
6)使用梯度下降或者其他优化算法,与反向传播算法相结合,来最小化
J
(
Θ
)
J(\Theta)
J(Θ)。最终目的就是希望网络的输出能够尽可能接近于真实值。















 512
512











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









