






import h5py
"""读取数据"""
path_dir="./archive/"
with h5py.File(path_dir+"full_dataset_vectors.h5", "r") as data:
X_train = data["X_train"][:]
y_train = data["y_train"][:]
X_test = data["X_test"][:]
y_test = data["y_test"][:]
# print('X_train : Shape:', X_train.shape, ' Type:', type(X_train))
# print('Y_train : Shape:',y_train.shape, ' Type:', type(y_train))
# print('X_test : Shape:', X_test.shape, ' Type:', type(X_test))
# print('Y_test : Shape:', y_test.shape, ' Type:', type(y_test))
"""重塑数据——3D空间中的MNIST 图像大小为 16x16x16"""
import numpy as np
import torch
def Transform_images_dataset (Data):
#Binarize_images_dataset
Th=0.2
Upper=1
Lower=0
Data = np.where(Data>Th, Upper, Lower)
#Data_transform_channels
Data = Data.reshape(Data.shape[0], 1, 16,16,16)
"""使用NumPy库中的stack()函数将数组Data沿着最后一个维度复制3次,
并将它们沿着新的最后一个维度堆叠在一起,以创建一个新的3维数组"""
Data = np.stack((Data,) * 3, axis=-1)
return(torch.as_tensor(Data))
# 初始shape为(10000, 4096),转换之后变成torch.Size([10000, 1, 16, 16, 16, 3])
X_train = Transform_images_dataset(X_train)
# 初始shape为(2000, 4096),转换之后变成torch.Size([2000, 1, 16, 16, 16, 3])
X_test = Transform_images_dataset(X_test)
def One_hit_data (target):
# Convert To Torch Tensor
Target_tensor = torch.as_tensor(target)
# Create One-Hot Encodings Of Labels
"""使用PyTorch中的函数torch.nn.functional.one_hot()
将Target_tensor转换为one-hot编码形式。其中,num_classes=10
表示生成的one-hot向量维度为10,即Target_tensor中包含的类别数量为10"""
One_hot = torch.nn.functional.one_hot(Target_tensor, num_classes=10)
return(One_hot)
# y_train.shape——>torch.Size([10000, 10])
y_train= One_hit_data (y_train)
# y_test.shape——>torch.Size([2000, 10])
y_test= One_hit_data (y_test)
# print('X_train : Shape:', X_train.shape, ' Type:', type(X_train))
# print('Y_train : Shape:', Y_train.shape, ' Type:', type(Y_train))
# print('X_test : Shape:', X_test.shape, ' Type:', type(X_test))
# print('Y_test : Shape:', Y_test.shape, ' Type:', type(Y_test))
import pandas as pd
import numpy as np
from tqdm.auto import tqdm
import os
import matplotlib.pyplot as plt
import torch
from torch.autograd import variable
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import *
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import confusion_matrix
import seaborn as sns
"""创建用于图像分类的三维卷积神经网络模型"""
class CNN_classification_model(nn.Module):
# 使用的是mnist数据集
def __init__(self,num_classes=10):
super(CNN_classification_model, self).__init__()
self.Model = nn.Sequential(
# Conv Layer 1
nn.Conv3d(3, 32, kernel_size=(3, 3, 3), padding=0),
nn.ReLU(),
nn.MaxPool3d((2, 2, 2)),
# Conv Layer 2
nn.Conv3d(32, 64, kernel_size=(3, 3, 3), padding=0),
nn.ReLU(),
nn.MaxPool3d((2, 2, 2)),
# Flatten
nn.Flatten(),
# Linear 1
nn.Linear(2 ** 3 * 64, 128),
# Relu
nn.ReLU(),
# BatchNorm1d
nn.BatchNorm1d(128),
# Dropout
nn.Dropout(p=0.15),
# Linear 2
nn.Linear(128, num_classes)
)
def forward(Self, X):
# Set 1
Out = Self.Model(X)
return Out
"""定义准确率函数,用于求准确率"""
def AccuracyFUNCTION (Predicted, Targets):
C=0
for i in range(len(Targets)):
if (Predicted[i] == Targets[i]):
C+=1
Accuracy = C / float(len(Targets))
return(Accuracy)
"""训练模型"""
batch_size = 100
# Pytorch train and test sets
train = torch.utils.data.TensorDataset(X_train.float(),y_train.long())
test = torch.utils.data.TensorDataset(X_test.float(),y_test.long())
# data loader with pytorch
train_loader = torch.utils.data.DataLoader(train, batch_size = batch_size, shuffle = False)
test_loader = torch.utils.data.DataLoader(test, batch_size = batch_size, shuffle = False)
# we have 10 classes
num_classes = 10
# The number of epochs (here the number of iterations is = 5000 / we have 50 epochs a batch size is 100 / 50*100=5000)
num_epochs = 5
# 3D model
model = CNN_classification_model()
#You can use the GPU by typing: model.cuda()
# print(model)
# Loss function : Cross Entropy
error = nn.CrossEntropyLoss()
# Learning rate : learning_r = 0.01
learning_r = 0.01
# SGD optimizer
optimizer = torch.optim.SGD(model.parameters(), lr=learning_r)
# ***********************************************************************training***********************************
itr = 0
loss_list = []
accuracy_list = []
for epoch in range(num_epochs):
# tqdm则是一个Python的进度条库,用于显示循环迭代的进度。
for i, (images, labels) in tqdm(enumerate(train_loader)):
# 将images(100, 1, 16, 16, 16, 3)重塑为(100, 3, 16, 16, 16)
train = torch.tensor(images.view(100, 3, 16, 16, 16))
labels = torch.tensor(labels)
# zero_grad : Clear gradients
optimizer.zero_grad()
# Forward propagation / CNN_classification_model
outputs = model(train)
# Calculate loss value / using cross entropy function
"""将一个多类别的标签张量(tensor)转换为只有一个标签的张量,沿着最后
一个维度找到每个样本中具有最高值的索引,并将其作为该样本的标签."""
labels = labels.argmax(-1)
loss = error(outputs, labels)
loss.backward()
# Update parameters using SGD optimizer
optimizer.step()
# calculate the accuracy using test data
itr += 1
if itr % 100 == 0:
# Prepare a list of correct results and a list of anticipated results.
listLabels = []
listpredicted = []
# test_loader
for images, labels in test_loader:
test = torch.tensor(images.view(100, 3, 16, 16, 16))
# Forward propagation
outputs = model(test)
# print(dir(outputs))
# Get predictions from the maximum value
# torch.max(outputs.data, 1)返回每行输出中最大的元素值和每行最大元素所在的列索引
# 列索引作为最终的预测结果 predicted
predicted = torch.max(outputs.data, 1)[1]
# used to convert the output to binary variables
predicted = One_hit_data(predicted)
# Create a list of predicted data
predlist = []
for i in range(len(predicted)):
# print(predicted[i])
# 用于找到张量 predicted[i] 中最大值所在的索引位置,并返回该索引
p = int(torch.argmax(predicted[i]))
# print(p)
predlist.append(p)
listLabels += (labels.argmax(-1).tolist())
listpredicted += (predlist)
# calculate Accuracy
accuracy = AccuracyFUNCTION(listpredicted, listLabels)
# 打印这一次迭代的loss
print('Iteration: {} Loss: {} Accuracy: {}'.format(itr, loss.data, accuracy))
# store loss and accuracy. They'll be required to print the curve.
#每当迭代符合itr % 100 == 0这个条件,就把这一次的loss和accuracy存入各自的list
loss_list.append(loss.data)
accuracy_list.append(accuracy)
"""Display The Accuracy Curve"""
sns.set()
sns.set(rc={'figure.figsize': (12, 7)}, font_scale=1)
plt.plot(accuracy_list, 'b')
plt.plot(loss_list, 'r')
plt.rcParams['figure.figsize'] = (7, 4)
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.title("Training Step: Accuracy Vs Loss ")
plt.legend(['Accuracy', 'Loss'])
plt.show()
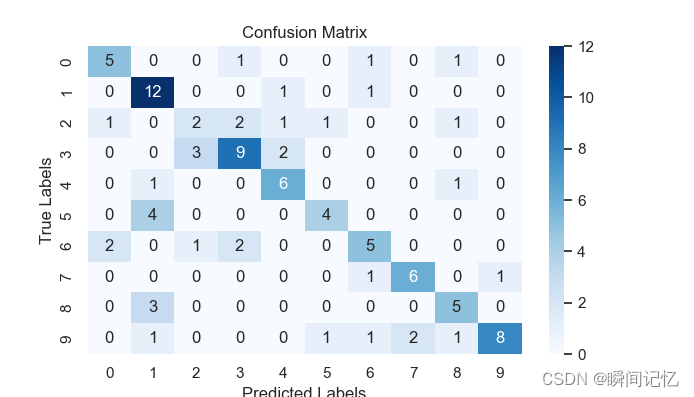
"""Display The Confusion Matrix """
predictionlist=[]
for i,(images, labels) in tqdm(enumerate(train_loader)):
# 将images(100, 1, 16, 16, 16, 3)重塑为(100, 3, 16, 16, 16)
train = torch.tensor(images.view(100, 3, 16, 16, 16))
labels = torch.tensor(labels)
outputs = model(train)
#这里是因为报错Labels1和Predictionlist的长度不一致,
#暂时没别的办法,只能先这样控制一下
if len(predictionlist)<100:
for i in range(len(outputs)):
p = int(torch.argmax(outputs[i]))
predictionlist.append(p)
Labels1=labels.argmax(-1).tolist()
Labels1= [str(X) for X in Labels1]
# print(len(Labels1))
Predictionlist= [str(X) for X in predictionlist]
# print(len(Predictionlist))
LabelsLIST = ['0','1', '2','3', '4','5', '6','7', '8','9']
Cm = confusion_matrix(Labels1, Predictionlist, labels=LabelsLIST)
ConfusionMatrixDisplay(Cm).plot()
#******************** Color Of Confusion Matrix
ax= plt.subplot()
sns.heatmap(Cm, annot=True, ax = ax, cmap=plt.cm.Blues)
#Annot=True To Annotate Cells
# Labels, Title And Ticks
ax.set_xlabel('Predicted Labels')
ax.set_ylabel('True Labels')
ax.set_title('Confusion Matrix')
ax.xaxis.set_ticklabels( ['0','1', '2','3', '4','5', '6','7', '8','9'])
ax.yaxis.set_ticklabels(['0','1', '2','3', '4','5', '6','7', '8','9'])
plt.rcParams['figure.figsize'] = (8, 7)
plt.show()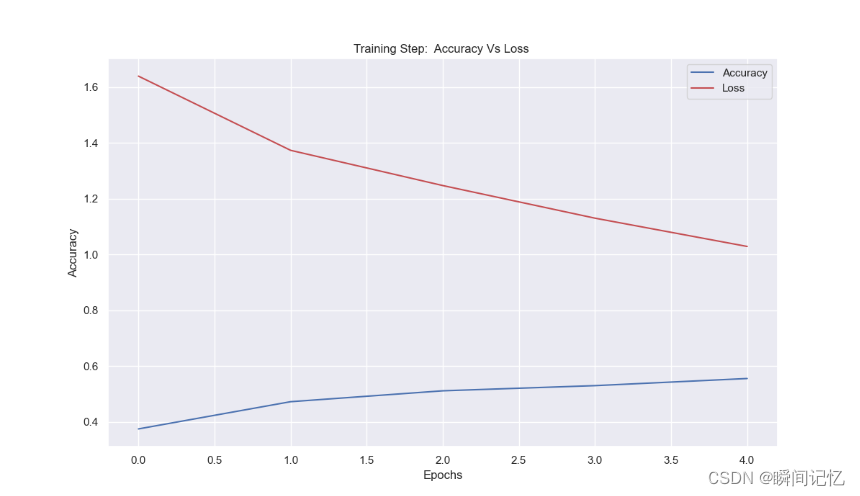















 243
243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









