









上一篇博客中简单介绍了K均值聚类算法,在本篇博客中介绍一下关于谱聚类算法,简单谈一谈自己的心得。简单介绍一下谱聚类算法
谱聚类算法建立在谱图理论基础上,与传统的聚类算法相比,它具有能在任意形状的样本空间上聚类且收敛于全局最优解的优点。该算法首先根据给定的样本数据集定义一个描述成对数据点相似度的亲合矩阵,并且计算矩阵的特征值和特征向量 , 然后选择合适 的特征向量聚类不同的数据点。谱聚类算法最初用于计算机视觉 、VLS I 设计等领域, 最近才开始用于机器学习中,并迅速成为国际上机器学习领域的研究热点。谱聚类算法建立在图论中的谱图理论基础上,其本质是将聚类问题转化为图的最优划分问题,是一种点对聚类算法,对数据聚类具有很好的应用前景。
详细了解谱聚类算法的原理需要一定的图论学和矩阵论的知识,详细的原理及介绍在这篇博客中有介绍。
核心思想
将所有数据看成一个个空间中的点,每个点之间有边连接,每条边有不同的权重(距离远的点之间的边权重较小,距离近的点之间的边权重较低),通过选择合适的分割,使得每个子图内的边权重之和尽可能大,且子图与子图间的边权重之和尽可能小,基于此标准将数据进行分类
具体介绍
举例而言,张一,张二,张三,王一,王二,王三,李一,李二,李三是同一学校的学生,张一、二、三相互认识,王一、二、三相互认知,李一、二、三相互认识,张一、王一、李一相互认识,其余人互不认识,理论上,通过关系网,他们之间都有直接或间接的关系,如下图
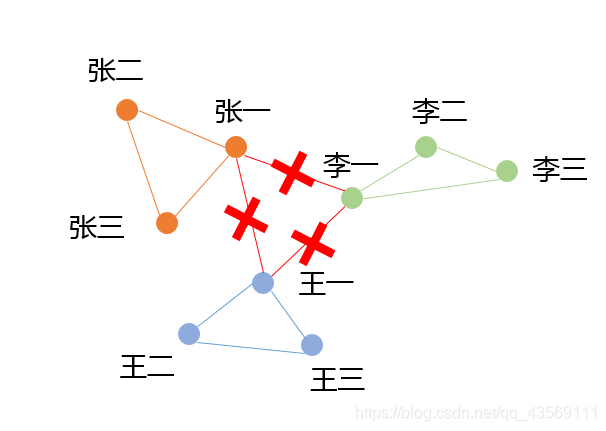
切断王一、张一、李一的联系,就将其分为了三类,谱聚类的原理大致如此,只是没有那么简单而已
图的定义
一般来说,我们用点与边来定义一个图,记点的集合为V,边的集合为E,则我们称G(V,E)是一个图,V就是我们数据中的一行行数据(没有标签等),即
共有n条数据,每条数据有m个属性。紧接着我们引入权重与度的定义,记是点
到点
边上的权重,这里我们是无向图,所以有
紧接着我们引入度的概念,点的度
是所有与之相连的边的权重之和,即
度矩阵与邻接矩阵
由上面的定义我们可以得到一个n*n的度矩阵D和邻接矩阵W
相似矩阵
以上我们只给出了权重的定义,但是如何定量的描述权重,是谱聚类算法中的一个核心,定量刻画权重的方法有很多,比如ϵ-邻近法,K邻近法和全连接法,最常用的还是全连接法,全连接法有可以细分成很多种,这里只阐述最常用的一种——高斯核函数RBF,所以对权重有如下定量描述
其中与
是数据点,
是需要给定的参数(不同的值为对最后的聚类效果有影响)
用此种方法得到的相似矩阵与邻接矩阵一样。
值得注意的是:引入相似矩阵(样本点距离度量的相似矩阵 )的目的是为了得到邻接矩阵,不同的方法得到的邻接矩阵是不一样的,所以一般是需要给定相似矩阵的
拉普拉斯矩阵
基于上述的度矩阵和邻接矩阵我们可以得到一个新的矩阵——拉普拉斯矩阵(目的是将数据进行降维处理)
由于D与W均是对称矩阵,所以拉普拉斯矩阵有一些很好的性质
- L是一个对称矩阵
- L的所有特征值均是实数
- L是一个半正定矩阵,所以特征值均大于0,且最小特征值为
具体的证明不在赘述,有兴趣的可以看看
切图聚类
切图是谱聚类算法的核心,切图的方法有很多,但最常用的还是Ncut切图,因为原理比较复杂,这里就不在说明了,感兴趣的可以自行查找,切图的目的是为了分类,所以需要进行以下操作。
1、对拉普拉斯矩阵进行标准化
值得注意的是:是指对角线上的元素进行运算(因为其余均为0元素)
2、计算标准化后的拉普拉斯矩阵的特征值,对数据进行降维处理
选取最小的k个特征值对于的特征向量,将其放入同一个矩阵中,组成一个n*k维的矩阵F(因为每一个特征向量都是一个n维的列向量)
3、利用K均值聚类对矩阵F进行聚类处理
矩阵F的每一行对应一条数据,每条数据有k个属性(从n个属性缩减到k个属性,这就是一种降维处理),然后可以利用K均值聚类算法进行聚类处理。(这里降维后的维度可以不一定是k,也可以是k1,即可以任意指定一个维度,并不需要与聚类后的维度一致,但是为了方便起见,我们一般都让其保持一致)
到这里基本上谱聚类算法的主要内容已经阐述完毕,接下来总结一下算法思路
算法流程
- 输入相似矩阵S,高斯核函数的参数
,以及所分类数k
- 计算度矩阵D和邻接矩阵W
- 计算拉普拉斯矩阵L
- 标准化矩阵L,求最小k个特征值对应的特征向量组成的矩阵
- 基于K均值聚类进行聚类
代码实现
"""
谱聚类算法
"""
# 读取数据
from numpy.linalg import *
import numpy as np
import pandas as pd
from sklearn.cluster import SpectralClustering, KMeans
import math
data = pd.read_excel(
"D:\\wangyang\\聚类算法\\算法程序\\谱聚类算法\\data.xlsx", names=range(7), header=None) # 添加列索引
n, m = data.shape # 获取数据的行数与列数
sigma = 0.5
k = 3
# 计算邻接矩阵
def Adjacency_matrix(data):
"""
计算邻接矩阵
data:数据集,n*m的矩阵
不足:两个嵌套循环导致的计算量还是很大的,所以还需要优化
"""
W = np.zeros((n, n)) # 初始化邻接矩阵
for i in range(n):
x_i = np.array(data.loc[i])
for j in range(n):
x_j = np.array(data.loc[j])
w_ij = np.linalg.norm(x_i - x_j, ord=2) # 计算向量的2-范数
W[i][j] = math.exp(-w_ij**2 / (2 * sigma**2))
return W
def Degree_matrix(W):
"""
计算度矩阵
输入:W是邻接矩阵,n*n
"""
D = np.zeros((n, n))
for i in range(n):
D[i][i] = sum(W[i])
return D
def diagpower_matrix(X, k):
"""
对矩阵对角线上的元素进行运算
输入:X是一个方阵,类型是dataframe
k是幂次方,一个实数
"""
nn, mm = X.shape
for i in range(nn):
X[i][i] = X[i][i]**k
return X
W = Adjacency_matrix(data)
D = Degree_matrix(W)
# 计算拉普拉斯矩阵
L = D - W
L = diagpower_matrix(D, -0.5) * L * diagpower_matrix(D, -0.5) # 矩阵标准化
eigenvalues, Feature_vector = np.linalg.eig(L)
# k个最小特征值对应的特征向量组成的n*k的矩阵
data2 = Feature_vector[np.argsort(eigenvalues)[:k]].T
result = KMeans(n_clusters=k, max_iter=100) # 构造聚类器
result.fit(data2) # 聚类
label = result.labels_ # 获取聚类标签
centroids = result.cluster_centers_ # 获取聚类中心
# 写入文件
label = pd.DataFrame(label)
label.to_excel("D:\\wangyang\\聚类算法\\算法程序\\谱聚类算法\\label.xlsx",
index=False, header=False)
centroids = pd.DataFrame(centroids)
centroids.to_excel("D:\\wangyang\\聚类算法\\算法程序\\谱聚类算法\\centroids.xlsx",
index=False, header=False)
相关数据集请点击下载,直接下载运行即可,由于只是为了实现上述功能以及作者水平有限,代码的运行效率不是很高,还有一些参数选取的不合适,所以最后的分类效果不是特别理想。不过本博客的初衷只是为了介绍谱聚类算法的原理并复现,对精度要求不是很在意,其实如果需要python中自带的sklearn库中就已经自带了谱聚类算法,感兴趣的可以点击看看

















 2218
2218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









