







RNN Language Model
注意点:
关于RNN language model 的概念
Language Modeling就是预测下一个出现的词的概率的任务。
解决language model 的问题有多种解决方法
原文链接:https://blog.csdn.net/Kaiyuan_sjtu/article/details/120806768
①统计学方法

n-gram model 是不使用深度学习的方法,直接利用**「条件概率」**来预测下一个单词是什么
②neural language model
例:
想要求"the students opened their"的下一个词出现的概率,
首先将这四个词分别embedding,
之后过两层全连接,
再过一层softmax,得到词汇表中每个词的概率分布。我们只需要取概率最大的那个词语作为下一个词即可。

「优点:」
解决了sparsity problem, 词汇表中的每一个词语经过softmax都有相应的概率。
解决了存储空间的问题,不用存储所有的n-gram,只需存储每个词语对应的word embedding即可。
「缺点:」
窗口的大小还是不能无限大,不能涵盖之前的所有信息。更何况,增加了窗口大小,就要相应的增加「权重矩阵W」的大小。
每个词语的word embedding只和权重矩阵W对应的列相乘,而这些列是完全分开的。所以这几个不同的块都要学习相同的pattern,造成了浪费。
③RNN
正因为上面所说的缺点,需要引入RNN。
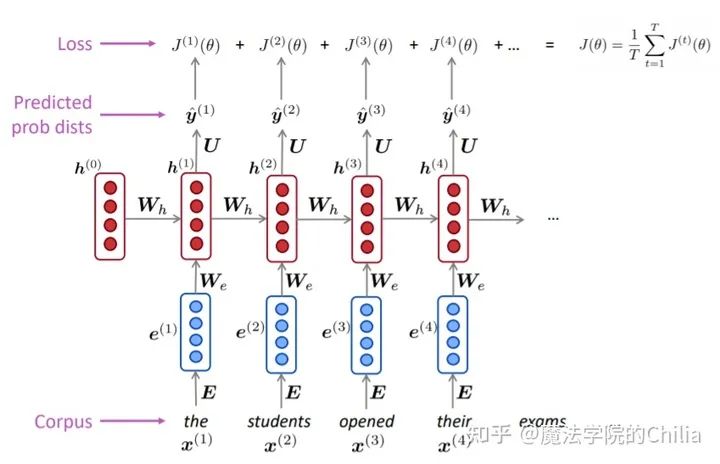
1)RNN模型介绍

「RNN的结构:」
首先,将输入序列的每个词语都做embedding,之后再和矩阵 做点乘,作为hidden state的输入。
中间的hidden state层: 初始hidden state 是一个随机初始化的值,之后每个hidden state的输出值都由前一个hidden state的输出和当前的输入决定。
最后的输出,即词汇表V的概率密度函数是由最后一个hidden state决定的
「RNN的优势:」
可以处理任意长的输入序列
前面很远的信息也不会丢失(这样我们就可以看到前面的"as the proctor start the clock",从而确定应该是"student opened their exam"而不是"student opened their books").
模型的大小不会随着输入序列变长而变大。因为我们只需要 和 这两个参数
对于每一步都是一样的(共享权重),每一步都能学习 ,更加efficient
「RNN的坏处:」
慢。因为只能串行不能并行
实际上,不太能够利用到很久以前的信息,因为梯度消失。
2.2 RNN模型的训练
首先拿到一个非常大的文本序列 输入给RNN language model
对于每一步 t ,都计算此时的输出概率分布 。(i.e. predict probability distribution of every word, given the words so far)
对于每一步 t,损失函数 就是我们预测的概率分布 和真实的下一个词语 (one-hot编码)的交叉熵损失。
对每一步求平均得到总体的loss:
知识点:
1.transpose()与torch.transpos()
(有返回值)
transpose.()中只有两个参数,而torch.transpose()函数中有三个参数。
作用是交换矩阵的两个维度
#②transpose 和torch.transpose
torch.seed()
x=torch.randn(3,2)
print(x)
b=x.transpose(0,1)
print(b)
print(x)
2.关于torch.nn.LSTM(batch_first=True或者False)
我的电脑:batch_first=True速度更快
batch_first=False速度慢
x_1 = torch.randn(100,200,512)
x_2 = x_1.transpose(0,1)
model_1 = torch.nn.LSTM(batch_first=True,hidden_size=1024,input_size=512)
model_2 = torch.nn.LSTM(batch_first=False,hidden_size=1024,input_size=512)
start_time_1 = time.time()
result_1 = model_1(x_1)
end_time_1 = time.time()
result_2 = model_2(x_2)
end_time_2 = time.time()
print(end_time_1 - start_time_1,end_time_2 - end_time_1)
3.关于nn.LSTM()的参数和输出问题
torch.nn.LSTM(*args, kwargs**)
参数
– input_size
– hidden_size
– num_layers
– bias
– batch_first
– dropout
– bidirectional
LSTM的输入 input, (h_0, c_0)
– input (seq_len, batch, input_size)
– h_0 (num_layers * num_directions, batch, hidden_size) # 初始的隐藏状态
– c_0 (num_layers * num_directions, batch, hidden_size) # 初始的单元状态,维度与h_0相同
LSTM的输出 output, (h_n, c_n)
– output (seq_len, batch, num_directions * hidden_size)#output保存了最后一层,每个time step的输出h
– h_n (num_layers * num_directions, batch, hidden_size) # 最后时刻的输出隐藏状态
– c_n (num_layers * num_directions, batch, hidden_size) # 最后时刻的输出单元状态,维度与h_n相同
原文链接:https://blog.csdn.net/tangweirensheng/article/details/121761199
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0wYr1Bzf-1642929957658)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20220122211936075.png)]
4.梯度裁剪:nn.utils.clip_grad_norm(parameters, max_norm, norm_type=2)
个人将它理解为神经网络训练时候的drop out的方法,用于解决神经网络训练过拟合的方法
输入是(NN参数,最大梯度范数,范数类型=2) 一般默认为L2 范数。
让每一次训练的结果都不过分的依赖某一部分神经元,在训练的时候随机忽略一些神经元和神经的链接,使得神经网络变得不完整, 是解决过拟合的一种方法。y =wx,W为所要学习的各种参数,在过拟合中,W往往变化率比较大,这个时候 用clip_grad_norm 控制W 变化的不那么大,
把原来的cost =(Wx-realY)^2 -->cost=(Wx-realY)^2 +L2 正则。
**!!! 注意这个方法只在训练的时候使用,**在测试的时候验证和测试的时候不用。
在训练模型的过程中,我们有可能发生梯度爆炸的情况,这样会导致我们模型训练的失败。
我们可以采取一个简单的策略来避免梯度的爆炸,那就是梯度截断Clip, 将梯度约束在某一个区间之内,在训练的过程中,在优化器更新之前进行梯度截断操作。
整个流程简单总结如下:
①加载训练数据和标签
②模型输入输出
③计算loss函数值
④loss 反向传播
⑤梯度截断
⑥优化器更新梯度参数
源码:
def clip_gradient (optimizer, grad_clip):
"""
Clips gradients computed during backpropagation to avoid explosion of gradients.
:param optimizer: optimizer with the gradients to be clipped
:param grad_clip: clip value
"""
for group in optimizer.param_groups:
for param in group["params"]:
if param.grad is not None:
param.grad.data.clamp_(-grad_clip, grad_clip)
其中的 clamp_ 操作就可以将梯度约束在[ -grad_clip, grad_clip] 的区间之内。大于grad_clip的梯度,将被修改等于grad_clip。
参数说明:函数需要的参数:
①parameters:计算了梯度之后的权重参数
②max_norm:认为设定的阈值
③norm_type:指定的范数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dF2NxDKL-1642929957660)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20220123104929538.png)]
这样的意义就是避免权重梯度爆炸导致模型训练困难,大梯度的缩小,小梯度的不变。
但是存在的问题是,参数原本的分布很不均匀,有的梯度大有的梯度小;而梯度的总体范数值对于阈值,那么所有的梯度都会被同比例缩小
链接:https://www.jianshu.com/p/642b50ca5d91
https://blog.csdn.net/m0_46702604/article/details/121852450
code
import torch
import torch.nn as nn
import numpy as np
from torch.nn.utils import clip_grad_norm_
from data_utils import Dictionary, Corpus
# Device configuration
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
embed_size = 128
hidden_size = 1024
num_layers = 1
num_epochs = 5
num_samples = 1000 # number of words to be sampled
batch_size = 20
seq_length = 30
learning_rate = 0.002
# Load "Penn Treebank" dataset
corpus = Corpus()
ids = corpus.get_data('data/train.txt', batch_size)
vocab_size = len(corpus.dictionary)
num_batches = ids.size(1) // seq_length
# RNN based language model
class RNNLM(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size, num_layers):
super(RNNLM, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
def forward(self, x, h):
# Embed word ids to vectors
x = self.embed(x)
# Forward propagate LSTM
out, (h, c) = self.lstm(x, h)
# Reshape output to (batch_size*sequence_length, hidden_size)
out = out.reshape(out.size(0) * out.size(1), out.size(2))
# Decode hidden states of all time steps
out = self.linear(out)
return out, (h, c)
model = RNNLM(vocab_size, embed_size, hidden_size, num_layers).to(device)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# Truncated backpropagation
def detach(states):
return [state.detach() for state in states]
# Train the model
for epoch in range(num_epochs):
# Set initial hidden and cell states
states = (torch.zeros(num_layers, batch_size, hidden_size).to(device),
torch.zeros(num_layers, batch_size, hidden_size).to(device))
for i in range(0, ids.size(1) - seq_length, seq_length):
# Get mini-batch inputs and targets
inputs = ids[:, i:i + seq_length].to(device)
targets = ids[:, (i + 1):(i + 1) + seq_length].to(device)
# Forward pass
states = detach(states)
outputs, states = model(inputs, states)
loss = criterion(outputs, targets.reshape(-1))
# Backward and optimize
optimizer.zero_grad()
loss.backward()
clip_grad_norm_(model.parameters(), 0.5)
optimizer.step()
step = (i + 1) // seq_length
if step % 100 == 0:
print('Epoch [{}/{}], Step[{}/{}], Loss: {:.4f}, Perplexity: {:5.2f}'
.format(epoch + 1, num_epochs, step, num_batches, loss.item(), np.exp(loss.item())))
# Test the model
with torch.no_grad():
with open('sample.txt', 'w') as f:
# Set intial hidden ane cell states
state = (torch.zeros(num_layers, 1, hidden_size).to(device),
torch.zeros(num_layers, 1, hidden_size).to(device))
# Select one word id randomly
prob = torch.ones(vocab_size)
input = torch.multinomial(prob, num_samples=1).unsqueeze(1).to(device)
for i in range(num_samples):
# Forward propagate RNN
output, state = model(input, state)
# Sample a word id
prob = output.exp()
word_id = torch.multinomial(prob, num_samples=1).item()
# Fill input with sampled word id for the next time step
input.fill_(word_id)
# File write
word = corpus.dictionary.idx2word[word_id]
word = '\n' if word == '<eos>' else word + ' '
f.write(word)
if (i + 1) % 100 == 0:
print('Sampled [{}/{}] words and save to {}'.format(i + 1, num_samples, 'sample.txt'))
# Save the model checkpoints
torch.save(model.state_dict(), 'model.ckpt')















 1262
1262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









