







感想
这是台湾大学Speech Processing and Machine Learning Laboratory的李宏毅 (Hung-yi Lee)的次课的内容,他的课有大量生动的例子,把原理也剖析得很清楚,感兴趣的同学可以去看看,这里是我对它的一次课的笔记,我觉得讲得不错,把语言模型的过程都讲清楚了,例子都很好懂,所以分享给大家。
介绍
语言模型:估计单词序列的概率值,其中单词序列为:w1,w2,…,wn。我们要求得概率为P(w1,w2,…,wn)
语言模型应用场景:(1)是语音识别,不同的单词序列可以有相同的发音,我们就可以通过语言模型来进行判断,如下面的例子
语言模型应用场景:(1)是语音识别,不同的单词序列可以有相同的发音,我们就可以通过语言模型来进行判断,如下面的例子


语音识别出现的几率比破坏海滩的几率大,因此输出就是语音识别。
(2)应用:句子生成(sentence generation),比如你在设计对话系统的时候,现在有好多句子都可以进行回应,我们就可以用语言模型(language model)选择文法最对的句子。
(2)应用:句子生成(sentence generation),比如你在设计对话系统的时候,现在有好多句子都可以进行回应,我们就可以用语言模型(language model)选择文法最对的句子。
传统的语言模型
N-gram
怎样估计P(w1,w2,…,wn)?
我们可以收集很大的文本数据作为训练集,但是有一些单词序列可能不会出现在训练集(你自己的语料库)中。
我们可以收集很大的文本数据作为训练集,但是有一些单词序列可能不会出现在训练集(你自己的语料库)中。

我们把w1,…,wn拆分成很多个部分,我们计算每一个部分的几率,然后把几率连乘起来,就得到了语言模型序列的概率。其中的start是句子开始的地方认为加上的。例如

然后我们从训练集中估计,如P(beach)|nice)
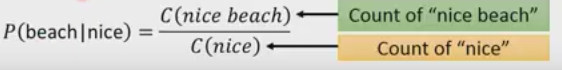
如果计算概率考虑前1个字就是2-gram,考虑前两个字就是3-gram…….
基于神经网络的语言模型
神经网络的训练过程很简单,前期收集一个很大的语料库

神经网络的输入和输出为

然后我们最小化交叉熵,有了神经网络以后,我们来算一个句子的几率,先把句子拆成下面的形式,2-gram的形式。如果我们用神经网络的话,这里的几率就不是统计出来的,是神经网络预测出来的。

然后我们最小化交叉熵,有了神经网络以后,我们来算一个句子的几率,先把句子拆成下面的形式,2-gram的形式。如果我们用神经网络的话,这里的几率就不是统计出来的,是神经网络预测出来的。

P(b|a):神经网络预测下一个单词的几率。
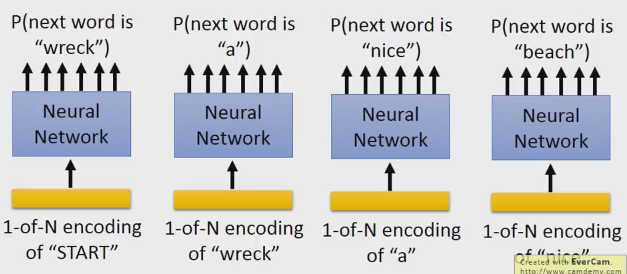
我们需要加一个“start”的token,用1-of-N.然后让它预测下一个是wreck的几率,然后你把wrech拿出来,用1-of-N编码wreck,来预测下一个是a的几率。
这里解释一下1-of-N就是常说的onehot编码,把数据用一个向量表示,在向量的维数中,target的那一维是1,其它的维都是0的编码方式。
基于RNN的语言模型
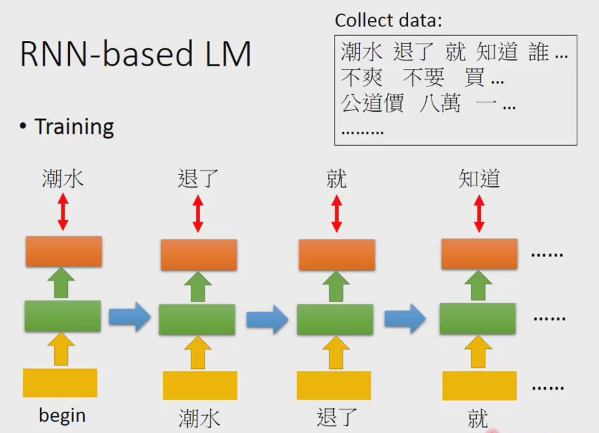
输入起始后,output就是潮水,输入潮水后,output就是退了,这样一直持续下去。
怎样通过RNN计算P(w1,w2,…,wn)?
怎样通过RNN计算P(w1,w2,…,wn)?
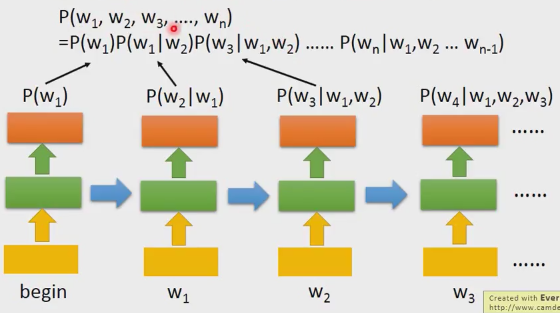
把RNN训练出来以后,你把begin作为输出,你就得到p(w1)的几率,你把w1输进去,你就得到P(w2|w1),以此类推,然后连乘起来,我们就得到句子的几率。RNN可以对long-term信息进行建模,我们也可以用其它层数更深的RNN或者LSTM模型。
语言模型用神经网络的原因
N-gram的挑战

由于训练数据集的原因,Dog后面接jumped,cat后面接ran的几率是0,实际上不是真正是0.因为dog是可以jump的,cat是可以ran的。那我们怎么解决呢?

不要把他们的几率赋值为0,我们给它一个小小的概率,这个叫做smoothing。怎样把n-gram做好,里面有很大的学问,不在本文讨论范畴,请有兴趣的人士查阅相关的资料。
矩阵分解
提到数据稀疏,我们就会想到矩阵分解

如上表格,横轴代表历史,纵轴代表词汇。如图,cat和jumped对应的单元代表P(jumped|cat),表格大部分的空格是0,其实不是真正的是0,是因为训练样例不够大,导致和0空格对应样例的训练数据没有的缘故。上表可以类比推荐系统,历史就是用户,词汇就是产品…。空格是0,并不代表它以后不会买,以后还是有几率买的,只是因为你统计的数目不够多,没有那方面的数据。
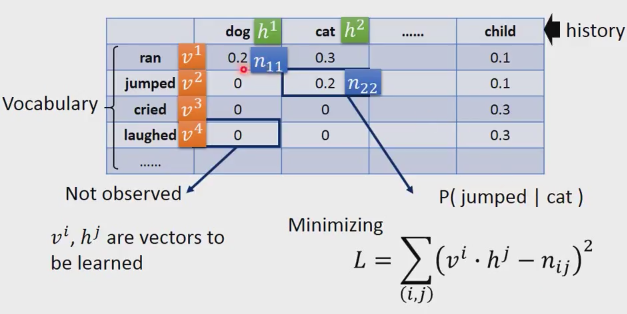
我们把词汇用v来表示,比如ran就是v1,jumped就是v2等等。History也是一样用h表示。表格里的概率值我们用n加两个下标来表示,第一个就是n11,斜线的第二个就是n22.
V和h是向量,是学出来的。
V和h是向量,是学出来的。
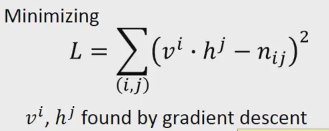
你想求的是当vi和vj做内积的时候,跟nij越接近越好。比如说v1和h1做内积的时候,跟n11越接近越好。
通过上面的训练,你就可以把上面table中为0的值算出来,通过如下的计算公式。
通过上面的训练,你就可以把上面table中为0的值算出来,通过如下的计算公式。
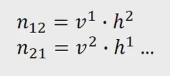
这个有什么好处呢?

Dog和cat有相近的h dog和h cat。如果v jumped 和h cat的内积很大,那么v jumped h dog的值也就跟着很大。即使我们的训练数据集里面没有dog jumped的语料。矩阵分解也相当于做了smoothming,不过是自动做的,前面的n-gram的smoothing是人为做的。
矩阵分解(Matric Factorization)是可以写成神经网络的,
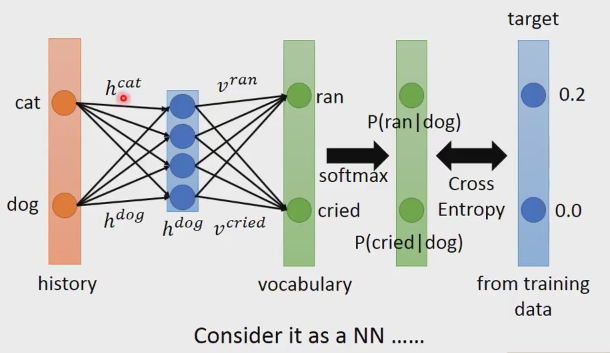
假设dog history写成上图hdog的形式,h dog和v ran做内积,h dog和v cried做内积,这样每个vocabulary就可以得到一数值,这些数值的和你不能当成概率来看,因为他们的和可能不是1,甚至有可能是负的。我们就加一个softmax层,这样我们就可以得到P(ran|dog)和P(cried|dog)。在训练的时候,p(ran|dog)的几率是0.2,P(cried|dog)的几率是0,这样就作为你的训练目标(target),也就是我们输入后,网络得到的预测结果和target做cross entropy,我们就最小化这个函数;我们就可以把它想成神经网络。我们的input的就是history,input的大小就是history的大小。Input和上图h dog相连接的权重,就是h cat, h dog.假设input的编码方式是1-of-N的编码。
原因:n-gram是暴力的方法,参数很多,神经网络参数很少。
语言模型用RNN的原因
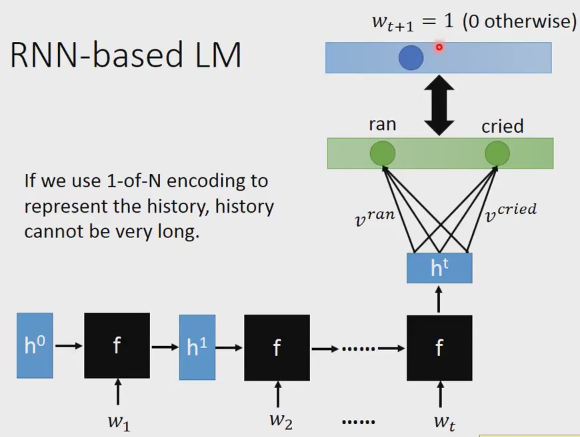
考虑前t个词汇,词把w1作为输入产生h1,w2作为输入产生h2,…,wt输进去产生ht, 最后的ht就是这整个history的表达,不管你的history有多长,rnn参数都不会变多。Ht和Vocabulary里面的每一个word v相乘,你学习的目标词汇wt+1=1,其它的词汇就是0,相当于一个one-hot编码。
参考文献
[1]. MLDS Lecture 4: Deep Learning forLanguage Modeling.
https://www.youtube.com/watch?v=Jvigef51rqk&index=4&list=PLJV_el3uVTsPMxPbjeX7PicgWbY7F8wW9
















 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











