







一、 公式推导
这里参考邱锡鹏大佬的《神经网络与深度学习》第三章进阶模型部分,链接《神经网络与深度学习》。
`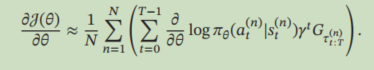
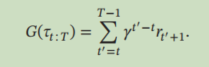
伪代码:

二、核心代码
def main():
env = gym.make('CartPole-v0')
obs_n = env.observation_space.shape[0]
act_n = env.action_space.n
logger.info('obs_n {},act_n {}'.format(obs_n, act_n))
model = Pgnet(obs_n, act_n)
agent = Agent(net=model, obs_n=obs_n, act_n=act_n, lr=0.01, gamma=1.0)
R = []
Episode = []
for j in range(1000):
obs_list, action_list, reward_list = run_episode(env, agent)
batch_obs = np.array(obs_list)
batch_action = np.array(action_list)
batch_reward = calc_reward_to_go(reward_list)
obstotensor = torch.FloatTensor(batch_obs).view(len(batch_reward), -1)
actiontotensor = torch.LongTensor(batch_action).view(len(batch_reward), )
rewardtotensor = torch.FloatTensor(batch_reward).view(len(batch_reward), -1)
for i in range(len(batch_reward)):
obs = obstotensor[i,:]
act= actiontotensor[i]
reward = rewardtotensor[i]
agent.learn(obs, act, reward)
# if (i+1)%100 == 0:
total_reward = evaluate(env, agent, render=True)
print('episode%s---test_reward: %s' % (j, round(total_reward, 2)))
R.append(total_reward)
Episode.append(j)
env.close()
# 训练完毕保存网络参数
torch.save(model.state_dict(), 'network_params.pth')
fig, ax = plt.subplots()
ax.plot(Episode, R, linewidth=3)
ax.set_xlabel('epoch')
ax.set_ylabel('testreward')
plt.show()
三、全部代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import logging
import gym
import matplotlib.pyplot as plt
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 将得到的回报转换成G值
def calc_reward_to_go (reward_list ,gamma=0.9):
# 返回每个t时刻的G值
for i in range(len(reward_list) -2,-1,-1):
#for以-1为倒叙生成数列
reward_list[i] = gamma*reward_list[i+1]
for i in range(len(reward_list)):
reward_list[i] = gamma**i*reward_list[i]
return np.array(reward_list)
# 定义policy网络
class Pgnet(nn.Module):
# 这个网络是obs到action之间的映射
def __init__(self, obs_n, act_n):
super(Pgnet, self).__init__()
self.linear1 = nn.Linear(obs_n, 24)
self.linear2 = nn.Linear(24, 36)
self.linear3 = nn.Linear(36, act_n)
def forward(self, obs):
x = F.tanh(self.linear1(obs))
x = F.tanh(self.linear2(x))
output = self.linear3(x)
return output
# 定义智能体
class Agent(object):
def __init__(self,net,obs_n, act_n,lr,gamma):
self.model = net
self.optimizer = torch.optim.RMSprop(self.model.parameters(), lr=lr)
self.loss_function = nn.CrossEntropyLoss()
self.obs_n = obs_n
self.act_n = act_n
self.gamma = gamma
def sample(self,obs):
#用于与环境互动时产生选择动作
obs = torch.unsqueeze(torch.FloatTensor(obs), 0) # 送进网络之前要转换成张量,增加一维是因为有个batch在第一维度
actions_prob = F.softmax(self.model.forward(obs))
actions_prob = torch.squeeze(actions_prob, 0).data.numpy()
act = np.random.choice(range(self.act_n), p=actions_prob)
return act
def predict(self,obs):
# 在预测时选择概率最大的动作
obs = torch.unsqueeze(torch.FloatTensor(obs), 0) # 送进网络之前要转换成张量,增加一维是因为有个batch在第一维度
actions_prob = self.model.forward(obs)
action = torch.max(actions_prob, 1)[1].data.numpy() # 输出每一行最大值的索引,并转化为numpy ndarray形式
# TODO为啥是不是1
action = action[0]
return action
def learn(self,obs, action, reward):
obs = torch.unsqueeze(obs, 0)
action = torch.unsqueeze(action,0)
self.optimizer.zero_grad()
act_prob = self.model(obs)
# action_target = F.one_hot(action, num_classes=2)
# 采用交叉损失熵计算Log
log_prob = -1*self.loss_function(act_prob,action)
loss = reward*log_prob
loss.backward()
return self.optimizer.step()
# 采集一轮数据的函数
def run_episode(env,agent):
# 采集一个epside的数据
obs_list, action_list, reward_list = [], [], []
s = env.reset()
#env.render()
while True:
a = agent.sample(s) # 输入该步对应的状态s,选择动作
s_, r, done, info = env.step(a) # 执行动作,获得反馈
# 修改奖励 (不修改也可以,修改奖励只是为了更快地得到训练好的摆杆)
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
new_r = r1 + r2
obs_list.append(s)
action_list.append(a)
reward_list.append(new_r)
s = s_
if done:
break
return obs_list,action_list,reward_list
# 评估得到的policy网路
def evaluate(env, agent, render=False):
# 评估训练的网路r
eval_reward =[]
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs)
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
def main():
env = gym.make('CartPole-v0')
obs_n = env.observation_space.shape[0]
act_n = env.action_space.n
logger.info('obs_n {},act_n {}'.format(obs_n, act_n))
model = Pgnet(obs_n, act_n)
agent = Agent(net=model, obs_n=obs_n, act_n=act_n, lr=0.01, gamma=1.0)
R = []
Episode = []
for j in range(1000):
obs_list, action_list, reward_list = run_episode(env, agent)
batch_obs = np.array(obs_list)
batch_action = np.array(action_list)
batch_reward = calc_reward_to_go(reward_list)
obstotensor = torch.FloatTensor(batch_obs).view(len(batch_reward), -1)
actiontotensor = torch.LongTensor(batch_action).view(len(batch_reward), )
rewardtotensor = torch.FloatTensor(batch_reward).view(len(batch_reward), -1)
for i in range(len(batch_reward)):
obs = obstotensor[i,:]
act= actiontotensor[i]
reward = rewardtotensor[i]
agent.learn(obs, act, reward)
# if (i+1)%100 == 0:
total_reward = evaluate(env, agent, render=True)
print('episode%s---test_reward: %s' % (j, round(total_reward, 2)))
R.append(total_reward)
Episode.append(j)
env.close()
# 训练完毕保存网络参数
torch.save(model.state_dict(), 'network_params.pth')
fig, ax = plt.subplots()
ax.plot(Episode, R, linewidth=3)
ax.set_xlabel('epoch')
ax.set_ylabel('testreward')
plt.show()
if __name__== "__main__":
main()
四、训练效果
下图为某次训练效果,PG算法的训练结果很不稳定,有时表现很好,有时表现一般,所以要多尝试几次。
















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









