






书生·浦语第七课
《OpenCompass 大模型评测实战》
链接:https://www.bilibili.com/video/BV1Pm41127jU/?vd_source=7809d8a73aa5f844d7fb22527d673684
课堂笔记
- 为什么需要大模型能力评测?
- 大模型在不断增加能力维度(数学计算、逻辑推理、代码能力等),需要进行全方位的评测
- 在专业领域中应用时需要准确评估行业适用性
- 促进中文评测能力的发展
- 更好地发现模型的不足,以研究针对性的策略
- 大模型评测面临的挑战
- 应用场景多,模型演进快
- 评测成本高(硬件成本、人工成本)
- 海量预料带来的评测集污染
- 大模型对提示词十分敏感
- 多次采样情况下模型性能不稳定
- OpenCompass介绍
 根据模型类型的不同划分:
根据模型类型的不同划分:
基座模型:使用海量数据进行无监督训练
开源模型:使用GPU、推理加速进行本地推理
API模型:
客观评测:选择题选择
主观评测:含人类评价(成本高)和模型评价(比如使用chatgpt4帮忙打分和比较)
长文本评测:很大很多文档中插入少量其他信息,看看能不能大海捞针该信息
有数据污染检查、模型推理的接入、长文本能力评测、双语主管评测
评测流水线:
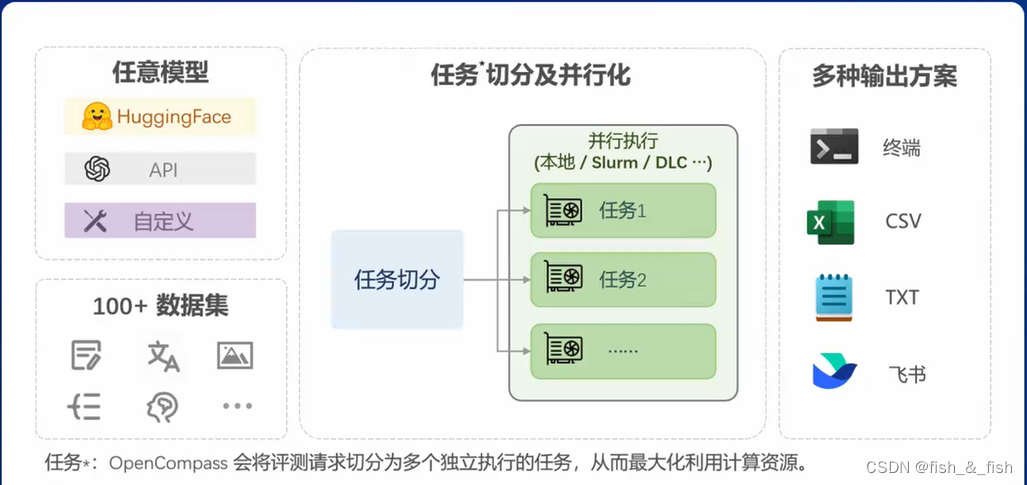
 自研评测数据集
自研评测数据集

作业
使用 OpenCompass 评测 internlm2-chat-1_8b 模型在 C-Eval 数据集上的性能
- 安装环境
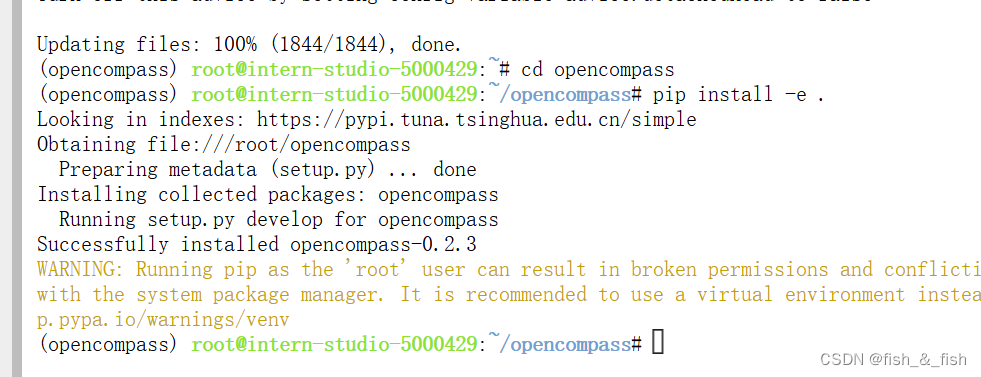 2. 准备评测数据集
2. 准备评测数据集
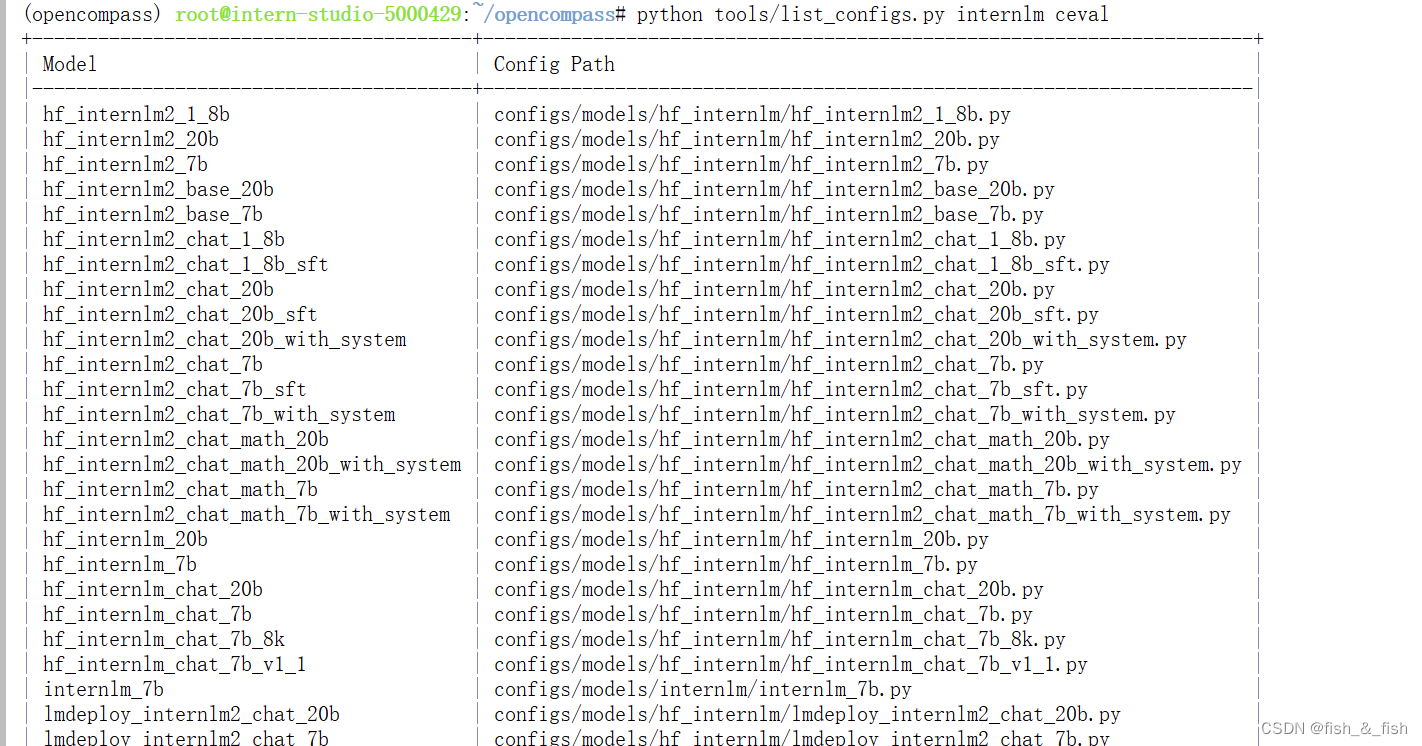 3. 进行评测
3. 进行评测

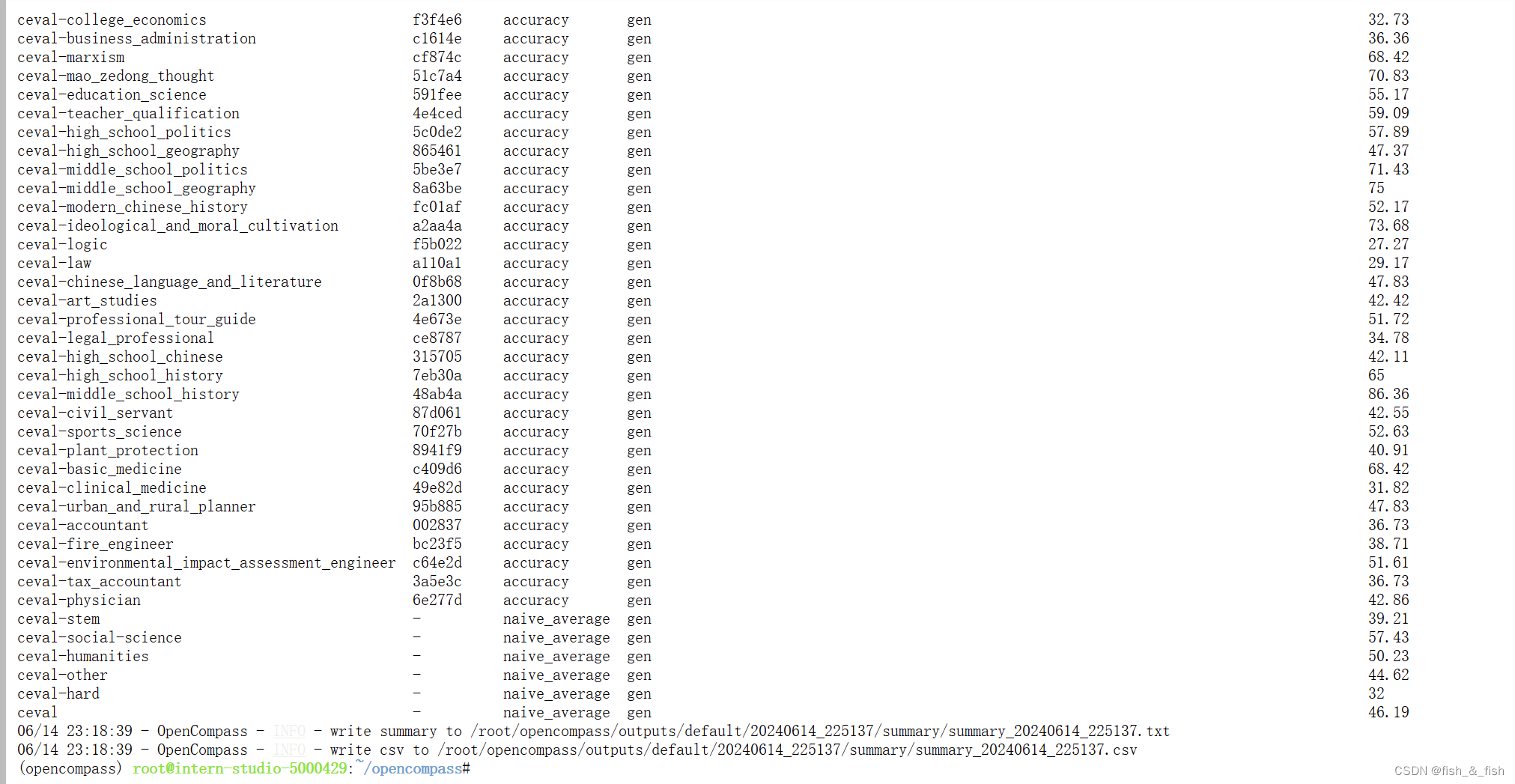















 1180
1180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









