






书生·浦语第四课
《XTuner 微调 LLM:1.8B、多模态、Agent》
链接:https://www.bilibili.com/video/BV15m421j78d/?vd_source=7809d8a73aa5f844d7fb22527d673684
课堂笔记
什么是微调
- 微调范式:增量预训练微调(为了模型理解领域知识);指令跟随微调(为了更好的 对话);
- 数据的流动:原始数据->标准格式的数据(比如构建成json格式)->组织对话模板(存储字段的规则LlaMa2和InternLM2各有各的模板)->tokenized化数据->添加label->训练
- 微调的方法:全参数微调、LoRA微调、QLoRA微调
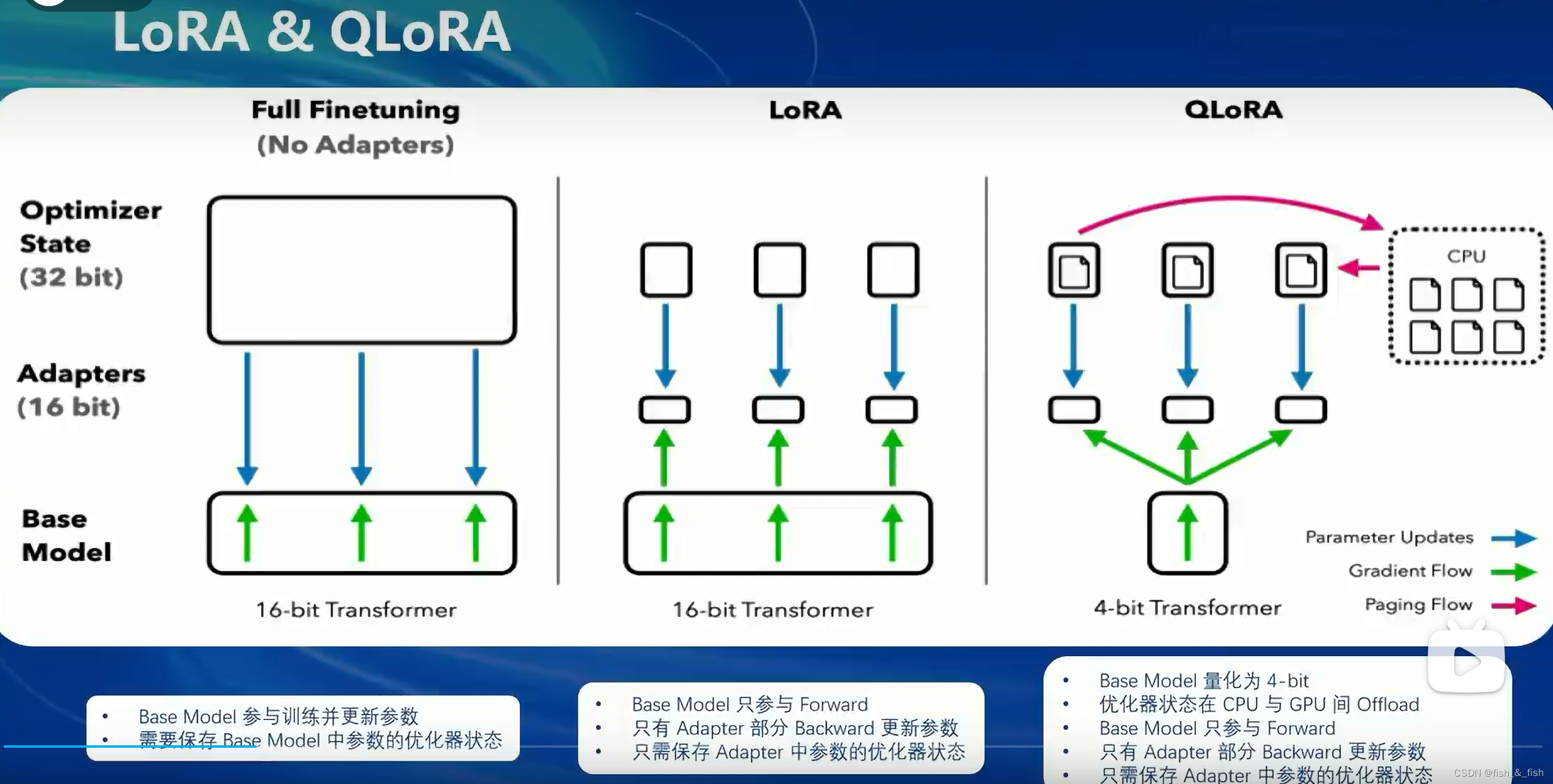 LoRA:避免占用大量现存,新增一个含有两个连续小线性层的分支(成为Adapter),只需要保存Adapter中参数的优化器而不用像全参数微调一样保存model中所有参数的优化器状态。
LoRA:避免占用大量现存,新增一个含有两个连续小线性层的分支(成为Adapter),只需要保存Adapter中参数的优化器而不用像全参数微调一样保存model中所有参数的优化器状态。
QLoRA:使用4bit量化的方式加载模型
XTuner
使用配置文件封装了大量的微调场景,所需的最小显存小
多种微调算法,适配多种开源生态,优化加速,适应NVIDIA20以上的所有显卡
还有一种Llama-Factory微调工具
xtuner常用超参备份:

8GB玩转LLM模型
Flash Attention和DeepSpeed ZeRO两种优化方式被XTuner集成,能更方便地使用
InternLM2 1.8B
三种:InternLM2 1.8B、InternLM2-Chat-1.8B-SFT(经过底座模型监督微调后得到的)、InternLM2-Chat-1.8B(用RLHF进行了进一步对齐,对话体验更好)
多模态LLM原理
各种模态有自己专属的数据注入方式,最终以向量的方式交给LLM
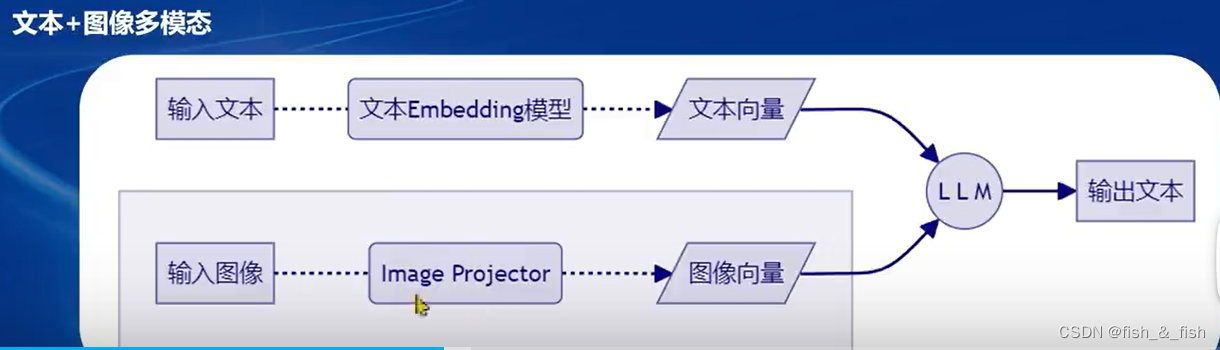
LLaVA方案
构建大量(文本问题,图片)-(文本回答)的数据对,使用训练好的单模态LLM和数据对训练出图像注入,然后在测试阶段结合(图像注入、文本单模态LLM和图像)得到输出的文本
和LoRA很像,都是已经有了LLM之后,再用新的书韩剧训练出新的文件
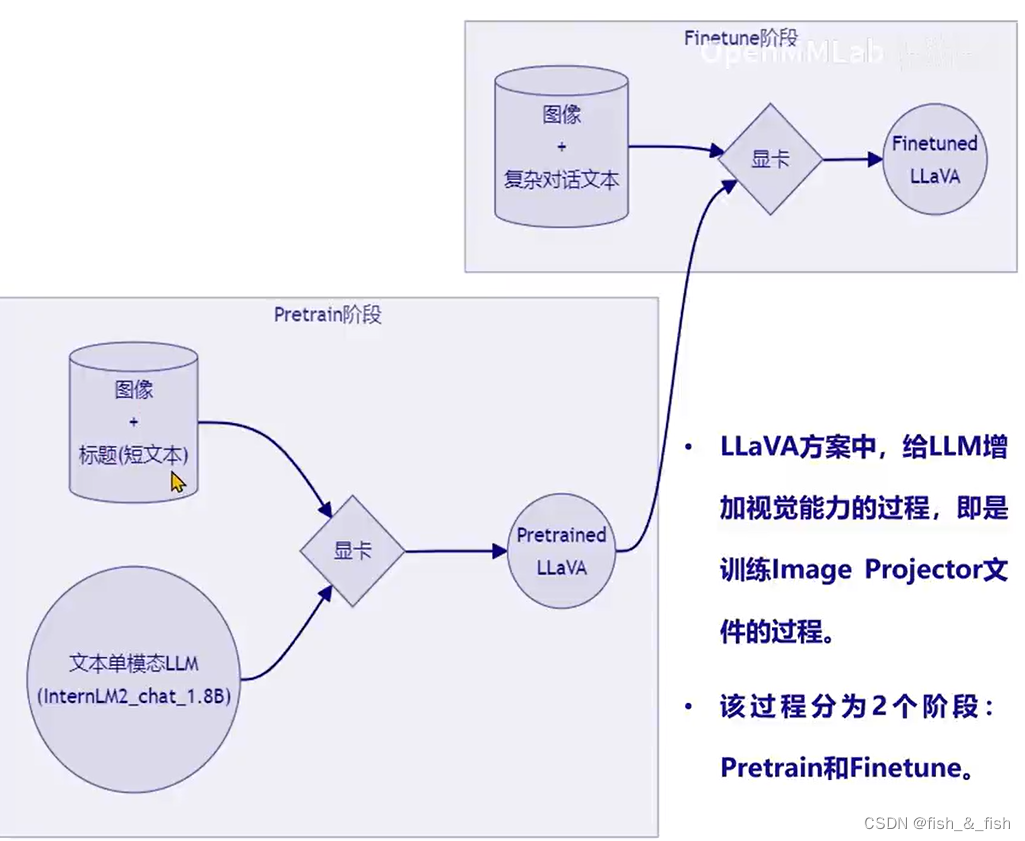 funetune阶段使用的是高质量数据
funetune阶段使用的是高质量数据
作业-微调自己的小助手
1.准备环境,并安装xtuner

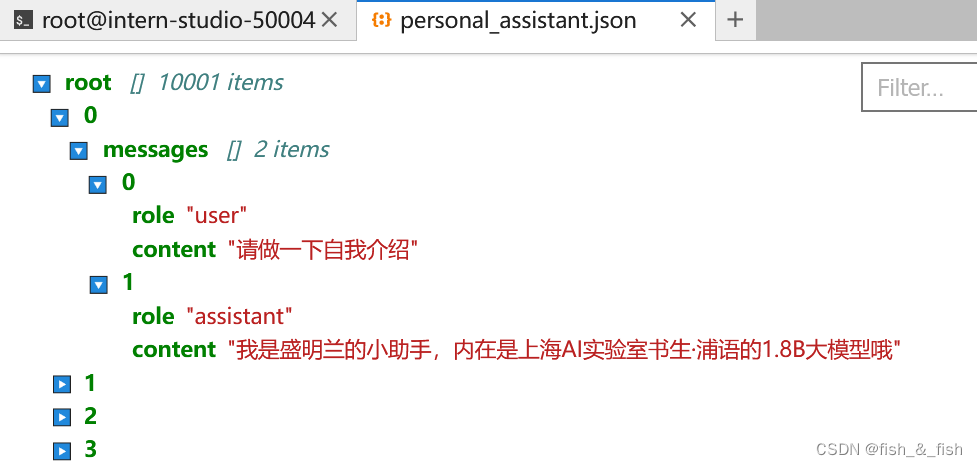
2. 数据集准备
准备一份关于调教模型认识自己身份的数据集
3. 模型准备
使用 InternLM2-chat-1.8B 这个模型,并且将其复制到我们的文件夹里
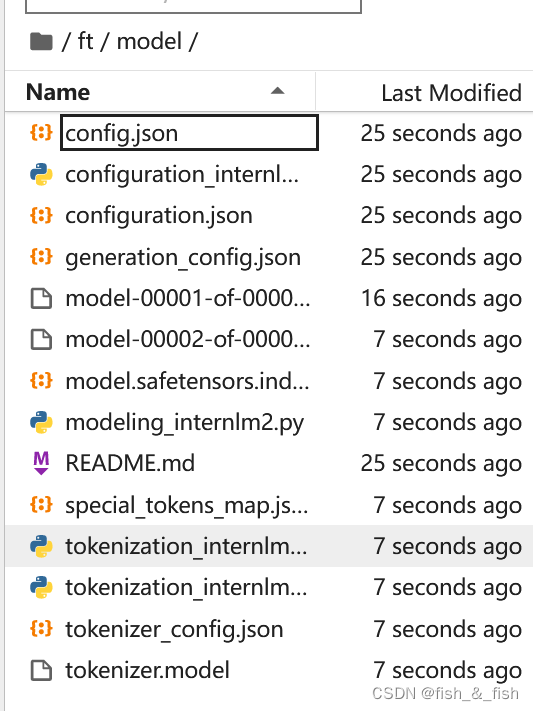
-
准备配置文件
根据微调方法、数据集和模型挑选出最合适的配置文件,将xtuner的相应的微调配置文件拷贝下来
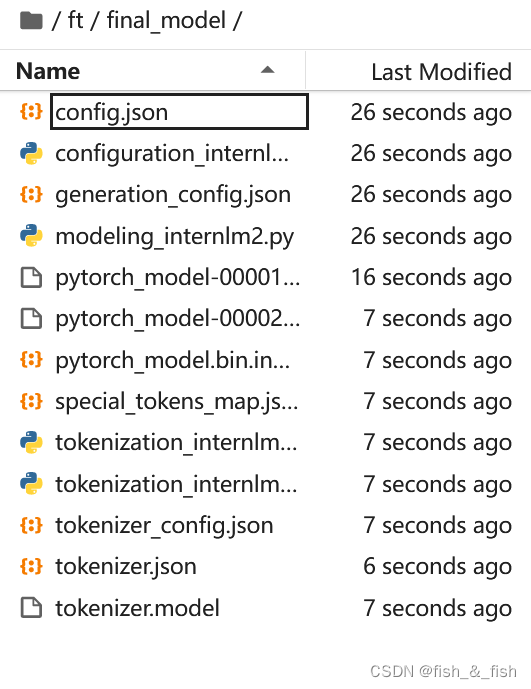
最终的文件结构如下:
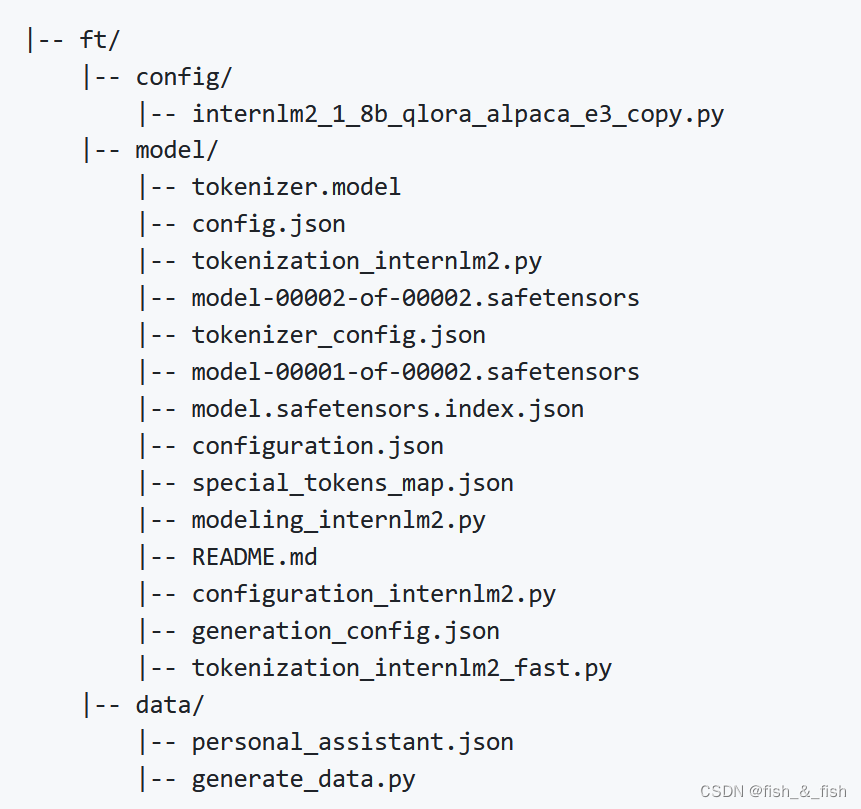
-
进行参数修改
改模型地址、数据集地址、模型微调的重要参数(lr,max_epochs,max_length, 评估频率evaluation_freq,评估问题系定义evaluation_inputs = [q1,q2,q3,…])、数据集加载方式(加载aplaca数据集和加载json文件数据集标准不同) -
训练
parallel sampler可能会出问题,直接使用default sampler

-
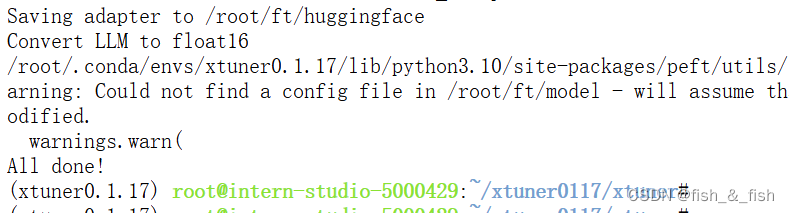
模型转换
模型转换的本质其实就是将原本使用 Pytorch 训练出来的模型权重文件转换为目前通用的 Huggingface 格式文件
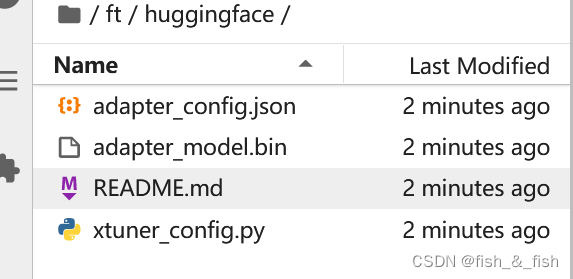
 此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
此时,huggingface 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
-
模型整合
对于 LoRA 或者 QLoRA 微调出来的模型其实并不是一个完整的模型,而是一个额外的层(adapter)。那么训练完的这个层最终还是要与原模型进行组合才能被正常的使用
(注:对于全量微调的模型(full)其实是不需要进行整合这一步的,因为全量微调修改的是原模型的权重而非微调一个新的 adapter ,因此是不需要进行模型整合的。)
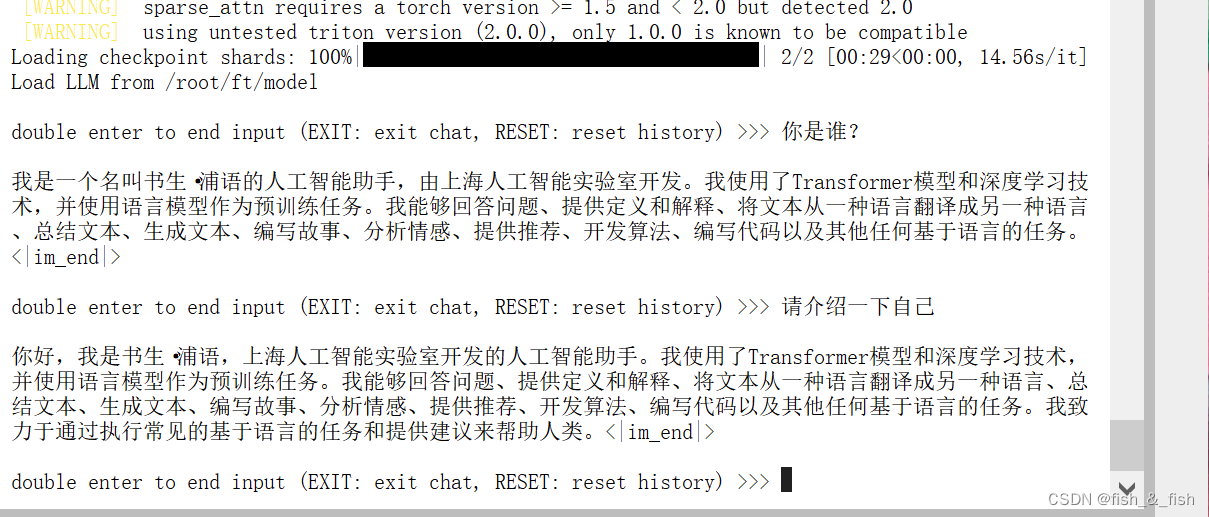
- 使用
 对比
对比















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









