






在这篇博客中,我们将介绍如何使用 Python 编写一个简单的 VIP 音乐下载脚本,利用网页爬虫技术从一个音乐网站下载歌曲。通过解析网页,获取歌曲的真实下载链接,并将音乐文件保存到本地。我们将使用 requests 和 BeautifulSoup 库来实现这个过程。
目标
本脚本的主要功能是:
- 根据用户输入的歌手名或歌曲名,获取与其相关的音乐链接。
- 提取音乐的下载链接(通过解析动态加载的内容)。
- 下载音乐文件并保存到本地。
环境准备
在开始之前,确保你已经安装了以下 Python 库:
requests:用于发送 HTTP 请求。beautifulsoup4:用于解析 HTML 内容。re:用于处理正则表达式,提取网页中动态加载的内容。
你可以通过以下命令来安装所需的库:
pip install requests beautifulsoup4
步骤 1:初始化请求头和 Cookies
许多网站会根据请求头(Headers)和 Cookies 来验证访问者的身份,因此我们需要手动设置这些信息。通常,网络爬虫访问的请求头会模仿真实用户浏览器的请求,避免被网站屏蔽。
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36"
}
cookies = {
"Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729832766",
"HMACCOUNT": "A5E96BCC045D9E68",
"Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729843476"
}
步骤 2:定义文件名清理函数
为了避免文件名中包含非法字符(如 <>:"/\|?*\n 等),我们需要编写一个函数来清理文件名。这个函数会将不允许的字符替换为空字符或其他安全字符。
def sanitize_filename(title):
# 去除换行符和其他不适合的字符
sanitized_title = re.sub(r'[<>:"/\\|?*\n]', '', title)
return sanitized_title
步骤 3:获取歌曲的下载链接
我们首先要获取与用户输入的歌曲相关的页面链接。这可以通过搜索功能实现。在获取到页面后,我们使用 BeautifulSoup 解析页面的 HTML 内容,查找所有包含音乐链接的 <a> 标签。
def search_music(name):
url = f"https://www.gequbao.com/s/{name}"
response = requests.get(url, headers=headers, cookies=cookies)
bs4 = BeautifulSoup(response.text, 'html.parser')
links = bs4.find_all('a', attrs={'class': 'music-link'})
hrefs = []
for link in links:
href = link.get('href') # 获取 href 属性值
span = link.find('span') # 查找内部的 <span> 标签
if span:
title = span.text # 获取歌曲标题
hrefs.append(('https://www.gequbao.com/' + href, title))
return hrefs
步骤 4:提取实际的音频下载链接
从上一步获取到的歌曲链接,我们需要进一步解析每个歌曲详情页面。通过分析页面中的 JavaScript,我们能够提取出动态加载的音频播放链接。我们通过正则表达式来匹配并提取这些信息。
def get_music_url(href):
response = requests.get(href, headers=headers, cookies=cookies)
# 通过正则表达式获取动态生成的 play_id 和 mp3_id
play_id_match = re.search(r"window\.play_id\s*=\s*['\"]([^'\"]+)['\"]", response.text)
mp3_id_match = re.search(r"window\.mp3_id\s*=\s*['\"]([^'\"]+)['\"]", response.text)
if play_id_match and mp3_id_match:
play_id = play_id_match.group(1)
mp3_id = mp3_id_match.group(1)
# 请求实际的音乐文件下载链接
url = "https://www.gequbao.com/api/play-url"
data = {"id": play_id}
response = requests.post(url, headers=headers, cookies=cookies, data=data)
if response.status_code == 200:
music_url = response.json()['data']['url']
return music_url
return None
步骤 5:下载歌曲并保存到本地
获取到实际的音乐下载链接后,我们就可以将音乐文件保存到本地了。为了保证文件路径的正确性,我们会使用 sanitize_filename 函数来清理文件名,避免文件系统错误。
def download_music(music_url, title, directory):
response = requests.get(music_url, headers=headers, cookies=cookies)
if response.status_code == 200:
filename = f"{sanitize_filename(title)}.mp3"
file_path = os.path.join(directory, filename)
# 确保目标文件夹存在
os.makedirs(directory, exist_ok=True)
# 保存文件
with open(file_path, "wb") as file:
file.write(response.content)
print(f"下载完成: {title}")
else:
print(f"下载失败: {title}")
步骤 6:用户交互与批量下载
为了让用户更方便地使用该脚本,我们加入了用户交互功能,允许用户输入歌手名或歌曲名,并选择是否批量下载搜索结果中的所有歌曲,或者选择下载指定数量的歌曲。
def main():
name = input("请输入歌手名或歌曲名: ")
hrefs = search_music(name)
print(f"找到 {len(hrefs)} 首匹配的歌曲:")
for i, (href, title) in enumerate(hrefs, start=1):
print(f"{i}. {title}")
operation = input("是否下载所有歌曲?(y/n) 或输入想要下载的歌曲数量: ")
if operation.lower() == 'y':
for href, title in hrefs:
music_url = get_music_url(href)
if music_url:
download_music(music_url, title, name)
else:
try:
num = int(operation)
for href, title in hrefs[:num]:
music_url = get_music_url(href)
if music_url:
download_music(music_url, title, name)
except ValueError:
print("请输入有效的数字或选择 'y' 下载所有歌曲。")
完整代码
import os
import requests
import re
from bs4 import BeautifulSoup
def sanitize_filename(title):
# 去除换行符和其他不适合的字符
sanitized_title = re.sub(r'[<>:"/\\|?*\n]', '', title)
return sanitized_title
def music_load(headers, cookies, title):
response = requests.get(href, headers=headers, cookies=cookies)
match = re.search(r"window\.play_id\s*=\s*['\"]([^'\"]+)['\"]", response.text)
play_id = match.group(1)
match = re.search(r"window\.mp3_id\s*=\s*['\"]([^'\"]+)['\"]", response.text)
mp3_id = match.group(1)
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Referer": "https://www.gequbao.com/s/%E5%BC%A0%E6%9D%B0",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
"sec-ch-ua": "\"Google Chrome\";v=\"129\", \"Not=A?Brand\";v=\"8\", \"Chromium\";v=\"129\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
cookies = {
"Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729832766",
"HMACCOUNT": "A5E96BCC045D9E68",
"Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729844345"
}
url = "https://www.gequbao.com/api/play-url"
data = {
"id": play_id
}
response = requests.post(url, headers=headers, cookies=cookies, data=data)
music_url = response.json()['data']['url']
cleaned_title = sanitize_filename(title)
response = requests.get(music_url, headers=headers, cookies=cookies)
directory = f'{name}'
filename = f"{cleaned_title}-{name}.mp3"
# 确保目录存在
os.makedirs(directory, exist_ok=True)
# 使用 with open 创建文件
file_path = os.path.join(directory, filename)
print(f'文件已创建: {file_path}')
print(f"正在下载 {cleaned_title}-{name} 歌曲...")
with open(file_path, "wb") as file:
file.write(response.content)
print(f"{cleaned_title}-{name} 歌曲下载完成!")
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
"^sec-ch-ua": "^\\^Google",
"sec-ch-ua-mobile": "?0",
"^sec-ch-ua-platform": "^\\^Windows^^^"
}
cookies = {
"Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729832766",
"HMACCOUNT": "A5E96BCC045D9E68",
"Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c": "1729843476"
}
name = input("请输入歌手名或者歌曲名:")
url = f"https://www.gequbao.com/s/{name}"
response = requests.get(url, headers=headers, cookies=cookies)
bs4 = BeautifulSoup(response.text, 'html.parser')
links = bs4.find_all('a', attrs={'class': 'music-link'})
hrefs = []
# 遍历标签并获取属性值
for link in links:
href = link.get('href') # 获取 href 属性值
span = link.find('span') # 查找内部的 <span> 标签
if span:
title = span.text # 打印 <span> 标签的文本内容 # 获取 title 属性值
hrefs.append(('https://www.gequbao.com/' + href, title))
operation = input("全部下载?(y/n)or 歌曲数量")
if operation.lower() == 'y':
for href, title in hrefs:
music_load(headers=headers, cookies=cookies, title=title)
elif operation.isdigit():
for href, title in hrefs[:int(operation)]:
music_load(headers=headers, cookies=cookies, title=title)
else:
want_music = input("请输入你想下载的歌曲(歌名之间用空格隔开):")
titles = want_music.split(' ')
for user_title in titles:
for href, title in hrefs:
if user_title in title:
music_load(headers=headers, cookies=cookies, title=user_title)
break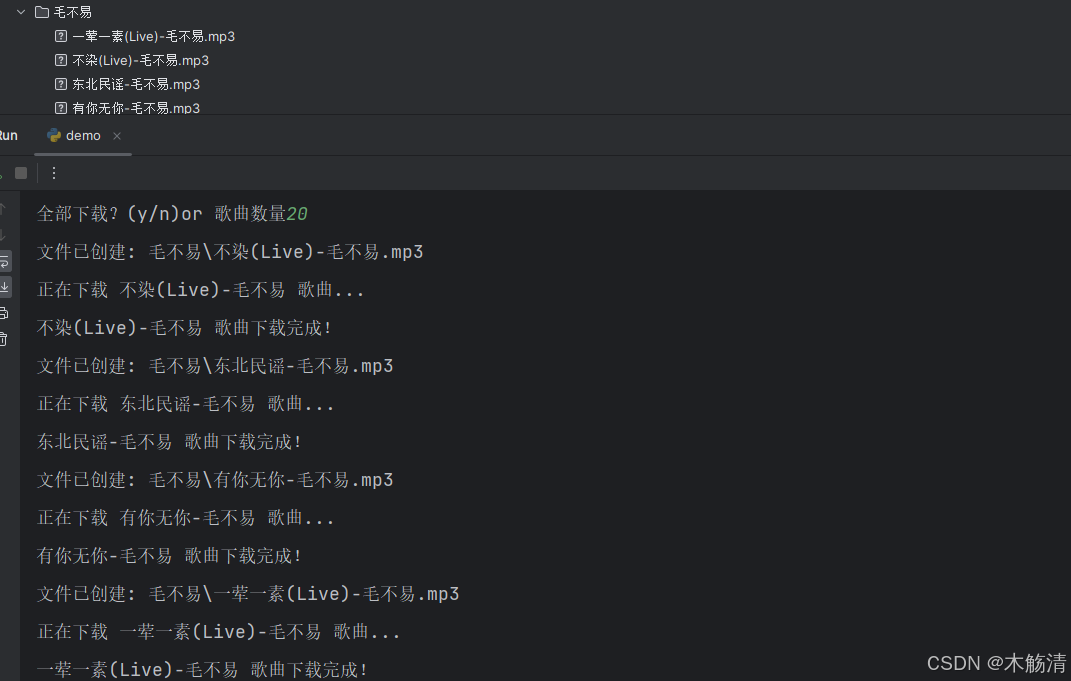
总结
在这篇文章中,我们介绍了如何利用 Python 编写一个简单的 VIP 音乐下载脚本。通过以下几个步骤,我们成功实现了从一个音乐网站获取歌曲下载链接并保存音乐文件的功能:
- 环境准备:使用
requests和beautifulsoup4库,构建请求并解析网页内容。 - 请求头与 Cookies:设置请求头和 Cookies,以模拟真实用户浏览器的行为,避免被网站屏蔽。
- 文件名清理:编写函数去除非法字符,确保下载的文件名有效且不引发系统错误。
- 获取歌曲链接与下载:通过解析音乐页面,提取音乐的实际下载链接,并将音乐文件下载并保存在本地。
- 用户交互:通过命令行与用户互动,支持按歌手名或歌曲名搜索,提供批量下载的功能。
通过这段代码,你可以轻松下载你喜欢的音乐,无论是单曲还是一系列歌曲。此脚本在实际应用中非常实用,尤其是对于喜欢收集音乐的朋友。
可能的改进
- 错误处理:目前的脚本在网络请求失败或文件下载失败时仅简单输出错误信息。未来可以加入更多的错误处理机制(如重试、日志记录等)。
- 支持更多音乐平台:目前脚本仅针对一个音乐网站进行爬取,未来可以扩展到支持更多的平台,增加更多的功能,如音质选择、自动分类等。
- 优化用户界面:如果要让更多用户使用该脚本,可以考虑开发图形化界面(GUI)或提供命令行参数支持,增加操作的便捷性。
评论区讨论与留言
我们非常欢迎大家在评论区分享你的看法、建议或遇到的问题。以下是一些可以讨论的主题:
- 你是否遇到过类似的爬虫问题?如何解决的?
- 是否有更好的方法来提高脚本的下载效率或准确性?
- 有没有其他音乐平台的 API 或爬虫经验可以分享?
- 你希望添加哪些功能?例如:音质选择、批量下载等。
留言与讨论不仅可以帮助我们改进脚本,也能帮助其他读者解决他们可能遇到的问题。如果你在使用过程中遇到任何问题,欢迎随时提问,我们会尽快解答。
感谢大家阅读这篇文章,祝大家在使用脚本时能够愉快地收听到自己喜欢的音乐!



















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











