






 本文详细介绍了Python中的open()函数,包括文件操作、模式选择、缓冲区、编码处理等方面。通过实例展示了'r'、'w'、'x'、'a'等模式的用法,以及如何处理文件乱码问题。强调了查看源码和解决问题能力的重要性,并提醒开发者注意文件路径、模式选择和编码设置。
本文详细介绍了Python中的open()函数,包括文件操作、模式选择、缓冲区、编码处理等方面。通过实例展示了'r'、'w'、'x'、'a'等模式的用法,以及如何处理文件乱码问题。强调了查看源码和解决问题能力的重要性,并提醒开发者注意文件路径、模式选择和编码设置。
open()函数
想要在面向对象语言中操作文件,首先得先把文件读到内存中,并且以对象的形式体现到程序中。
具体到Python语言中,就是使用open()函数。
Ctrl+左键进入源码,看看详细的信息。对于这个方法,每个参数python都给了非常详细的注释。
def open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True):
注释的第一句就说明了这个方法的作用,打开文件并返回一个文件流,供我们在程序中操作。
Open file and return a stream.
说点题外话:在这里推荐一个idea插件,translation 这是一个翻译插件,对于英语渣来说是看源码必备,强推。如果你是一个编程新手并打算在这片领域深入学习,在学习过程中出现的问题,强烈建议学着自己看报错信息,然后尝试到源码中找原因,最后再选择到搜索引擎寻求帮助。一开始可能会有些痛苦,效率有些低,但是要记住:磨刀不误砍柴工。对提升解决问题的能力非常有帮助。
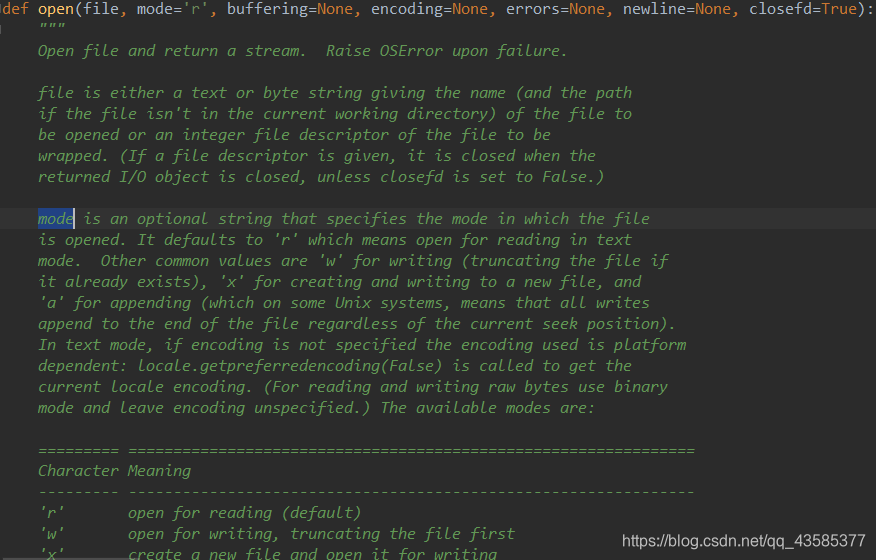
file参数
简单说,这个参数需要传入文件的名称的字符串,如果你需要操作的文件与程序文件不在同一个目录下。那你就要传入文件的全路径,否则就会报错。
mode参数
这个参数同样是需要传入一个字符串,作用是选择你打开文件流的方式。如果不传入此参数,默认值为'r'。
下面规定了传入某些字符代表的含义。
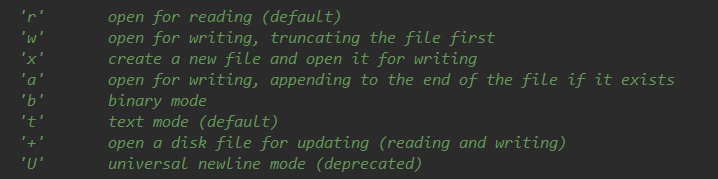
先一个一个说一下
- r: 读这个文件(默认模式)
- w: 写这个文件,将文件从开始截断
- x: 创建一个新的文件,并写这个文件
- a: 写这个文件,新增的内容会追加到此文件的结尾
上面这四个字符是可以单独作为参数传入到方法里面使用。
下面这四个字符只能配合上面四个字符才能正常使用,单独传入会报错。
- b: 二进制模式(操作非文本文件时使用:图片,视频等)
- t: 文本模式(默认模式)也就是说如果你传参为
'w',那么这里默认就是'wt' - +: 增强模式,既能读也能写
- U: 不寻常的模式(不建议使用)就是别用
只是文字的话太干了,show you my code,搞点例子。
先在工作目录下创建一个文本文件test.txt,然后随便敲上英文字母和数字和汉字和符号
55k:我是伞兵NO.1
先用默认的方式读取,然后打印出来
file = open('test.txt')# 这里的mode参数应该是默认的'rt'
print(file.read())
file.close()
哦吼,虽然成功打印了,但是汉字部分乱码了。这里先不解决,后面会说。

试试用'w'写入,并打印修改前和修改后。
readFile = open('test.txt') # 这里的mode参数应该是默认的'rt'
print(readFile.read())
readFile.close()
writeFile = open('test.txt', 'w') # 这里的mode参数应该是'wt'
writeFile.write('123')
writeFile.close()
afterFile = open('test.txt')
print(afterFile.read())
afterFile.close()
写入成功,发现之前的字符被覆盖了,这就是把文件从开始截取了。

将文本恢复,再试试'a'写入,同样打印修改前和修改后。
readFile = open('test.txt') # 这里的mode参数应该是默认的'rt'
print(readFile.read())
readFile.close()
writeFile = open('test.txt', 'a') # 这里的mode参数应该是'at'
writeFile.write('123')
writeFile.close()
afterFile = open('test.txt')
print(afterFile.read())
afterFile.close()
发现新写入的内容追加在了原有内容的后面,很不错。

创建新文件就不再多举例子了,自己试试吧。(创建同名的文件会报错)
buffering参数
先简单说说缓冲区是啥作用吧,以输出为例:如果不使用缓冲区输出,那么将会每次一个字节向外输出。缓冲区一般是一个数组,将需要输出的内容先保存在缓冲区内,然后再一次性将缓冲区的所有内容向外输出。就可以减少系统操作的次数,从而提高效率。
用于配置缓冲区,默认值为空。
配置这个参数分为两种情况:以文本方式打开,以二进制方式打开。
- 以文本方式打开,可以传入参数1,代表每次缓冲一行;或者传入大于1的数字(仅在文本模式下支持),代表固定缓冲区大小(我猜是固定字符,比如传参为2缓冲区就是2个字符大小)
- 以二进制方式打开,如果要关闭缓冲区就传入参数0,或者传入大于1的数字。一般长度是
4096 or 8192(注释里建议的)
encoding参数
用于配置编码参数,这个参数就可以解决上面的乱码问题了。
如果发生乱码的情况,问题大概率处在解码的方式与储存的方式不一致。
一般Windows的默认解码方式为GBK,咱们来试试。
readFile = open('test.txt', encoding='GBK') # 这里的mode参数应该是默认的'rt'
print(readFile.read())
readFile.close()
果然,设置了解码方式后,输出的结果与之前的乱码一致。

现在将解码方式改为正确的方式,打开文本文件,发现存储时使用的解码方式为UTF-8,OK修改参数。
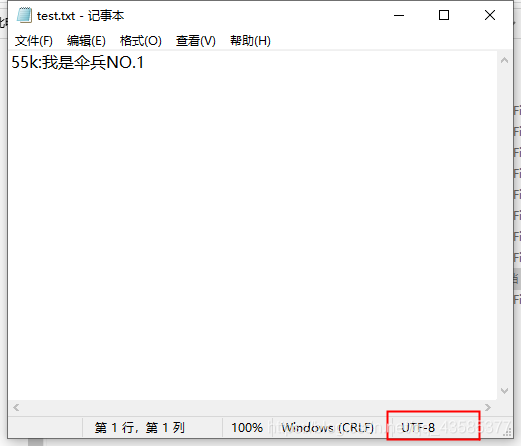
readFile = open('test.txt', encoding='UTF-8') # 这里的mode参数应该是默认的'rt'
print(readFile.read())
readFile.close()
OK,可以正确解码了。

errors参数
用来配置出现解码错误时的处理方案。(不适用于二进制方式)
一共有两个参数可选:
- 传递
strict参数会引发ValueError异常 - 传递
ignore以忽略错误。 (请注意,忽略编码错误可能会导致数据丢失。)
newline参数
用于控制换行符的工作方式(仅适用于文本模式)
closefd参数
没太明白,直接贴出来吧
If closefd is False, the underlying file descriptor will be kept open
when the file is closed. This does not work when a file name is given
and must be True in that case.

















 2379
2379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









