







遏制在线仇恨言论已成为当务之急;然而,由于一些地理政治和文化原因,全面禁止此类活动是不可行的。为了降低问题的严重性,在本文中,引入了一项新任务,即仇恨言论正常化,旨在削弱在线帖子所表现出的仇恨强度。作者手动策划了一个平行语料库 - 仇恨文本及其规范化对应物(弱化评论中的仇恨,转变为更积极的,评论不会删除的评论)。作者介绍了一种简单而有效的仇恨言论规范化模型NACL,分三个阶段运行。首先,它测量原始样本的仇恨强度;其次,仇恨跨度识别(一个句子当中负责传达仇恨的部分);最后,降低仇恨强度。
前言
仇恨言论攻击往往针对宗教、族裔、国籍、种族、肤色、世系、性别或其他身份因素。 作者的实验旨在捕捉不同程度和设计的仇恨; 把仇恨作为一个总括术语,包括仇恨、虐待和冒犯的重叠定义。
提示:以下是本篇文章正文内容,下面案例可供参考
一、相关工作
1.禁言 封号
社交媒体上的仇恨言论通常包括违反平台使用条款的内容,并导致内容被标记或被禁言的用户,或两者兼而有之。 这导致大量被禁用户转向限制较少的平台。研究表明对恶意用户的跨平台研究揭示了禁止用户对平台和整个互联网社区的适得其反
2.改进社交媒体规则
对在线用户进行系统和积极的宣传可以帮助他们在不直接传播伤害的情况下表达自己的观点。比如:Twitter 和 Instagram等平台都提供了评论修改功能让用户把评论修改符合平台要求后再发布出去。实验结果表明:促使参与者最终比对照组中没有提示的用户发布更少的攻击性推文。 这种轻推应该比他们在没有机会改进的情况下被禁止进入平台更受欢迎。
只是一味地禁言或者封号,又或者完全禁止发表仇恨言论的是不可取的,研究表明,这样做适得其反。
二、实验
1.本文的贡献
1)提出了仇恨言论规范化的新任务。通过削弱原始内容所表现出的整体仇恨,同时保留原始的语义,提出了一种规范化的仇恨内容对应物。
2)手工整理了一个新的数据集。本文并不是把仇恨变为非仇恨,而是降低仇恨的强度,所以手工整理了一个仇恨以及对应规范物的语料库。 (一个句子只有几个单词短语传达了很点多的仇恨,所以首先确定仇恨跨度,然后将其归一化,减少整体仇恨。)
3)提出了NACL。NACL一共分为三步。第一,使用BiLSTM回归模型来测量输入的仇恨强度;第二,BiLSTM-CRF模块从原样本中提取仇恨跨度,第三,通过仇恨预测识别模块的反馈,合并微调基于BART的seq2seq模型来规范化识别的仇恨跨度。
4)评价以及部署。通过三个评估和六个基线比较。通过三向评估(内在、外在和人体研究)来衡量 NACL 的功效。 观察到 NACL 的性能优于六个基线 - NACL 在强度预测中得分为 0.1365 RMSE,在跨度识别中产生 0.622 F1 分数,在标准化文本生成中产生 82.27 BLEU 和 80.05 困惑度。我们进一步展示了NACL在其他平台(Reddit,Facebook,Gab)上的可推广性。NACL的交互式原型被放在一起用于用户研究。此外,该工具正在Wipro AI的现实环境中部署,作为其解决在线平台上有害内容的使命的一部分。
2.实验过程
训练一个用户参与预测模型(在Reddit数据集上训练)。 用它来预测数据集中的仇恨帖子和它们的标准化对应物的评论数量。 使用仇恨的和规范化的样本作为控制和交替集。每个抽样迭代中值注释计数的差异如图所示。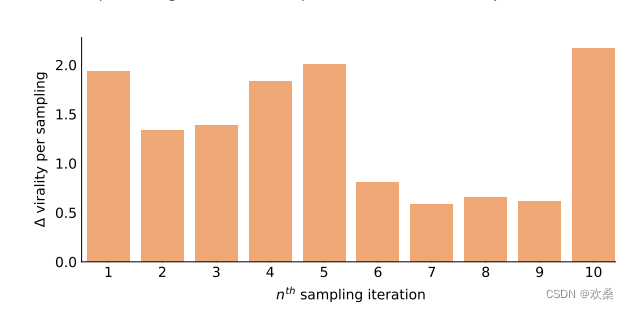
给定一个仇恨样本,目标是得到其归一化的版本。实验一共分为三个阶段。
1)仇恨识别(HIP) 。仇恨等级分为1到10。
2)仇恨跨度判定(HSI)。 一个样本可以有多个不重叠的仇恨跨度,HSI旨在找到所有这样的跨度。
3)降低仇恨(HIR)。 目的是找到符合原文,但是仇恨强度降低的对应句子。
3.NACL模型
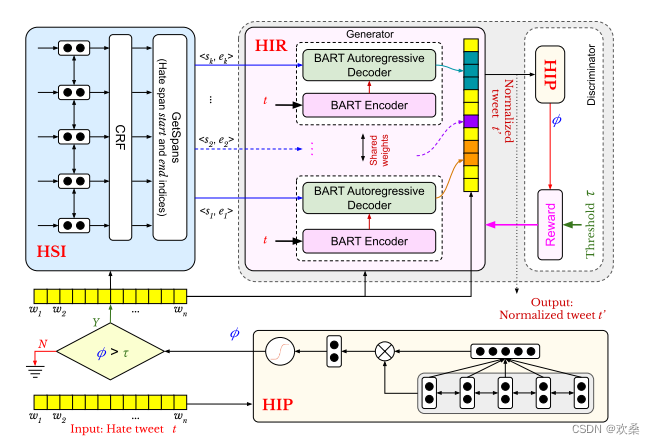
NaCl-HIP模块:采用了BI-LSTM模型。 然后将中间表示通过连接到具有线性激活的全连接层的自注意力层,以获得输入样本的连续仇恨强度预测。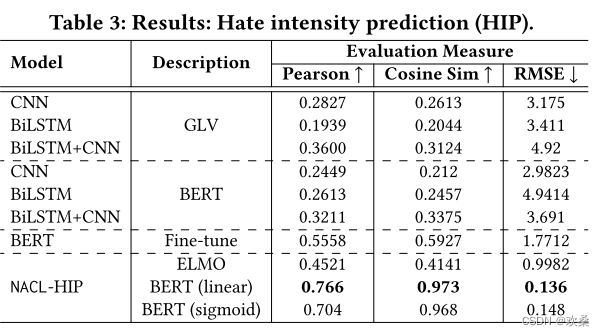
NaCl-HSI模块:使用双向LSTM来捕获序列的上下文表示。“b”表示仇恨跨度的开始,“i”表示仇恨跨度的继续,“o”表示nonhate标记。 然后,隐藏的表示通过一个时间分布的密集层来平坦嵌入结构。 我们进一步使用CRF模型层来适应我们的表示,并为我们的序列生成所需的标记。
NaCl-HIR模块:使用基于生成对抗网络(GAN)的体系结构,采用NaCl-HIP和NaCl-HSI作为辅助模块。 NACLHIR接受一个仇恨的样本,以及由HSI模型识别的span标签。对于NaCl-HIR,我们使用一个预先训练的BART并微调它用于仇恨规范化任务。 生成的跨度与样本的其余部分合并,并转发到基于HIP的鉴别器模型。
计算出的仇恨强度分数小于或等于阈值,则正向奖励鼓励生成器继续预测相似的归一化跨度; 否则,负奖励惩罚生成器以提高其预测。
数据集设置
总共收集了4423个仇恨样本,并用仇恨强度分数和仇恨跨度来注释它们。 其中,1396个样本要么是隐性的(没有明显的仇恨跨度),要么表现出低于阈值的仇恨强度。 因此,最终的精选数据集包括3027个平行的仇恨和归一化样本,以及原始样本的强度分数和仇恨跨度。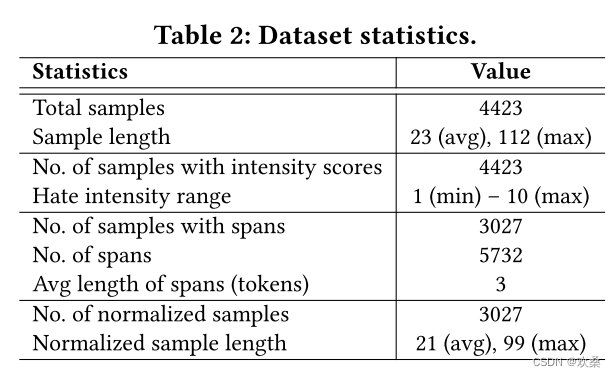
评估方法
**1)内在的评估。**衡量模型的性能由传统的评估指标。
2)人工评估。要求人工注释者对生成的输出(来自我们的模型和生成基线)的质量进行评级。
**3)外部评估。**使用最先进的仇恨言论检测模型来区分原始和归一化的仇恨样本,以进行外部评估
总结
存在的两个挑战:
1)缺乏平行数据来训练更复杂的生成模型。
2)样本中存在隐性仇恨。
第一个问题可以通过注释更多的样本来解决(代价昂贵),但处理隐含的仇恨是很麻烦的。在本篇论文中,由于没有明确的仇恨跨度,忽略了隐含的仇恨样本。在未来,我们将投入严格的努力来处理这些情况,并增加数据集的大小。 此外,NACL也可以用于非英语文本。














 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









