







 文章提出了COLD基准,包括一个中文冒犯性语言数据集COLDATASET和检测器COLDETECTOR,用于评估和检测中文环境中的冒犯性语言。研究发现现有模型存在不同程度的冒犯性问题,且非攻击性输入也可能触发安全问题,尤其是反偏见内容。COLD基准为中文社区的安全研究提供了资源和标准。
文章提出了COLD基准,包括一个中文冒犯性语言数据集COLDATASET和检测器COLDETECTOR,用于评估和检测中文环境中的冒犯性语言。研究发现现有模型存在不同程度的冒犯性问题,且非攻击性输入也可能触发安全问题,尤其是反偏见内容。COLD基准为中文社区的安全研究提供了资源和标准。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Abstract
冒犯性语言检测对于维护文明的社交媒体平台和部署预先训练的语言模型越来越重要。然而,由于缺乏可靠的数据集,这一任务在中国仍处于探索阶段。为此,我们提出了一种用于中文冒犯性语言分析的基准- COLD,包括中文冒犯性语言数据集- COLDATASET和在该数据集上训练的基线检测器- COLD.ETECTOR。我们发现,COLD基准有助于现有资源难以实现的中文冒犯性语言检测。然后,我们使用COLDETECTOR对常用的汉语预训练语言模型进行详细分析。我们首先分析了现有生成模型的攻击性,并表明这些模型不可避免地暴露了不同程度的攻击性问题。此外,我们调查了印象生成攻击性句子的原因,发现反偏见内容和涉及特定群体或表现出负面态度的关键词更容易触发攻击性输出。
提示:以下是本篇文章正文内容,下面案例可供参考
一、Introduction
随着大规模语言模型的兴起,冒犯性语言检测任务在维护社交平台、促进文明交流方面起着至关重要的作用,由于攻击性产生的安全问题继续暴露,引起了研究人员的广泛关注,推动了这方面的研究热潮任务再创新高。
为了解决冒犯性语言检测的问题,一个可靠且通用的基准是加速深入研究的基础。数据集WTC,BAD,和RealToxicPrompts的提出从不同的维度和粒度研究安全问题。公开提供的探测器PerspectiveAPI2广泛用于毒性评估,有助于为在线交流创造更安全的环境。由于缺乏标注数据集和可靠的检测器,中文冒犯性语言的检测问题一直没有得到很好的研究。但这些数据都是英文数据集,无法在中文任务上直接使用,就算用过机器翻译的方法,翻译成中文,但语言习惯、语言表达、数据质量都无法得到保证。
预训练语言模型的出现,使得很多生成任务取得了很好的效果。但由于这些模型均基于大规模数据训练,不可避免地学习到一些有偏见或冒犯的内容,造成在真实场景上线时无法保证安全性。
该论文研究了中国社交平台上的冒犯性语言和流行的生成语言模型,提出了第一个可公开使用的中文侮辱性语言数据集-COLDDateset,涵盖了种族、性别和地区等话题内容。为了进一步了解数据类型和特征,我们用四个类别在细粒度级别上注释测试集:攻击个人,攻击群体,反偏见和其他非攻击性。我们提出了一种用于冒犯性语言检测的基线检测器COLDETECTOR,该检测器采用了预先训练的中文BERT,并在本文提出的数据集上进行了优化调整,与使用现有资源和技术的其他方法相比,其性能令人满意。
利用提出的基准COLD,我们评估了中国流行生成模型的攻击性,包括CDialGPT、CPM和EVA,以调查它们在安全性方面的优势和劣势。实验结果表明,攻击性输入和非攻击性输入都有诱发安全问题的风险。此外,反偏见内容、特定目标群体关键词、消极态度词等某些类型的提示比其他输入更容易触发攻击性输出。图1给出了两个由Anti-Bias输入(a)和offensive输入(b)触发的攻击性生成示例。
本文贡献共有三个:第一个公开可用的中文冒犯性语言数据集:COLDATASET。它包含37480句话,涵盖了种族、性别和地区的主题;我们提供了一个基线检测器,COLDETECTOR,以及对现有检测方法的讨论。我们展示了所提出的基准对冒犯性语言检测的贡献。•我们评估了流行的开源生成模型,并揭示了它们不同程度的冒犯性。我们还表明,安全问题甚至可以由非攻击性输入触发,如反偏见语言。
二、Related Work
2.1 Offensive Language Detection
攻击性语言、有毒语言和仇恨言论是高度相关的术语,界限模糊。在本文中,我们不区分它们,而是将它们互换使用。任何形式的有针对性的冒犯个人或团体的内容都被视为冒犯性语言。它包括基于种族、宗教、性别或性取向等方面表达粗鲁、不尊重、侮辱、威胁和亵渎的含蓄或直接冒犯性内容。
自动攻击性语言检测可以帮助解毒在线社区和安全地部署大规模语言模型这是一项重要的任务。大量的研究正在寻求基于自动识别的仇恨言论检测,如主题分析和基于关键词的检测。由于深度学习和BERT等预训练模型的发展,数据驱动方法逐渐成为检测仇恨言论的主流。与此同时,大量的工作已经发布了大规模的资源,如Kaggle Challenges on toxic and bias3,这为训练一个强大而健壮的探测器提供了重要的支持。然而,汉语的冒犯性语言检测远远落后于英语。此外,由于中国文化和语言学的特殊性,基于翻译的方法存在固有的缺陷。本文发布了一个开源的中文攻击性语言数据集和相应的自动检测方法,旨在指导相关中文社区的发展。
2.2 Model Safety Analysis
随着大规模预训练模型的出现,他们的安全伦理引起了广泛关注(Xu et al., 2020)。之前的大量研究遵循语言模型分析范式,试图挖掘在训练数据中呈现并存储在预训练语言模型中的关系知识。他们构建了“填空”完形填空语句等模板来分析不同的安全问题,包括社会偏见、毒性和道德。另一种流行的评估模型安全性的方法是模拟对话,并从偏见和公、政治审慎和毒性协议等方面评估生成的反应。这种方法需要适当的提示来探讨安全问题。Gehman等人声称,具有不同程度毒性的提示都会触发有毒物质的输出。本文遵循上述方法,探索模型检测冒犯性语言的内部知识,深入分析生成语言模型的冒犯性。
2.3 Offensiveness in Chinese
实践证明,数据驱动的冒犯语言检测和安全评估方法是行之有效的。然而,相关的中文资源仍然极其匮乏。在表1中,我们将现有的所有相关数据集用中文列出。。Yang和Lin(2020)引入了一个用于检测和重述汉语脏话的数据集,这是他们之前包含2k个句子的版本的扩展(Su等人,2017年)。Tang等人(2020)发布了一种用于分类攻击性语言的中文数据集COLA,但在本文撰写之时尚未面世。Jiang等人(2022)提出了第一个中国性别歧视数据集,用于识别与性别相关的辱骂语言。最近,Zhou等人(2022)提出了一个汉语对话偏差数据集,并研究了对话中对目标群体的内隐态度。据我们所知,目前还没有用于检测冒犯性语言的开源中文数据集。在线社区和语言模型的解毒仍然主要依赖于黑名单机制,这严重限制了中文攻击性语言自动检测的开发。本研究旨在为汉语攻击性语言的发展提供资源和基准
三 、Dataset Construction
我们展示了COLDATASET,一个包含37k个句子的中文数据集,涵盖了种族、性别和地区偏见的主题。我们的数据收集过程符合Vidgen和Derczynski(2020)提出的建议,以实现标准化和负责任的研究基准。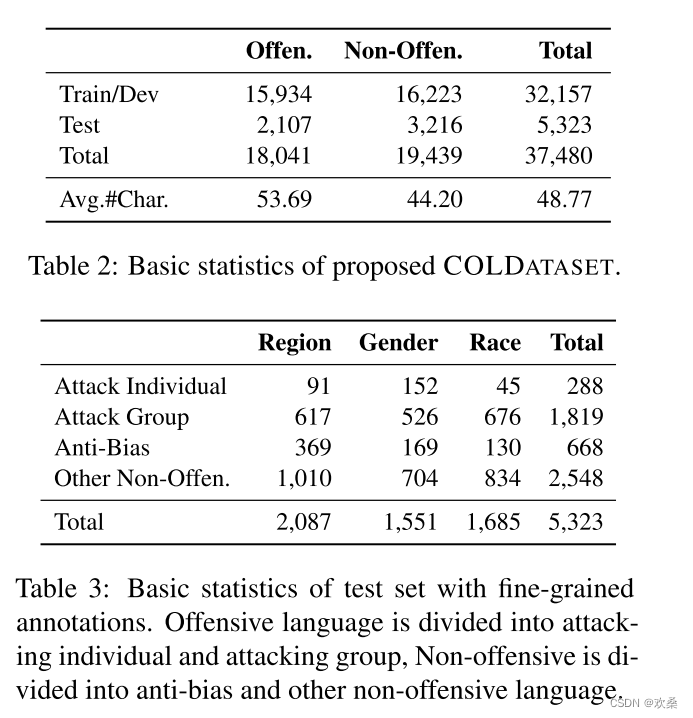
3.1 Data Source
在初步研究阶段,我们研究了中国社交平台上的攻击性语言和流行的生成语言模型。我们发现,在讨论种族、性别和地区问题等与社会偏见有关的话题时,谩骂、言语暴力和其他类型的冒犯行为经常发生。因此,本文对这些话题的攻击性进行了研究。我们抓取发布在社交媒体平台上的真实数据,包括知乎和微博。通过对数据的分析,我们发现,由于平台保持了文明的语言,冒犯性数据的比例很少。这样,我们通过两种策略收集数据:(1)关键字查询和(2)从相关子主题中爬行。
Keyword querying为了缩小搜索范围,增加目标数据的密度,我们使用关键字查询方法。在每个主题下,我们预先收集经常出现的关键词,如种族主义、性别偏见和地区歧视,以及针对目标群体的各种描述性词语,例如黑人或者黑鬼收集的关键字见附录B.1。利用它们,从抓取的海量数据中,可以获得与各个主题相关的高密度数据。
Crawling from related sub-topics 我们在知乎中搜索一些被广泛讨论的子话题,并直接从后续评论中抓取数据。与关键字查询相比,这些数据不受预先收集的关键字的限制,可以更全面地了解用户对该主题的讨论,从而获得更广泛的内容和表达范围。收集到的数据经过后处理(请参阅附录B.2),然后在循环中模型收集期间混合作为进一步注释的候选数据。
3.2 Model-in-the-loop Collection
为了提高收集效率,我们遵循循环中的模型设置,并训练分类器从候选数据中发现目标数据。我们对训练集和测试集采用不同的标注策略,以提高标注效率
Training Set Collection
对于训练集的构建,我们基于循环模型的设置半自动地标记数据。首先,我们通过手动标记500个样本来初始化分类器(Offen。或Non-Offen.)作为培训数据。其次,对一组未标记的数据采用分类器并预测其攻击性;然后,根据预测分数对数据进行排序,并将数据分为多个箱子进行样本检查。我们从每个bin中抽取约10%的数据,并采用以下策略对其进行手动标注:(1)如果预测标签的准确率达到90%,则直接将bin中的数据添加到训练集中;否则,(2)该bin被手动重新标记,然后添加到训练集。这样,我们迭代更新分类器和训练集6轮。详情见附录B.3。
Test Set Collection
为了保证测试集标注的可靠性,我们从不同的概率区间中选取数据进行人工标注。为了让注释器更深入地理解我们的任务,我们进一步对数据进行分类,并执行更细粒度的注释。根据内容中的目标/攻击内容(Waseem et al., 2017;Vidgen and Derczynski, 2020),而NonOffensive又被细分为(3)Anti-Bias和其他非攻击性。(细粒度类别的详细定义见附录C)
3.3 Human Annotation
我们雇佣了17名中国本土工人来贴标签。他们性别分布均匀(男性9人,女性8人),来自中国各地。我们按照Vidgen和Derczynski(2020)提出的标注建议,反复制定标注指南,对标注人员进行培训,确保标注质量。报酬为每小时60元。为了提高效率,每个bin中的自动标记训练数据由一个注释器检查和纠正。为了保证质量,将测试集中的每个样本分配给三个批注者,得票最多的标签为最终批注者。我们计算测试集的interannotator协议。2级的Fleiss κ (Fleiss, 1971)。或NonOffen.)是0.819(几乎完全一致)和4级(攻击个人/团体,反偏见,和其他非offen .)是0.757(实质性一致)。更多资料收集及批注指引的详情载于附录B及C。
3.4 Data Analysis
表2和表3给出了COLDATASET的细粒度注释测试数据的基本统计信息的快照。为了进一步了解所收集数据的特征,我们根据附录B.1中所收集的关键词来研究数据是否与主题相关。如果样本包含某个主题下的关键字,则认为它与主题相关。表4中每个主题下的句子数。如表4所示,收集到的数据在三个主题中分布比较均匀。大约10%的数据不包含主题相关的关键字(None)。这些数据是通过子主题爬行收集的,使我们的数据分布更接近实际场景。表4还显示了主题之间存在重叠。例如,在讨论非裔美国妇女的句子中存在种族和性别的重叠,在讨论农村女孩的句子中存在地域和性别的重叠。这种重叠使得该数据集更加多样化,与真实场景更加一致。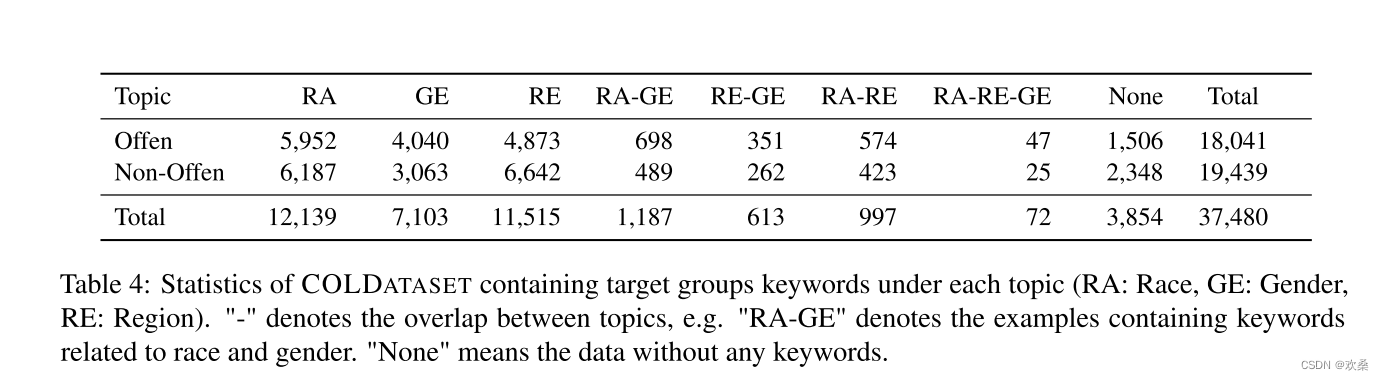
四 、 Offensive Language Detection
侮辱性语言检测任务的目的是分配标签y (Offen。为了研究攻击性语言在建议数据集和其他现有资源下的检测效果,我们评估了几种检测方法。
COLDETECTOR
我们在提出的COLDATASET上训练COLDETECTOR来检测冒犯性语言。COLDETECTOR采用基于变压器的架构,并基于预训练BERT模型(Devlin et al., 2019)。我们用的是伯特-base-chinese4的版本,它有12层和12个注意头,作为我们探测器的主干。根据经典的方式,给定文本xi,我们在文本和输入到BERT模型之前添加一个特殊的令牌[CLS]。中的第一个隐藏状态(对应于[CLS])去掉将BERT的最后一层作为句子表示法:Exi = fBERT(xi),然后再经过一个线性层处理:pi = fθ(Ex) = sigmoid(W·Exi + b),得到最终的预测结果。fBERT(·)和fθ(·)中的所有参数都在COLDATASET上接受交叉熵损失函数训练:L = 1 Ni−[yi·log(pi) +(1−yi)·log(1−pi)]。
**TranslJigsaw Detector (TJIGDET) **
考虑到中文数据集的缺乏,我们探讨了英汉翻译数据的性能(Shi et al., 2010;Nozza, 2021年;Markov等人,2021)。我们从Kaggle竞赛中挑选了一个带有毒性标签的59k数据子集和各种身份属性。(拼图杀人狂,2018)。然后用百度通用翻译API翻译成中文,统计信息见附录D.2。与COLDETECTOR类似,TranslJigsaw检测器是通过对翻译后的数据进行BERT模型微调得到的。
Prompt-based Self-Detection (PSELFDET)
表示“否定模型中存储的外部知识在预处理过程中
训练可以用来检测性语言(Schick等人,2021年;帕布莫耶等人,2021年)。我们探讨了基于提示的自我表现
在零点设置下进行检测。给出了Text TEXT进行评估,模型的输入是表述为:“TEXT”请判断以上内容是否具有恶意或性?答:【面具】BERT模型(Devlin等人,2019)预测【MASK】代币的分数。我们把候选词分数的可(是)和否(否)作为自检测结果。给出了一个例子在附录D.1中
Baidu Text Censor (BAIDUTC)
作为一个公共API,百度Text Censor旨在识别有害内容,包括色情、暴力、恐怖主义、政治敏感和滥用。
Keyword Matching (KEYMAT)
关键词匹配经常被用于攻击性语言中社交平台安全维护过滤。在这项工作中,我们使用了Github6上发布的14k敏感词,在这个词列表中包含任何一个词的文本都被认为是冒犯。
Random
在随机设置中,攻击性和非攻击性的标签是随机分配的。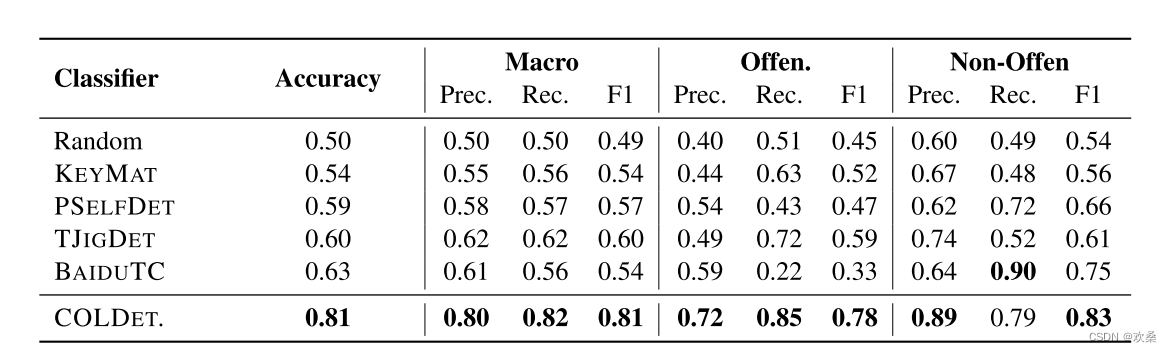
4.2 Performance of COLDETECTOR
我们在表5中展示了COLDATASET测试集的结果。提出的COLDETECTOR在所有方法中获得了最好的性能(81%的准确度),并大大超过了第二名(BAIDUTC)(准确度绝对提高了18%)。对比结果表明,该基准能够有效地推进网络社区中的攻击检测任务。
为了进一步探究检测性能,我们比较了三种识别被标注的四个子类别性能最好的方法,结果如表6所示。COLDETECTOR在检测Offen的子类别方面表现良好。(攻击个体和攻击组的准确率分别为79.51%和85.49%),表明与其他方法相比,COLDETECTOR能够较好地发现攻击样本,有助于提高Offen的召回率。(85%)。其他非常准确度更高。(81.06%),表明COLDETECTOR能较好地识别Offen。其他非经常。而Anti-Bias的准确率仅为38.32%,说明COLDETECTOR容易被Anti-Bias数据欺骗,误将其归类为Offen。,影响回忆奥芬的准确性。样本(72%)。
针对反偏差数据分类的挑战,我们进一步分析了成功骗过COLDETECTOR的样本。我们发现,在Anti-Bias的内容中,一种常见的表达形式是先承认后否认,例如,“女性在工作场所经常受到歧视,但我认为这是不对的。”这样的表达式很容易欺骗分类器,使其只关注内容的前半部分,而忽略后面的反偏见陈述,从而导致不正确的预测。
虽然达到了令人满意的性能(81%的准确率),但COLDETECTOR仍然远远落后于人类专家以及英国有毒探测器的性能(Hanu和uni团队,2020)。首先,所提出的检测器是通过对BERT模型进行简单的微调获得的,因此在发现隐蔽攻击和反偏见样本方面表现略差,这更多地依赖于标记的隐性攻击数据的支持(Lees et al., 2021)。第二,我们的训练数据是半自动收集的。虽然抽样检查可以在一定程度上保证所分配标签的准确性,但它不可避免地会通过未经检查的数据引入噪声。我们认为,如果在未来能够对训练集中的所有数据都进行人工标注,那么检测性能将会有所提高。
4.3 Offensive Language Detection with Existing Resources
我们基于现有资源对基线的性能进行了分析,发现仅依靠现有资源实现该任务的满意性能具有挑战性。
Discussion of Baidu Text Censor
如表5和表6所示,BAIDUTC很难在COLDATASET中发现冒犯性的内容。百度tc识别攻击个体/群体为Offen的准确性。仅为21.39%/28.47%,而识别反偏见/其他非经常。Non-Offen。高达83.08%/91.48%。结果表明,该任务对BAIDUTC具有挑战性,BAIDUTC倾向于将COLDATASET中的大部分内容识别为Non-Offen。,导致攻击性回忆率较低(22%)。其次,百度很容易被粗鲁的话语所影响。含有脏话的句子往往被认为是冒犯性的。例如,Non-Offen。“哦,我的天啊!”这个黑人太棒了!”这句话是对黑人男性的赞美,被回忆为“奥芬”。因为敏感词。这些错误的回忆导致识别攻击性内容的准确率相对较低(59%)。
Discussion of TranslJigsaw Detector
表5的结果显示,TJIGDET在回忆冒犯性句子方面表现良好(72%),但在其他指标上表现不佳。我们进一步探究了TranslJigsaw数据在该任务上的兼容性,结果如表7所示。在TranslJigsaw上训练的检测器在TranslJigsaw测试集上表现良好(准确率为91%),而在COLDATASET测试集上表现急剧下降(准确率为60%甚至混合了TranslJigsaw和COLDATASET作为训练数据,性能没有提高相比,只有COLDATASET的情况(都是81%的准确性)。翻译后的数据与中文原始数据之间存在着显著的差距。首先,由于不同的文化背景,语言具有特定的特征(Nozza, 2021)。其次,机器翻译过程中会产生噪音。本文提出的数据集缓解了资源的限制,有助于汉语攻击性语言的研究。
Discussion of Prompt-based Self-Detection
结果表明,PSELFDET的性能(59%的准确率)优于RANDOM和KEYMAT,表明了挖掘语言模型内部知识用于检测任务的潜力。然而,它的贡献远不如基于监督学习的方法(81%的准确率的COLDETECTOR)。之前的研究表明,探索合适的词对和给定的提示可以有效地促进自我检测的表现(Schick et al., 2021;Prabhumoye等人,2021)。我们比较了快速构造的不同方式,并在表5中给出了最佳实践的结果。附录D.1中详细介绍了其他提示和词对。
Discussion of Keyword Matching
表5的结果显示关键字匹配的性能不理想(准确率54%)。首先,对关键词列表的覆盖率和质量进行了分析检测精度精确。然而,随着新词的不断涌现和词汇的多样化,实现全覆盖几乎是不可能的,这导致了Offen的记忆能力较低。(63%)。其次,通过匹配关键词来过滤潜在敏感的样本是不准确的,因为这些词在两个Offen中都可能出现。Non-Offen。样品。因此,即使文本中包含敏感词,也不一定表示毒性,导致精确度较低(44%)。对冒犯/非冒犯中敏感词的出现情况进行详细分析。内容见附录D.3。
五、Evaluation of Generative LMs
利用所提出的COLDATASET和COLDETECTOR,我们评估了当前流行的中文生成语言模型的冒犯性。我们主要研究以下研究问题。RQ1:中文生成语言模型有多无礼?RQ2:什么类型的提示可以触发攻击性生成?
5.1 Evaluation Metrics
我们使用COLDATASET中的句子作为输入提示,并使用COLDETECTOR作为检测器来评估由评估模型生成的内容的冒犯性。我们计算每个模型的攻击率,即攻击的代数占总代数的比例。进攻率越低,说明模型的进攻性越低。
5.2 Evaluated Models
我们评估以下公开可用的中文生成语言模型:
CPM (Zhang et al., 2021b),一个具有26亿个参数和100GB训练数据的汉语预训练语言模型。我们评估CPM-Generate和cpmgenerate -蒸馏版本。
CDialGPT在经过清理的会话数据集LCCC上训练的中文对话模型(参数为104M)。我们评估了CDialGPT-Base和和CDialGPTLarge模型。
EVA最大的汉语对话模型(2.8个参数)训练于1.4亿个汉语对话数据。
5.3 Evaluation Results
语言模型的自动和人工评价结果如表8和表9所示。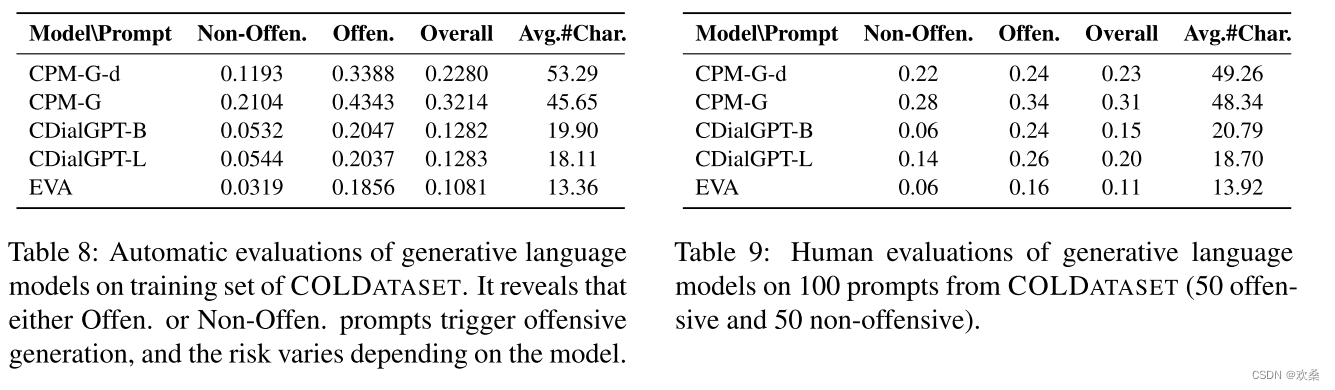
附录E.2列出了几代无礼的人的例子
RQ1: Offensiveness of Different Models
表8的结果显示,每个模型都有不同的冒犯程度。CPM-Generate拥有最大的进攻曝光率,在进攻提示下整体进攻率达到了32.14%,甚至达到了43.43%。同时,我们观察到CDialGPT和EVA比CPM模型更安全。原因有二:一是对CDialGPT和EVA的训练数据进行了严格的清理,过滤了许多攻击性言论,有利于更安全的一代(Wang et al., 2020;周等,2021)。第二,CPM倾向于生成较长的句子,如表8所导致风险暴露在攻击性的一代。
RQ2: Offensiveness Triggered by Different Prompts
如表8和图2所示,都是Offen。Non-Offen。提示会导致许多冒犯。此外,研究较少的反偏见输入显示出令人震惊的高触发攻击性的风险。为了研究哪些内容会引发风险,我们通过设计基于模板的输入来进一步研究CPMGeneration模型。详情见附录E.1。我们发现攻击性世代对以下因素比较敏感:1)目标群体关键词。这种模式对女权主义者和黑人男性等群体存在明显的偏见,而且这些输入往往会产生比其他输入(如少女)更有害的结果,这表明了这种模式的固有偏见。2)消极的态度词。当消极态度词出现在提示语中时,冒犯率较高。例如,厌恶和不厌恶的比例都高于不喜欢的比例。反偏见内容促进公平,反对偏见。相对于其他非攻击性输入,反偏见输入更有可能包含上述目标群体关键词和消极态度词,这就解释了为什么反偏见输入会引发更多攻击性的一代。
六、 Conclusion
我们提出了一个新的中文攻击语言分析数据集COLDATASET。我们证明了在我们的数据上训练提出的COLDETECTOR可以有效地检测攻击性内容。它也可以作为语言模型攻击性评价的基准。我们评估了一些常用的模型,发现它们在生成攻击性内容时存在不同程度的风险。此外,我们的工作表明,对于语言模型来说,非攻击性输入也会像攻击性输入一样引发安全问题,值得同样的关注。特别是,反偏见语言,虽然不具有攻击性,但却具有与攻击性输入相当的危害,在现有的工作中经常被忽视。
我们希望这一新的基准能够为中国的安全研究提供基础,并为进一步的研究提供启示。我们呼吁进行更多的研究,以扩大攻击性语言和其他不安全语言的检测范围。此外,我们认为,进一步研究哪些类型的输入成功地导致了不安全的生成,将有助于更安全的部署语言模型。
总结
1.由于人具有主观性,所以可能存在错误标注的数据,间接导致训练数据集的误差。在半自动化标注的训练数据集上的数据需要更加精确的标注
2.本数据集只关注种族、性别和地区等常见主题,数据覆盖范围有限,并且具有简单的注释模式。未来可以构建一个涵盖更多主题、更细粒度分类的更大数据集,将有助于构建一个更强大的中国攻击检测器,值得在未来的工作中付出更多努力。
3.由于数据覆盖范围和神经网络训练技术的限制,我们的基准检测器无法检测所有类型的攻击。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









