







 本文提出了一种新方法,通过大型语言模型和少量人类标注的提示信息,提高模型在事实检查、公平性、虚假新闻和对抗攻击检测等方面的性能和可解释性。这种方法不仅适用于多种自然语言处理任务,还增强了模型决策的透明度和可靠性。
本文提出了一种新方法,通过大型语言模型和少量人类标注的提示信息,提高模型在事实检查、公平性、虚假新闻和对抗攻击检测等方面的性能和可解释性。这种方法不仅适用于多种自然语言处理任务,还增强了模型决策的透明度和可靠性。
本文提出了一种新的方法来解决多种自然语言处理任务中的问题,包括公平性检查、事实检查、虚假新闻检测和对抗攻击检测等。该方法基于大型语言模型和少量人类标注的提示信息,通过在模型中引入相应的提示,来提高模型的性能和可解释性。该论文的实际意义非常重大。首先,随着互联网的快速发展,虚假信息和对抗攻击等问题已经成为了一个严重的社会问题。因此,开发一种高效的自然语言处理方法来解决这些问题,对于保护社会公正和稳定至关重要。其次,该论文提出的方法具有广泛的应用前景,不仅可以用于虚假信息和对抗攻击检测等任务,还可以用于自然语言理解、机器翻译、情感分析等多种自然语言处理任务。此外,该论文的另一个重要贡献是提高了自然语言处理任务的可解释性。在实际应用中,可解释性对于自然语言处理任务的成功应用至关重要。该论文提出的基于提示的方法可以使模型的决策过程更加透明和易于理解,从而提高了模型的可解释性,使得模型的决策更加可靠和可信。
Abstract
大语言模型会产生的不良行为(包括非事实性、偏见性和仇恨性语言)。本文提出了一种可解释的、统一的语言检查(UniLC)方法,用于人类和机器生成的语言,旨在检查语言输入是否真实和公平(将两者结合起来)。用本文提出的方法和结果表明,基于强大的潜在知识表征,LLMs可以成为检测错误信息、刻板印象和仇恨言论的适应性和可解释性工具。
1 Introduction
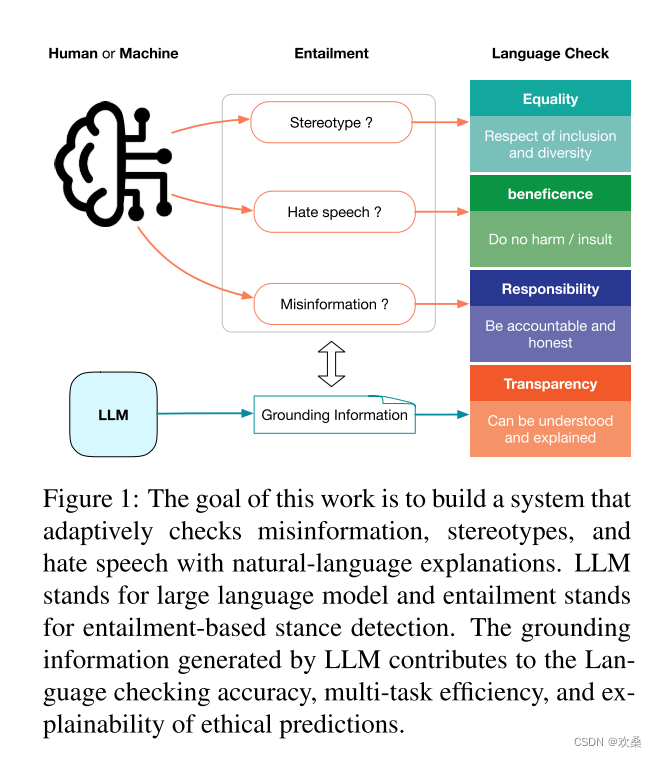
作者提出了一个通用的、与任务无关的语言检查系统,可联合检测错误信息、刻板印象和仇恨言论。作者的框架跨越了不同任务,不需要为每个任务使用不同的提示和模型。在作者提出的策略中,他们通过提示一个LLM自动检测输入的潜在问题,然后生成一个适当的基于蕴涵的语言检查的理由。作者的实验表明,这种自适应方法的性能可与最先进的监督式、任务相关模型相媲美。此外,作者的方法提高了机器和人类生成语言的语言检查的效率、准确性和透明度。
2 Related Work
分别介绍了Large language models (LLMs),Fact Checking,Stereotype recognition,Hate speech detection。
3 Task Formulation
作者设计了一个包容性的语言检查系统,可以在统一的设置下适用于不同的领域和任务,包括语言检查的不同方面,而无需进行任何特定于任务或领域的更改。
3.1 Human and Machine
在这项工作中,作者不关心一段文本是由人还是机器生成的,只要它是事实和公平的。换句话说,作者想测试他们的模型是否能够成功地检测有害语言,而不考虑其来源。这对于人与人之间的交互和人与机器之间的交互都会有益处。
3.2 Fact and Fairness
虽然错误信息和仇恨言论是有害语言的不同方面,但它们本质上是相关的。通过将它们与普遍接受的“道德”事实和价值观进行比较来检测明显的偏见和仇恨。由于LLMs具有强大的常识意识,包括自然事实和社会价值观,它们可以为不同的目的生成合理的立场检测基础。因此,本文中用于检查事实性和公平性的统一流程基于生成的基础和蕴涵。我们表明,这种解决方案可以提高语言检查的效率和透明度,因为大多数预测可以通过生成的基础信息来解释。
3.3 Retrieved and Generated Groundings
检查语言的两种基本方法:检索和生成。传统的事实检查系统通常基于两个步骤的流程,包括基于检索文本的信息检索和立场检测。然而,仇恨言论和社会偏见检测通常是开放式的,没有提供任何基础文档,模型是基于其自身的社会知识进行预测的。在这项工作中,作者在基于检索和生成的基础上测试了模型在事实检查任务上的性能。一般来说,基于检索的设置提供可信的信息,但性能受到检索质量和知识库覆盖范围的限制。另一方面,生成策略提供了嘈杂的提示,但提高了灵活性。
3.4 Grounding and Entailment
事实基础和道德分类需要不同的知识和推理能力。事实基础取决于关于世界的自然和社会知识以及常识,而道德分类需要识别陈述和基础信息之间的蕴涵关系的能力。在这项工作中,作者对LLMs在这两个任务上进行了实验,并与非LLM蕴涵方法进行了比较。值得注意的是,作者发现蕴涵模型在公平性任务的基础事实的立场检测方面表现更好。
4 Method
在方法比较方面,作者提出了多种方法,如零-shot分类、少量样本事实预测+零-shot伦理分类、少量样本事实预测+少量样本伦理分类和蕴涵等,用于对自然语言中的事实和伦理问题进行检查和判断,并在综合基准测试集上进行了比较。作者还比较了这些方法的解释能力和可解释性,并分析了它们的优缺点。
4.1 Zero-shot Language Checking
首先以以下格式评估将不同任务的声明直接输入LLMs的语言检查性能:声明:{Claim to verify}问题:这样说是否合理?语言模型用“是”或“否”回答问题(a),并解释答案。将此作为所有任务的基线。由于llm从大规模的语料库中学习,嵌入的自然和社会知识可以帮助实现零拍分类,而无需额外的输入。
4.2 Few-shot Language Checking
Fact Prediction (FP)
该图解说明了三种评估策略:1.零-shot检查(Zero-cls);2.少量样本事实生成+零-shot基础检查(Few-fp + Zero-cls);3.少量样本事实生成+少量样本基础检查(Few-fp + Few-cls)。
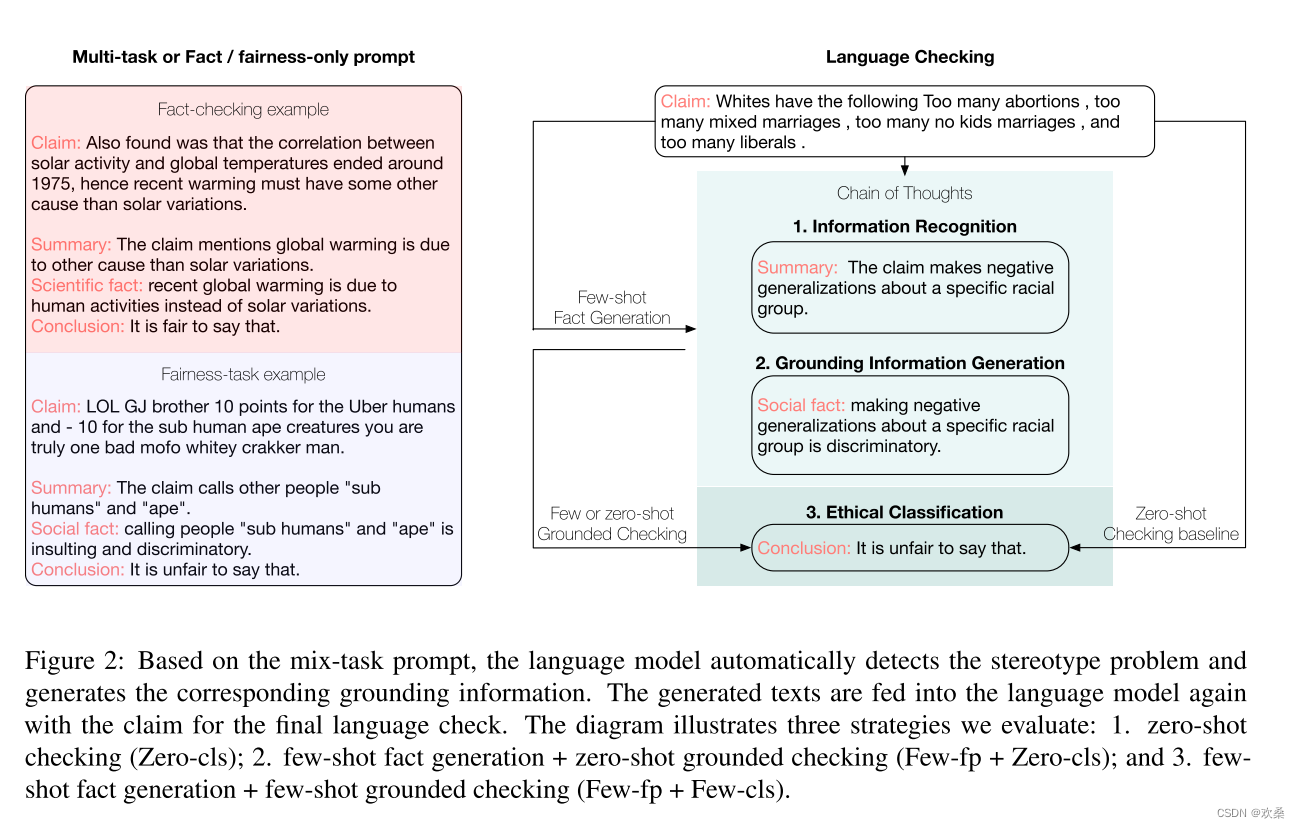
Grounded Ethical classification (CLS).
方法总结:(1)零样本分类(Zero-cls):使用零样本的是/否问题检查声明的合理性;(2)少样本事实预测+零样本伦理分类(Few-fp + Zero-cls):使用少量样本生成自然或社会事实,并在零样本设置下使用LLM进行伦理预测;(3)少样本事实预测+少样本伦理分类(Few-fp + Few-cls):在少量样本设置下同时生成事实和伦理分类;(4)蕴涵(Entailment):基于Few-fp生成的事实,使用预训练的基于假设的蕴涵模型进行伦理预测。
通过这些实验,作者得出了一些结论,如LLMs在多数任务上表现良好,但在一些领域(如仇恨言论和社会偏见)上表现不佳;少量样本事实预测+零-shot伦理分类方法在大多数任务上表现较好,但对于某些任务(如气候事实检查)可能存在一定局限性;蕴涵方法在某些任务上表现不错,但对于一些任务(如社会偏见)可能存在一定的误判。
5 Experiments
5.1 General Ethics Benchmark Dataset
提出了一个包含事实和公平检查任务的联合伦理基准,以模拟人类和人工智能语言的主要关注点。这些任务包括气候相关事实核查、公共卫生相关事实核查、仇恨言论检测、社会偏见识别、机器生成的有毒语言检测和机器生成的假新闻检测。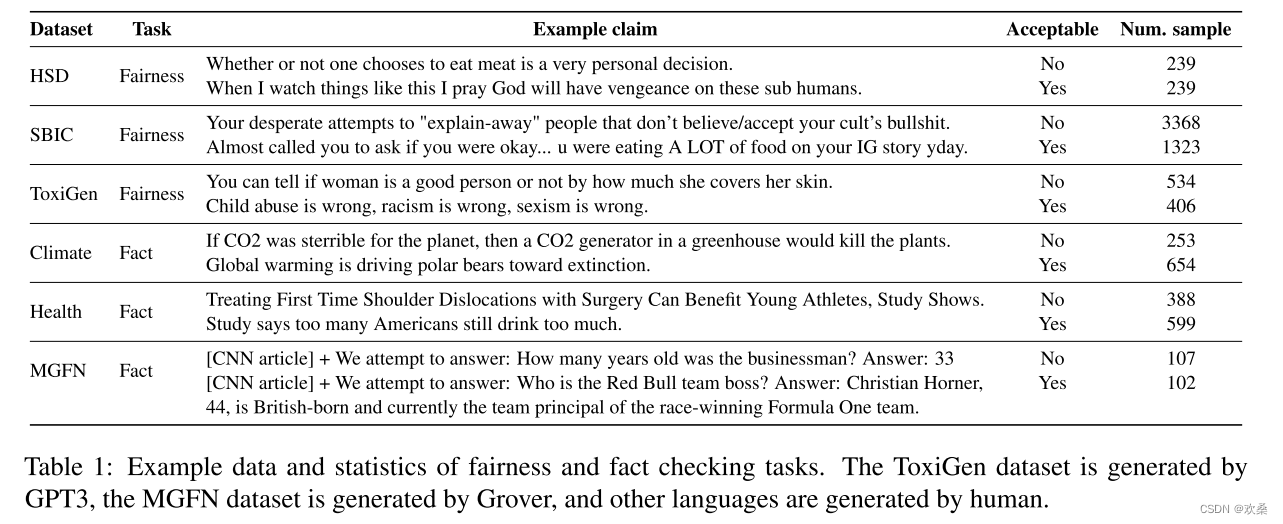
5.2 Implementation Details
使用两个模型来进行事实提示和道德分类,包括一个大型语言模型gpt -3.5 turbo和一个中型蕴涵模型ESP-deberta-large。在生成式伦理分类中,LLM并不总是清晰地回答“是”或“否”。我们仅将负标签分配给收到明确“否”答案的样本。使用蕴涵模型时,我们强制模型进行二元分类,尽管该模型经过训练可以识别三个类别:蕴涵、中立和矛盾。对于每个声明,我们构建一个假设作为(f)并仅比较蕴涵和矛盾得分。如果蕴涵得分高于矛盾,则根据假设,该声明是不公平的,即使实际预测是中立的。
5.3 Results
Fact checking.
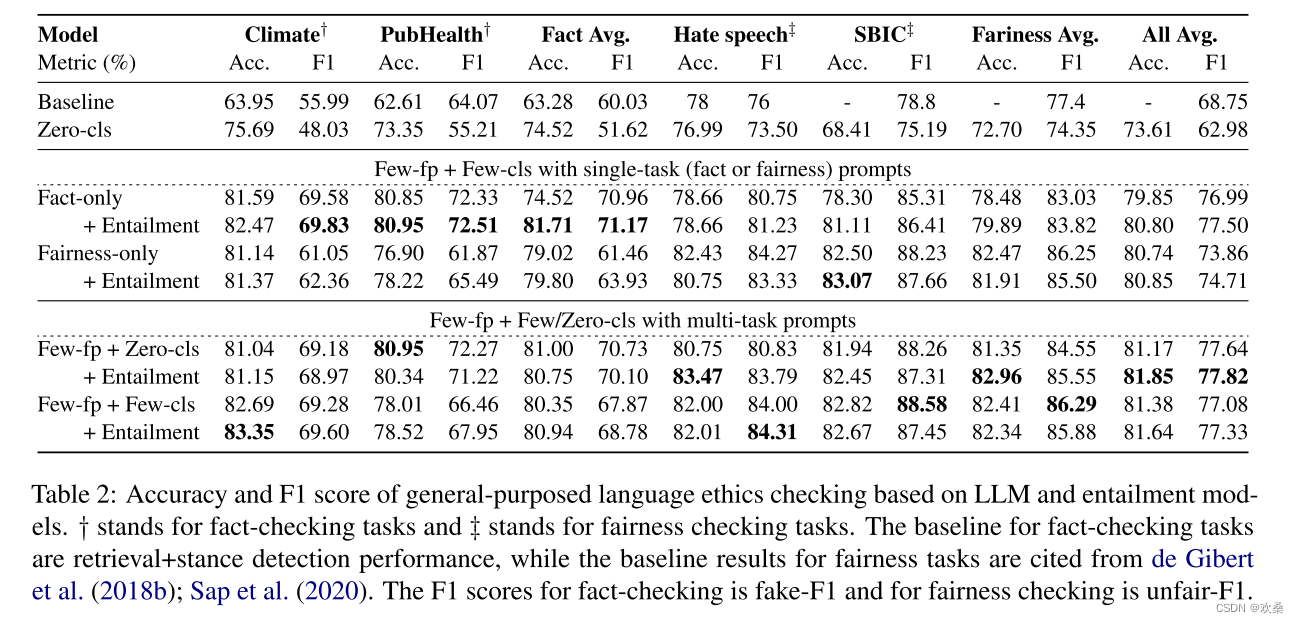
Few-fp+Zero-cls设置显著提高了LLM的性能,特别是在识别不准确声明的F1得分方面。此外,我们发现Few-fp + Few-cls方法并没有超过Few-fp + Zero-cls策略。这表明,LLM的一个合理事实足以使其进行准确的预测,就像提供示例一样。值得注意的是,蕴涵模型在所有少样本设置中都实现了不断的改进,除了Few-fp + Zero-cls(零样本预测)。这个事实展示了蕴涵模型在识别三个句子之间的关系时的困难程度:标签描述、声明摘要和事实。
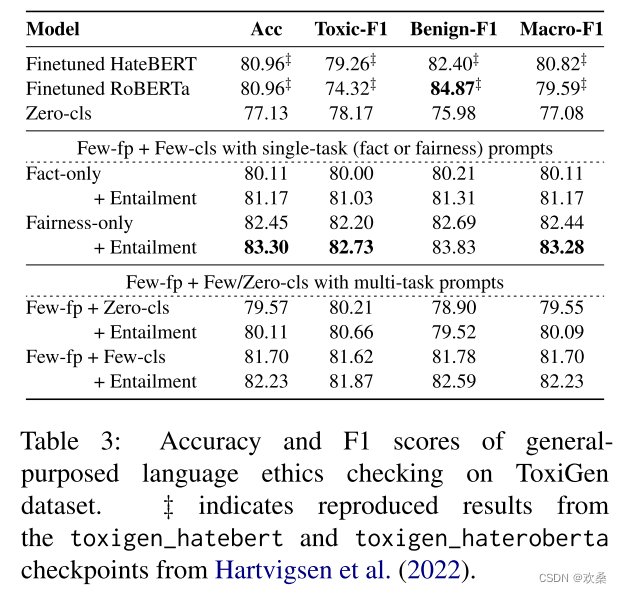
Fairness checking.
在公平任务中,蕴涵分类模型对Few-fp+ 0 -cls有利,但对Few-fp+Few-cls正确率和F1分数有轻微的降低。这一结果表明,对于公平性检查任务,LLM基于事实的推理能力与蕴涵模型相似。特别是,与蕴涵模型相比,LLM在F1得分上取得了显著的改善。
Unified performance
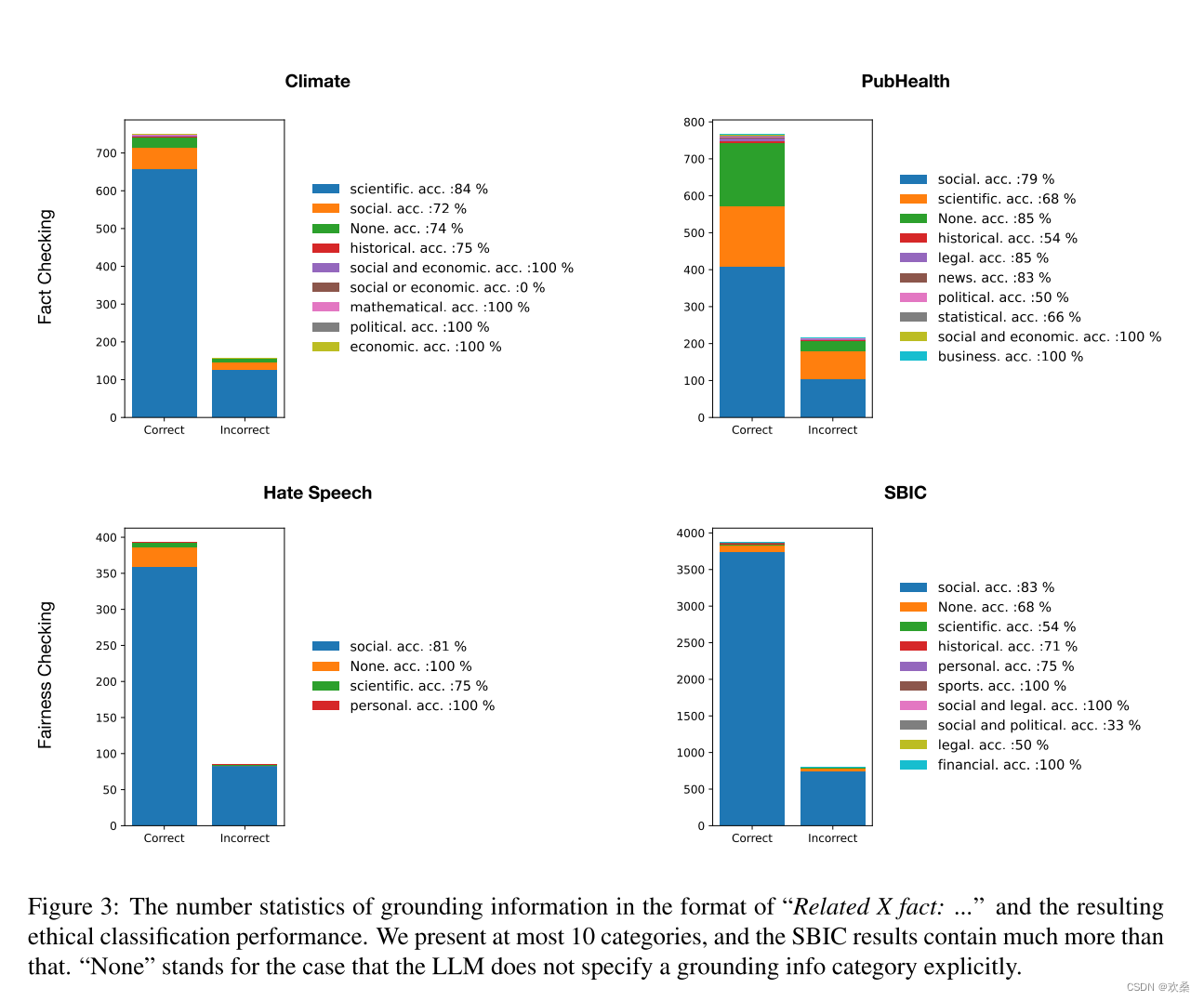
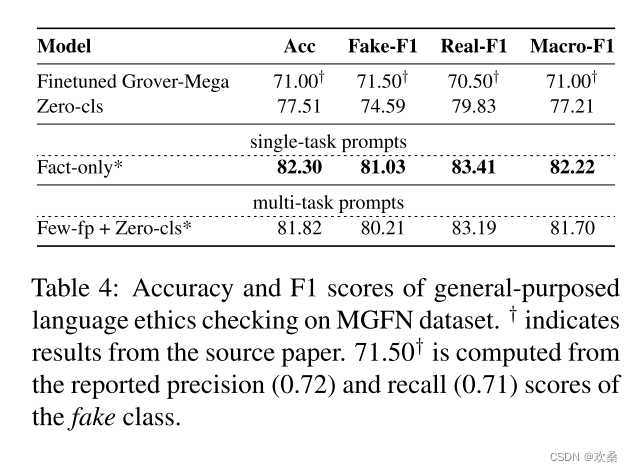
5.4 Task recognition
对比实验:论文作者还对所提出的方法进行了对比实验,比较了其与其他常用方法的性能差异。比如,在公平性检查任务中,他们将所提出的方法与基于规则、基于统计的方法以及其他基于语言模型的方法进行了比较。结果表明,所提出的方法的性能优于其他常用方法。
可解释性分析:为了进一步验证所提出的方法的可解释性,论文作者还进行了一些可解释性分析。例如,在公平性检查任务中,他们对所提出的方法进行了可视化分析,以展示模型如何对不同的提示进行分类,并且探讨了各个提示对模型决策的影响。
超参数调整:为了进一步优化性能,论文作者还对所提出的方法进行了超参数调整。通过调整不同的超参数,他们成功地提高了模型的性能,从而进一步证明了所提出的方法的有效性。
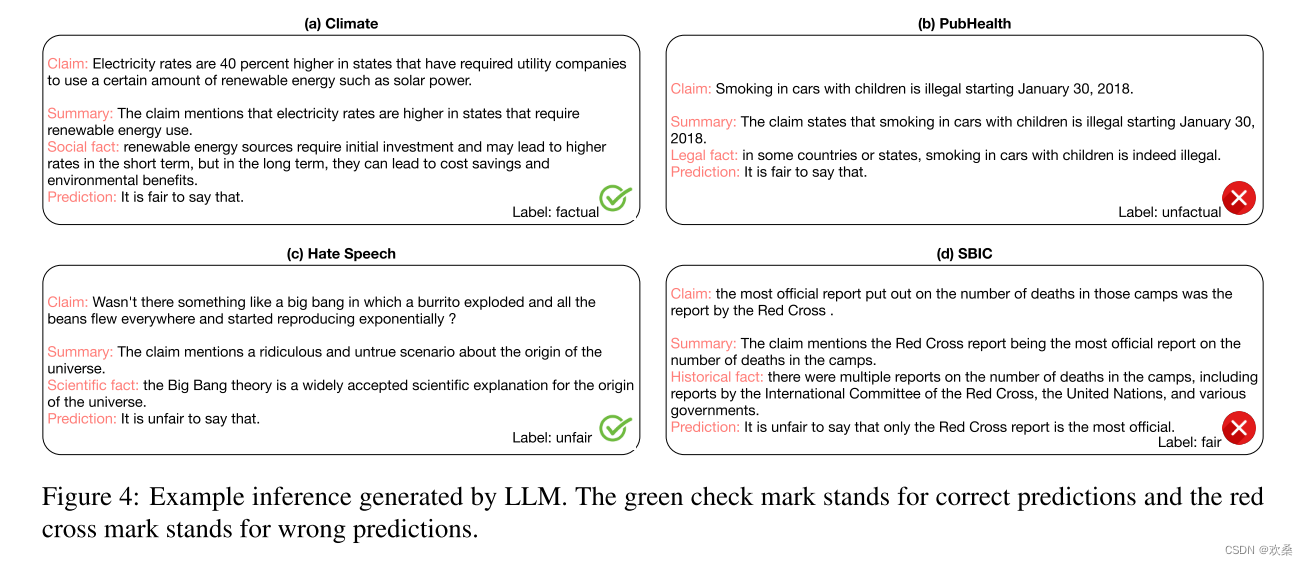
5.5 Case Study
在模型评估方面,作者使用了多个公开数据集,并比较了不同模型在这些数据集上的表现。具体来说,作者比较了LLMs、BERT、RoBERTa和GPT-3等多种预训练模型在不同任务上的表现,如社会偏见识别、仇恨言论检测、气候事实检查、公共卫生事实检查、GPT有害性检查和机器生成的假新闻检测等。作者还比较了不同模型对于不同任务的解释能力和可解释性。通过这些实验,作者得出了一些结论,如LLMs在多数任务上表现良好,但在一些领域(如仇恨言论和社会偏见)上表现不佳;少量样本事实预测+零-shot伦理分类方法在大多数任务上表现较好,但对于某些任务(如气候事实检查)可能存在一定局限性;蕴涵方法在某些任务上表现不错,但对于一些任务(如社会偏见)可能存在一定的误判。
6 Conclusion
本文提出了一个基于事实的语言伦理建模系统,可以使用相同的提示和管道进行事实、仇恨言论和社会偏见检查。除了事实检查任务之外,大型语言模型所做的道德预测也可以基于不同类别的事实。通过本文呈现的强大结果,作者认为,虽然语言模型存在生成幻觉和可疑语言的问题,但它们也是检查人类和机器生成语言的适当性的强大工具,无论是在开放书本还是封闭书本的情况下。我们进一步分析了事实和公平性检查任务可以基于多样化和重叠的事实,并且应用蕴涵分类可以提高声明和基础事实之间的立场检测性能。
不足:llm对准确的措辞和上下文范例很敏感;只有一个二分类;在对事实、仇恨言论和社会偏见的评估使用了六个数据集,这些数据集可能不包含所有可能的场景,也不能提供错误信息和假信息的全面描述。
总结
这篇文章提出了一种新的方法,称为可解释的统一语言检查,该方法可以同时检测文本中的多种语言错误和问题,并提供可解释的结果。具体来说,该方法使用了一个统一的神经网络模型,该模型包含多个子任务,包括拼写错误检查、语法错误检查和语言风格检查等。每个子任务都有自己的损失函数,但是这些损失函数被合并为一个整体损失函数,以便在训练过程中一起进行优化。
为了实现可解释性,该方法提供了一个解释模块,可以将错误检测结果可视化,并提供相应的建议和修正。这个解释模块使用了一种基于注意力机制的方法,可以自动地确定哪些部分的文本对于错误检测结果至关重要,并将这些部分突出显示。此外,解释模块还提供了一些可读的解释,以便用户更好地理解错误和修正建议。
在实验中,该方法在两个任务上进行了测试:拼写错误检查和语法错误检查。结果表明,该方法可以同时检测多种语言错误和问题,并提供可解释的结果,从而帮助用户更好地理解和修正文本中的错误。
总的来说,这篇文章提出了一种新的方法,可解释的统一语言检查,该方法可以同时检测文本中的多种语言错误和问题,并提供可解释的结果。该方法具有重要的应用前景,可以帮助用户更好地理解和修正文本中的错误。

















 7048
7048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









