







 本文介绍了SUS - Chat - 34B通用大模型,它基于01 - ai/Yi - 34B预训练模型微调,在权威榜单取得佳绩。阐述了其训练方法,如指令微调、精化数据等,还评估了角色扮演、长文本理解等能力。虽存在不足,但为学术与工业界合作提供新可能。
本文介绍了SUS - Chat - 34B通用大模型,它基于01 - ai/Yi - 34B预训练模型微调,在权威榜单取得佳绩。阐述了其训练方法,如指令微调、精化数据等,还评估了角色扮演、长文本理解等能力。虽存在不足,但为学术与工业界合作提供新可能。

| 名称 | SUS-Chat: Instruction tuning done right |
|---|---|
| 团队 | 南方科技大学、IDEA研究院CCNL团队 |
| 代码地址 | https://github.com/SUSTech-IDEA/SUS-Chat |
| 简介 | 具有超强多轮对话能力,擅长模仿人类思考过程,在各大榜单上超越同量级的模型。 |
介绍
SUS-Chat-34B模型是南方科技大学联合IDEA研究院CCNL团队开源的通用大模型, 2023-12-05在Huggingface的权威榜单上open_llm_leaderboard取得了同级别模型最好成绩。
SUS-Chat-34B是一个340亿参数规模的双语模型,基于01-ai/Yi-34B预训练模型通过数百万高质量、多语言的指令数据进行了微调。 在保持基础模型强大的语言能力的同时,SUS-Chat-34B模型通过高质量指令微调改善了模型对人类指令的响应方式,并擅长通过思维链的方式模仿人类思考过程。 与Yi-34B和Yi-34B-chat相比,它不仅在几乎所有基准测试中提升了性能,而且能够更好地满足了复杂多语言任务的实际需求。 在指令微调阶段,我们加入了大量高质量长文本和多轮对话指令数据,将文本窗口从基础模型的4K扩展到8K。 这种扩展有助于模型更有效地遵循多轮对话中的指令,显著减少在扩展对话和长文本理解中上下文丢失的问题。为此我们也开发了更高效的训练框架。
模型下载链接:
ModelScope:
https://modelscope.cn/models/SUSTC/SUS-Chat-34B
Hugging Face:
https://hf.co/SUSTech/SUS-Chat-34B
Hugging Face Space:
https://hf.co/spaces/SUSTech/SUS-Chat-34B
模型亮点
SUS-Chat-34B模型具有以下亮点:
- 大规模复杂指令跟随数据:使用1.4B token的高质量复杂指令数据进行训练,涵盖中英文、多轮对话、数学、推理等多种指令数据;
- 强大的通用任务性能:SUS-Chat-34B模型在众多主流的中英文任务上表现出色,其效果超越了相同参数规模的其他开源的指令微调模型。即使与更大参数规模的模型相比,SUS-Chat-34B模型也具有不错的竞争力;
- 更长的上下文窗口与出色的多轮对话能力:目前,SUS-Chat-34B原生支持8K的上下文窗口,在大量多轮指令以及单多轮混合数据中进行训练,具有出色的长文本对话信息关注与指令跟随能力。
SUS-Chat-34B模型有力地证明了通过正确的指令微调,学术机构可以在不增加模型参数的情况下,通过开源的数据集和模型,获得更好的性能, 这弥合了学术界和工业界的在大语言模型上的差距,为学术界和工业界的合作提供了新的可能性。
如何进行的训练
指令微调的重要性
随着人工智能技术的快速发展,AI的多任务学习能力和泛化能力越来越强,实现AI系统目标与人类价值观和利益相对齐,成为了AI研究领域中的重要议题。指令微调往往被认为是模型能够正确接受指令给出恰当反馈、与人类面对问题的思考方式进行对齐的重要过程,也是大模型从只具有模仿能力到真正可以理解人类意图的关键步骤。
指令微调涉及到高质量人类指令数据的收集和整理,需要的计算资源虽然相比预训练来讲偏少,但340亿参数模型的训练对于学术机构来说仍然存在一定的困难。在SUS-Chat-34B模型的训练中,南方科技大学和IDEA研究院CCNL中心通力合作,借由CCNL中心在大模型继续训练、微调和对齐技术等领域的经验,及其所提供的大规模计算集群和合作开发的高性能训练框架,将整个训练的成本控制在了可接受的范围,通过有效降低指令微调成本解决了这一难题。
我们在对指令数据的整理和筛选中做了大量的研究工作,根据小规模数据的实验构建了相关模型,并从中挑选出了最能提升模型思维能力尤其是逻辑能力的百万级别模型。通过这一过程,我们改善了模型对人类指令的响应方式,让模型能够通过思维链等方式模仿人类思考过程。经过我们的训练,SUS-Chat-34B在几乎所有评估模型的benchmark上都表现出了卓越的提升,取得了同尺寸开源模型中的最高分,甚至与具有720亿参数的更大尺寸开源模型相比,也能展现出亮眼的表现。
精化高质量的训练数据
在训练数据迭代的过程中,我们采用了一种精细化的筛选方法,以提炼出与模型能力最相关的数据子集。这一过程涉及对上亿条指令文本数据的深度分析和挑选。我们在100亿参数级别的模型上进行了快速多次实验,根据通用任务榜单的综合性能标准,确定了最优的数据分布。这些实验不仅基于模型的初步表现,而且考虑了最终的收敛目标和模型在各种语言能力及基准测试中的综合表现。这样的策略使得数据组成更加精确地对应于模型的发展需求,从而为其提供了高质量的训练资源。这种方法确保了数据不仅在数量上庞大,而且在质量上符合模型提升的关键需求,特别是在增强模型的语言理解和响应能力方面。通过这种策略,模型能够更有效地学习和适应复杂的语言模式和指令,从而在各种评估中表现出更高的性能和更强的适应能力。
在评测模型的关键性语言能力过程中,我们建立了广泛的基准测试,并开放了一个易于使用的评测框架开源TLEM工具(Transparent LLMs Evaluation Metrics)。欢迎大家点击链接复现我们的模型。
对齐人类逻辑思维方式
SUS-Chat-34B在训练时加入了类似人类思考过程的数据,如在回答问题时先分析问题、规划解决方案,使模型在指令对齐中学会了用人类的逻辑思维方式思考。这使得SUS-Chat-34B在多数指标,尤其是涉及数理逻辑的基准测试中,因为有更加正确的思考方式,指令对齐带来的模型性能降低的问题有所缓解,同时在部分基准测试中获得了相比于预训练模型Fewshot更高的得分。这打破了大模型训练中“对齐税普遍存在”的认知,为模型训练提供了新的思路和借鉴。
中文能力
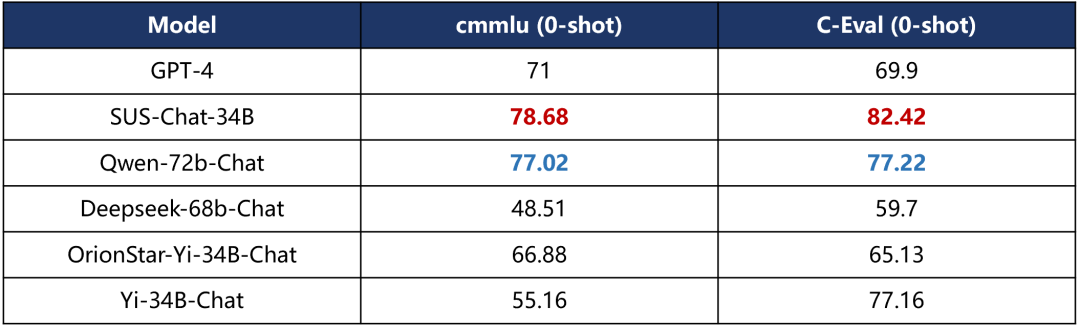
英文理解能力
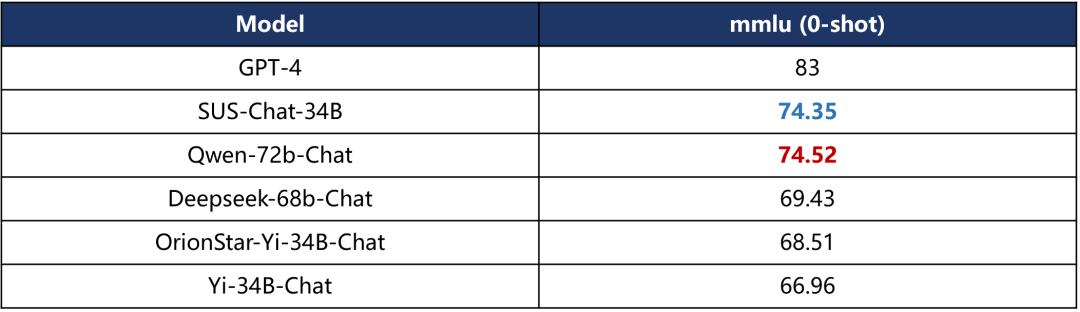
数学与推理能力
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











