卷积神经网络(CNN)
卷积神经网络(Convolutional Neural Network,下称CNN),相比较深度学习网络(Deep Neural Network)输入的向量数据,图像数据并不能使用直接输入,而CNN模型思想是对于该类数据进行特征的提取,然后接入全连接层(Fully Connected Layer)。如图,当一个鸟的数据,将图像转换成像素数据进行传入,如果刚开始压平(Flatten)传入神经网络,这个数据量会非常大,而且一张图片边缘处并不是有效特征,也造成最后对图像识别错误,所以,提取特征是有必要的,可以让整个神经网络训练参数减小,降低计算成本。
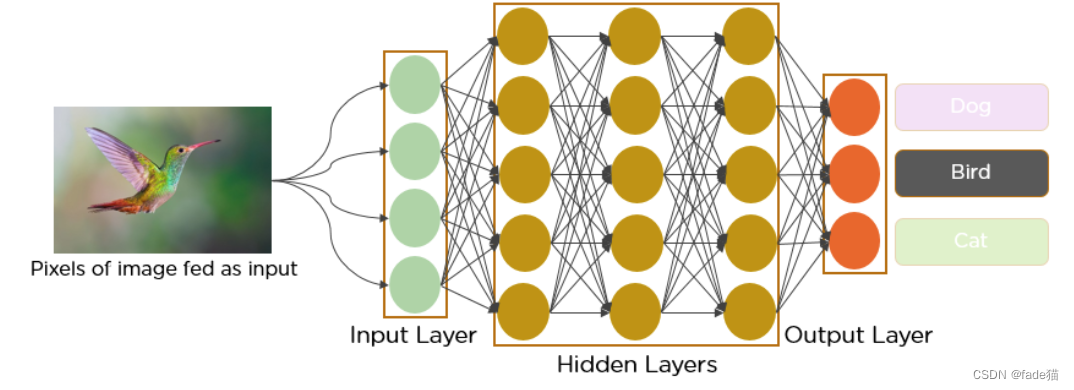
CNN直觉-图片视觉错觉(Optical Illusion)
当你看到这幅图的时候,你首先想到的是一个女孩还是老奶奶?如果你的眼光聚焦的是中间绿色方框,这张图看上去是个少女,如果专注于下方的绿色方框,那么这张图看上去是一位老奶奶;这和人脑工作方式类似,通过捕捉物体的特征点来对物体进行分类,CNN通过捕捉图像中有意义的特征,以便对图像进行分类。

CNN模型结构
CNN模型主要有三层构成:卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer),在卷基层通常会接一个激活函数,通常选Relu,保留大于0的特征数值,不改变特征图大小。

卷积层(Convolutional Layer)
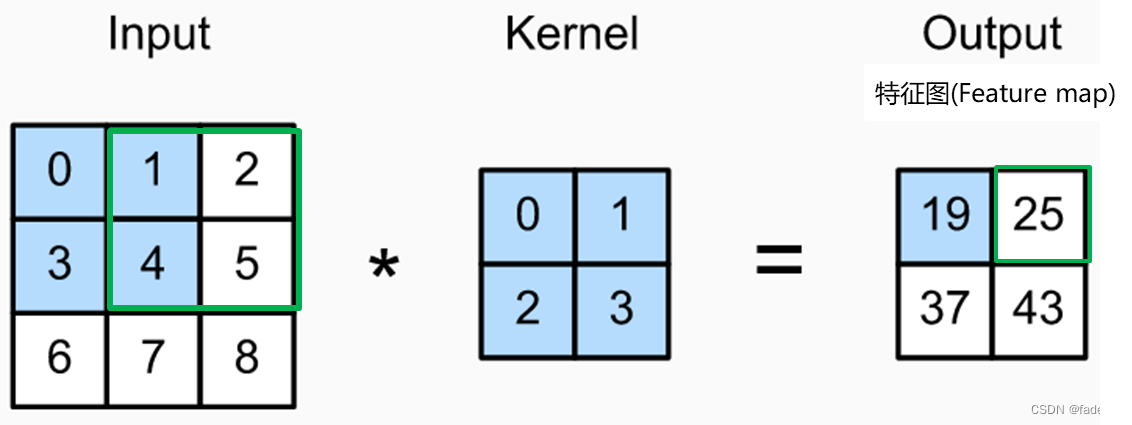
简单计算例子:图片的数据不像数值型的数据那么直观,而都是由像素构成,有长度(Height)宽度(Width)通道(Chanel)构成,常见的图像通道是由RGB三原色叠加构成。单次卷积举例,输入的的图片为3*3的数据,卷积核为2*2,那么对应输出的特征图(Feauture map)第一个特征值,是由输入图片像素数值与卷积核内积和形成,0*0+1*1+3*2+4*3=19,向右滑动一步,步长(stride)等于1,计算绿色方框数字内积和1*0+2*1+4*2+5*3=25。
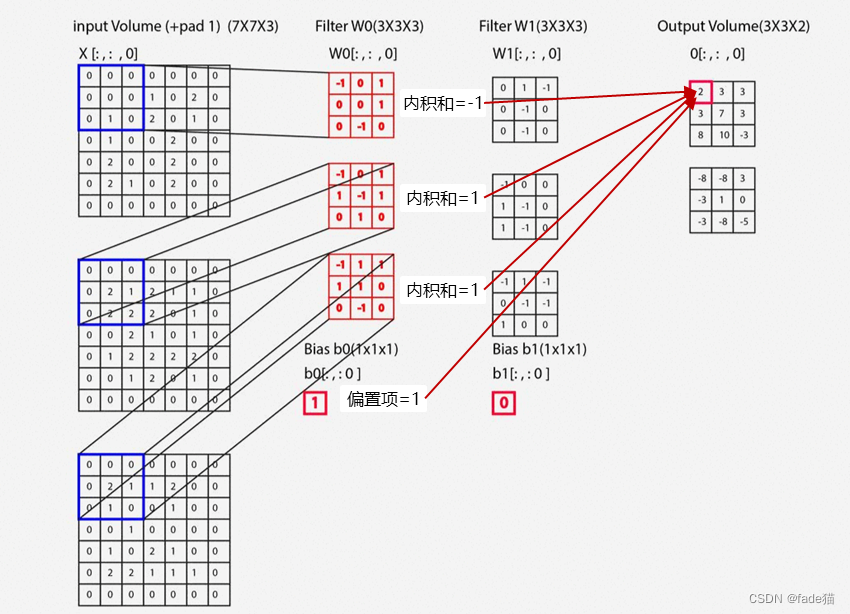
复杂计算的例子:看一个复杂的卷积计算,如图在过滤器加入了偏置项,W0权重=1,根据输入图与卷积核数字内积计算,加上偏置项,总和等于2,为什么卷积核每个通道都不一样,是为了从更多角度获取特征。
输出尺寸计算,输入的是一个5*5*3的图片,记n=5,由于周边填充(pading)一次为0的数值,记p=1,滑动一次步长为2,记s=2,filter(过滤器)有2个卷积核3*3*3(这里输入的通道数为3,是因为保持和输入图片的通道数一致),卷积核尺寸记f=3,这里输出的公式fout=(n+2p-f)/s + 1,fout=(5+2-3)/2+1=3,最后的输入的特征图长度和宽度都3,由于有2个过滤核,最后输出2层3*3的特征图(feature map),表现为3*3*2。
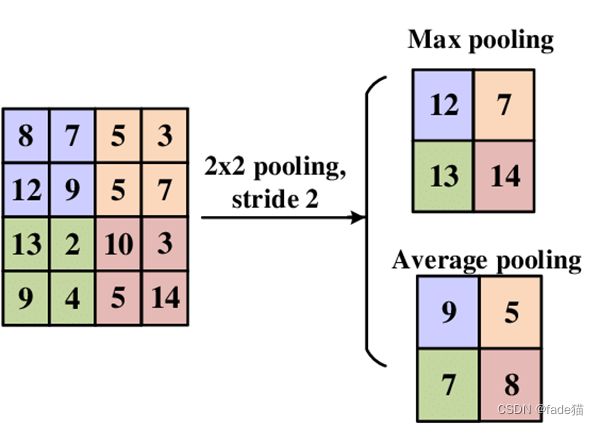
池化层(Pooling Layer)
为了降低计算的复杂度,池化层被设计减少特征图的维度,保留特征,捕获聚合统计信息,比较流行通常有两个处理方式,最大池化(Max Pooling),对卷积层的结果进行取最大值,平均池化(Average pooling),对卷积层结果求平均值。输出尺寸的计算方式:假设卷积后的结果n*n*d,步长s,卷积核f*f,卷积核的结果等于fout = (n-f)/s+1,这里这里输入的44尺寸,通过22的卷积,步长为2,输出的特征图尺寸为(4-2)/2+1=2,所以得到尺寸2*2。
全连接层(Fully Connected Layer)
通过卷积核池化后,将数据压平(Flatten),接入传统神经网络全连接层,进行分类操作。
整体CNN层数,刚才计算方式可以看出卷积层是带权重和偏置参数的的,而Relu层、池化层均不带计算,全连接层也是带权重和偏置参数的。算CNN层数不包括Relu层和池化层。
为什么CNN模型使用多层卷积?看ChatGTP给出的答案

1*1卷积
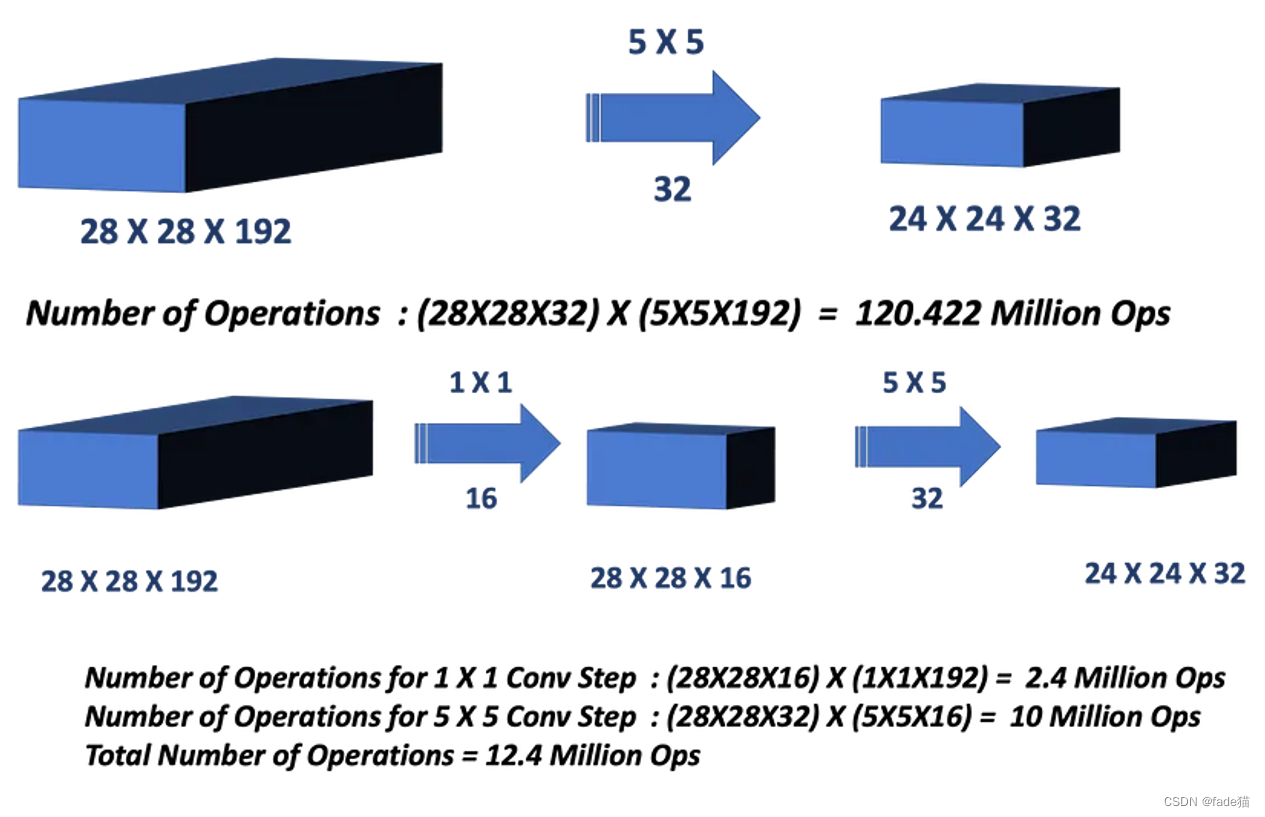
直觉上1*1的卷积仅对像素高度和宽度进行过滤,意义并不是很大,但结合不同通道信息融合,可以实现通道数降维或升维,获取24*24*32卷积层,如图引入1*1卷积,这个可以理解成,你在1*1*32通道上,对于输出层在相同的高度和宽度,需要32个不同通道数,做一个内积和,进行跨通道联系,整合信息,此时有16个filter,这个时候28*28*16,极大压缩了数据量,如下图经过1*1卷积参数量由原120.422M降低到12.4M,降低接近1/10,极大的降低了计算资源。
深度残差网络(ResNet)
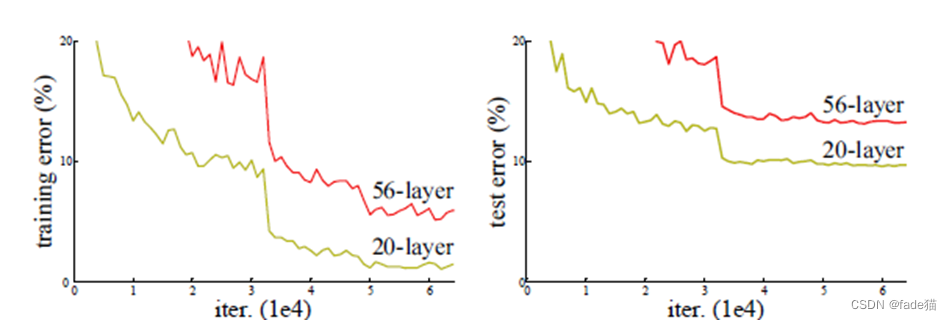
直觉上神经网络层数越深,最后效果越好,但并不是这样,如下图深度学习堆叠越深,效果并没有变好,从图可以看出神经网络在56层在训练集和测试集的表现都不如20层的好,这不是梯度消失、过拟合,梯度消失在迭代停止训练,在图中无论在训练集和测试集一直都在迭代训练,过拟合表示的在训练集表现差,在测试集表现好,但图中也并未显示这种想象,因此,这种现象表示为神经网络出现退化。
何恺明(2015)设计出基于残差网络模块残差网络,在输入下一层的神经网络时,通过skip connection与新增的权重层输出的结果相加,假设新加的层输出结果为0,那么通过skip connection链接后,这部分数据并不会丢失,不仅有利于保留有效的数据,而且有利于加深神经网络,这里为了保持X通过short connection尺寸一致,作者也提出一个解决方案,通过引入11卷积核,来保持和x尺寸一致。下图2,这里发现33卷积核用的比较频繁,在实际中一般都会选择3*3的卷积核。【这篇Deep residual learning for image recognition论文方法听起来不难,有种听起来感觉原来还能这样搞,会让人产生我上我也行的奇怪想法,现在是深度学习基本组件,现在的时间节点Google上引用次数达到15.6万,引用次数相当爆炸】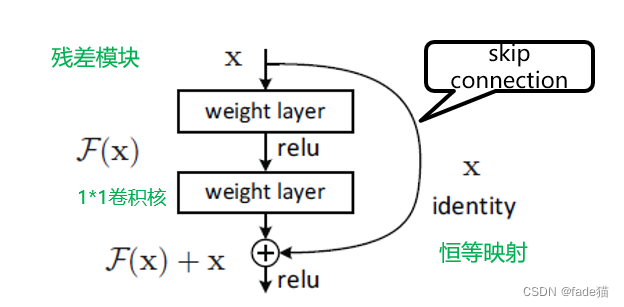
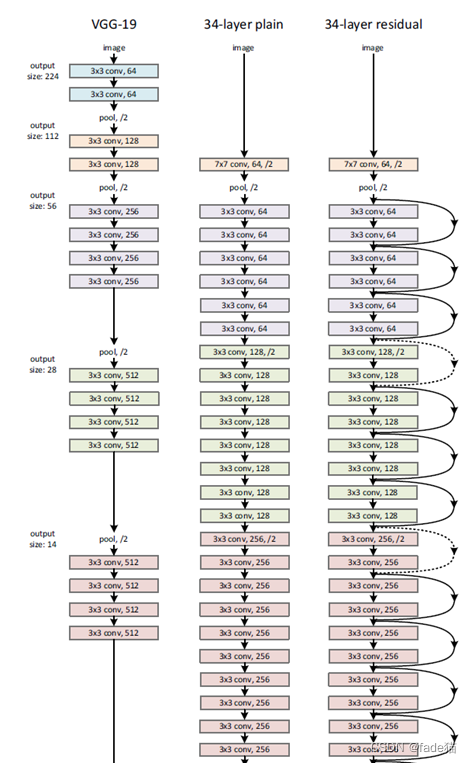
ResNet解决网络机制到底是什么,上述的描述是帮助是理解,与大佬吴恩达在课件表述类似,这里截取B站@同济子豪兄链接: link讲述机理图片,点个赞

迁移学习(Transfer Learning)
当面临输入数据较多,这时候从0开始训练完整的的卷积网络,相对是不科学的,一方面所需要计算资源巨大,另一方面自己的搭建训练的结果未必有现成网络的学习效果好(基于别人学习好的参数,显卡GTX1660s,大概就6500张图片,跑了一个102分类的数据,迭代10次,花了40几分钟),pytorch中torchvision预设很多参数和成熟模型,参考下这个链接: link,对于自己的数据保持前后尺寸一致,注意修改分类,在上述模型的训练的基础上,再对所有的参数进行全部训练,pytorch也给出初始化模型网络参考例子。
def initialize_model(model_name, num_classes, feature_extract, use_pretrained=True):
model_ft = None
input_size = 0
if model_name == "resnet":
"""Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
"""Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "squeezenet":
"""Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299, 299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 299
else:
print("Invalid model name, exiting...")
exit()
return model_ft, input_size




 卷积神经网络(CNN)是一种用于图像处理的深度学习模型,通过卷积层、池化层和全连接层提取和分类图像特征。ResNet的残差学习解决了深层网络的退化问题,迁移学习则利用预训练模型提高新任务的效率。CNN的关键在于特征提取,例如1*1卷积用于通道融合,池化层降低计算复杂度,而ResNet的skipconnection保持信息传递。
卷积神经网络(CNN)是一种用于图像处理的深度学习模型,通过卷积层、池化层和全连接层提取和分类图像特征。ResNet的残差学习解决了深层网络的退化问题,迁移学习则利用预训练模型提高新任务的效率。CNN的关键在于特征提取,例如1*1卷积用于通道融合,池化层降低计算复杂度,而ResNet的skipconnection保持信息传递。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









