






1. http://www.pythonchallenge.com/pc/def/0.html

方法:计算2的38次方,274877906944
跳转url:http://www.pythonchallenge.com/pc/def/274877906944.html
2. http://www.pythonchallenge.com/pc/def/map.html

方法:上图已标记,那么根据该规律,可得出当前链接中的“map”为“ocr”
跳转url:http://www.pythonchallenge.com/pc/def/ocr.html
3. http://www.pythonchallenge.com/pc/def/ocr.html

方法:提示说答案在书中或者源网页中,书中是不可能在书中的了,在源网页中,查看源网页,显示如下,提示说从下面这些乱七八糟的符号中找出出现次数最少的字符,直接爬取当前网页,程序简单。
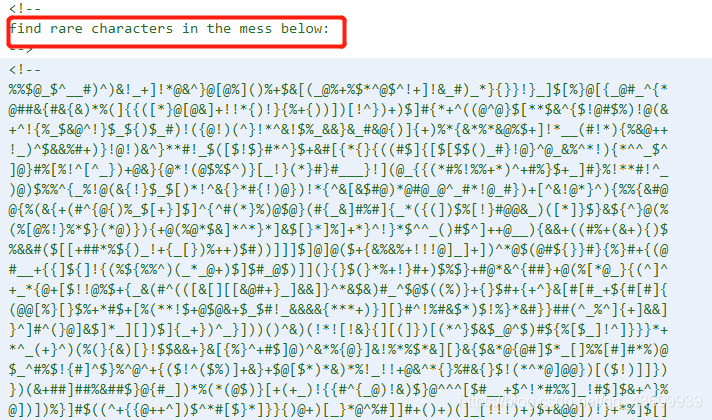
import requests, re
url = 'http://www.pythonchallenge.com/pc/def/ocr.html'
resp = requests.get(url)
content = re.sub('\s', '', resp.text)
content = re.findall('<!--%%(.*?)-->', content)[0]
my_dict = {}
for i in content:
if i in my_dict:
my_dict[i] += 1
else:
my_dict[i] = 1
print(my_dict)
答案:equality
跳转url:http://www.pythonchallenge.com/pc/def/equality.html
4. http://www.pythonchallenge.com/pc/def/equality.html

方法:也是在源网页中找,方法同上,正则修改匹配规则,代码如下
import urllib.request as ur
import re
url = "http://www.pythonchallenge.com/pc/def/equality.html"
response = ur.urlopen(url)
body = response.read()
pattern ="[^A-Z][A-Z][A-Z][A-Z]([a-z])[A-Z][A-Z][A-Z][^A-Z]"
result = re.findall(pattern, body.decode())
print(result)
答案:linkedlist
跳转url(需要跳转两次):http://www.pythonchallenge.com/pc/def/linkedlist.html
http://www.pythonchallenge.com/pc/def/linkedlist.php
5. http://www.pythonchallenge.com/pc/def/linkedlist.php
方法:什么文字提示都没有,还是查看源网页,看到一个新链接,点进去试试。弹出一句话“and the next nothing is xxx”,猜想是将当前url最后的数字部分不断替换直至找到答案。每输入一个新数字,都会跳转到另一个数字,所以手动输入是不可能的,代码如下。最后会跳转到一个peak.html。
跳转url:http://www.pythonchallenge.com/pc/def/peak.html
需要注意的是把“linkedlist.php?nothing=xxx”整个替换成“peak.html”,否则链接会从头循环,不会跳转到新的界面。
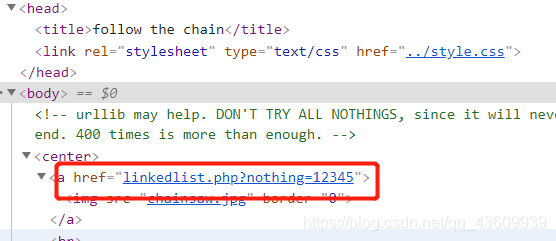
import requests
import re
url = "http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345"
while True:
resp = requests.get(url)
num = re.findall('and the next nothing is ([0-9]+)', resp.text)
if num:
url = 'http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=' + num[0]
print(num)
print(url)
else:
break
print(num)
6. http://www.pythonchallenge.com/pc/def/peak.html
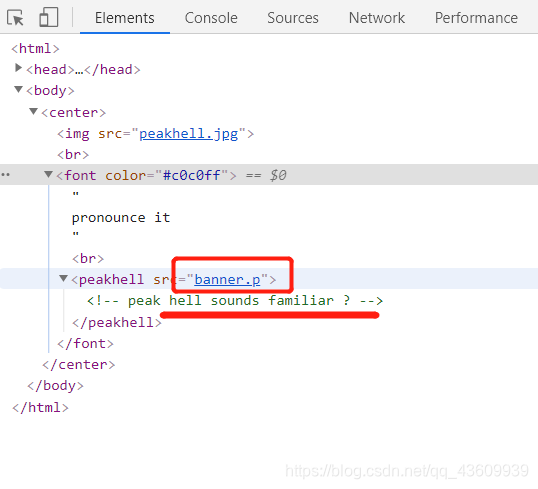
方法:根据提示“peak hell sounds familiar?”,发音类似,peak heal 听起来像pickle,猜测要用到python中的pickle库,自行百度,序列化和反序列化作用,将二进制数据和字符串等类型数据相互转换以便传输。
找到“banner.p”,右键点击“在新窗口打开”,如下图第二张所示。看样子这个数据应该是需要转换一下的。使用pickle.load反序列化,具体操作见代码。
答案:channel
跳转url:http://www.pythonchallenge.com/pc/def/channel.html

import requests, urllib
import pickle
"""
代码原理:将反序列化后的数据遍历,通过空格和#拼接成一副图形,图形显示的是一个单词
"""
url = "http://www.pythonchallenge.com/pc/def/banner.p"
content1 = urllib.request.urlopen(url).read() # 返回的是bytes类型
content2 = pickle.loads(content1) # load读取文件,loads可以直接读取二进制类型数据
# print(type(content2), content2) # 返回list类型
for eve_list in content2:
s = ""
for i in eve_list:
s += i[0] * i[1]
print(s)
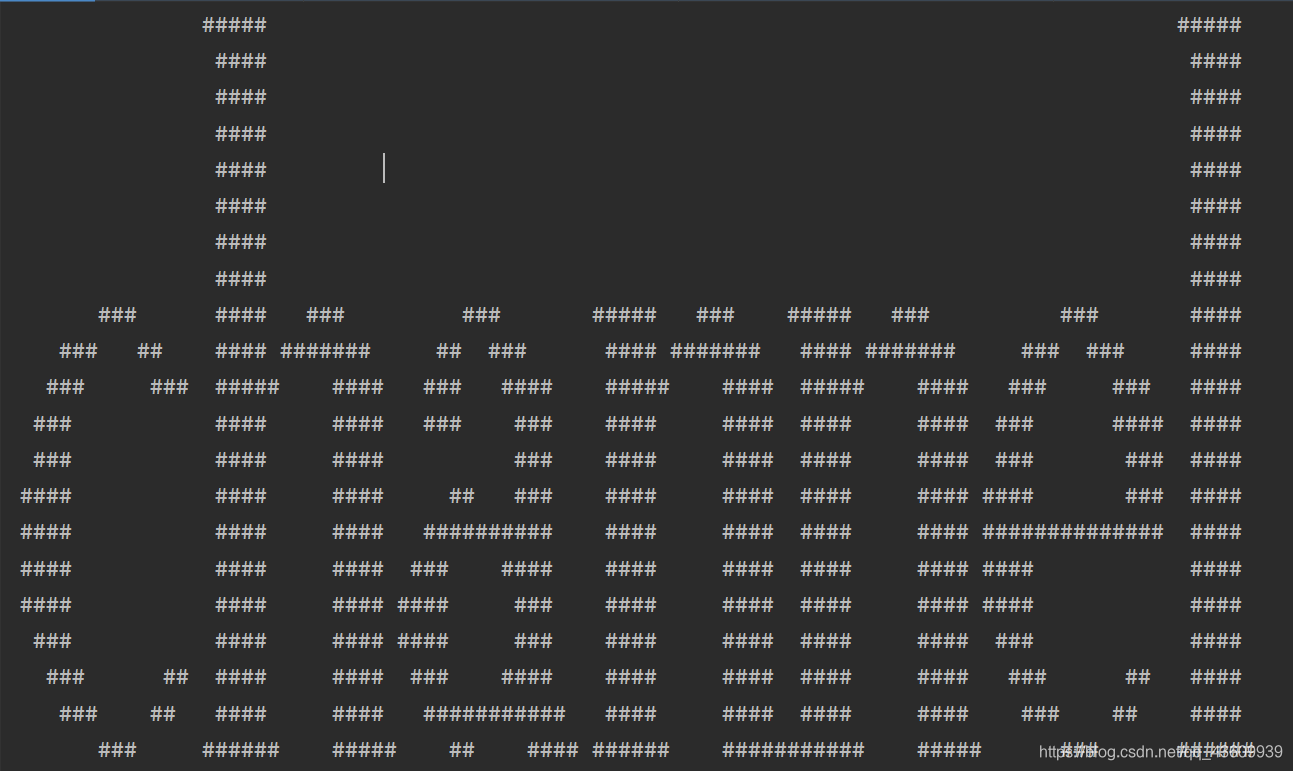














 762
762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









