







今天开会的时候,知道这样一个学习python的游戏网站。
先占坑。后续慢慢完善。
网站地址
http://www.pythonchallenge.com/
开发环境
Win7旗舰版
Nodepad++
Python 3.5.2
通关代码及攻略
第0题

题目分析
让我们算2的38次方,那么我们知道Python的算术运算符**代表幂运算
考察知识点
幂运算符

代码及结果
在Python解释器里直接运行
2**38
结果是274877906944
在地址栏这样输入即通关
http://www.pythonchallenge.com/pc/def/274877906944.html
第一题
题目分析
K的后面第二个字母是M, O的后面第二个字母是Q,E的后面第二个字母是G
用同样的方法处理map
考察知识点
ASCII码表
ASCII码转换为相应字符chr()
字符转换为响应ASCII码ord()
代码及结果
在nodepad++中编辑,exc1.py
#将字符转换为对应的ASCII
m,a,p=ord('m'),ord('a'),ord('p')
#处理字符
print(chr(m+2),chr(a+2),chr(p+2))
结果是:ocr
在地址栏这样输入即通关
http://www.pythonchallenge.com/pc/def/ocr.html
第二题

题目分析
MAYBE they are in the page source.
叫我们去网页里源码里找提示
右键查看源代码

发现叫我们找这一长串字符中出现最少的字符
那么我们就需要用循环遍历这一长串,并通过调用方法,找出出现最少的字符
考察知识点
Python 循环语句
http://www.runoob.com/python/python-for-loop.html列表List
http://www.runoob.com/python/python-lists.html- list.append(obj)
在列表末尾添加新的对象 - list.count(obj)
统计某个元素在列表中出现的次数
- list.append(obj)
Python条件语句
http://www.runoob.com/python/python-if-statement.htmlPython成员运算符
Python引号
Python 接收单引号(’ ),双引号(” ),三引号(”’”“”) 来表示字符串,引号的开始与结束必须的相同类型的。其中三引号可以由多行组成,编写多行文本的快捷语法,常用语文档字符串,在文件的特定地点,被当做注释。

代码及结果
在nodepad++中编辑,exc2.py
#将字符存到字符串中
str="""%%$@_$^__#)^)&!_+]!*@&^}@[@%]()%+$&[(_@%+%$*^@$^!+]!&_#)_*}{}}!}_]$[%}@[{_@#_^{*
@##&{#&{&)*%(]{{([*}@省略n行"""
#定义一个列表List存储所有字符
list=[]
#定义一个列表key存储所有唯一的字母
key=[]
#遍历字符
for i in str:
#将字符存到list中
list.append(i)
#如果字符是唯一的,则添加进key
if i not in key:
key.append(i)
#将list列表中的字符出现字数统计出来
for items in key:
print(items,list.count(items))结果:
从图片可知,通关密码为equality
在地址栏这样输入即通关
http://www.pythonchallenge.com/pc/def/equality.html
第三题

题目分析
One small letter, surrounded by EXACTLY three big bodyguards on each of its sides.
一个小写字母,两侧都被三个大写字母包围。
类似于:xXXXxXXXx
查看源码
字符串匹配问题首选正则表达式,考虑用循环和正则表达式进行判断
考察知识点
Python正则表达式
http://www.runoob.com/python/python-reg-expressions.html
代码及结果
在nodepad++中编辑,exc3.py
#导入正则表达式模块
import re
#需遍历的字符串
#导入正则表达式模块
import re
#需遍历的字符串
str="""kAewtloYgcFQaJNhHVGxXDiQmzjfcpYbzxlWrVcqsmUbCunkfxZWDZjUZMiGqhRRiUvGmYmvnJIHEmbT
MUKLECKdCthezSYBpIElRnZugFAxDRtQPpyeCBgBfaRVvvguRXLvkAdLOeCKxsDUvBBCwdpMMWmuELeG
ENihrpCLhujoBqPRDPvfzcwadMMMbkmkzCCzoTPfbRlzBqMblmxTxNniNoCufprWXxgHZpldkoLCrHJq省略n行"""
#匹配字符串模式为xXXXxXXXx
result=re.findall("[a-z]{1}[A-Z]{3}[a-z]{1}[A-Z]{3}[a-z]{1}",str)
#设定列表索引
y=0结果:
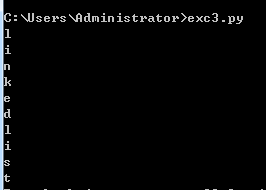
从图片可知,通关密码为linkedlist
在地址栏这样输入
http://www.pythonchallenge.com/pc/def/linkedlist.html
即出现

输入http://www.pythonchallenge.com/pc/def/linkedlist.php即通关
第四题

点击网页上的图片后,进入连接
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345

按照提示将连接改成http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=20160810143222471
以此类推。。很多次(有兴趣可以试试400次左右)
题目分析
如果设定的是200次。不可能每次都手动输入url。
所以这里应该写程序来获取网页中字符串显示的数据连接,然后改url访问下一次直到成功(页面上不再出现and the next nothing is 80992(数字) 这样形式的字符串)
那么如何获取网页上显示的字符串呢?此时想到了网络爬虫。搜索相关知识,发现Python中urllib2模块可以实现该功能。
考察知识点
Python正则表达式(用以匹配网页上的字符串信息)
http://www.runoob.com/python/python-reg-expressions.htmlPython中urllib2模块
python urllib2详解及实例
http://www.pythontab.com/html/2014/pythonhexinbiancheng_1128/928.html
注:urlib2模块在Python3已拆分更名为urllib.request 和urllib.error
原来调用方法urllib2.xxx() 现在根据情况改变成urllib.request.xxx()或urllib.error.xxx()
代码及结果
在nodepad++中编辑,exc4.py
import urllib.request
import re
import os
#打开url
src = urllib.request.urlopen('http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345')
#下一个页面的地址
nexturl = None
url = 'http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing='
#计数器
count=0
while True:
#通过url获取页面资源
nexturl = src.readline()
#下一个页面的数字
nextid = nexturl[-5:];count=count+1
try:
nextid = int(nextid)
except:
break
#下一个页面的地址
nexturl = url+str(nextid)
print(count,'next url-->'+nexturl)
#关闭url连接
src.close()
src = urllib.request.urlopen(nexturl)
结果:
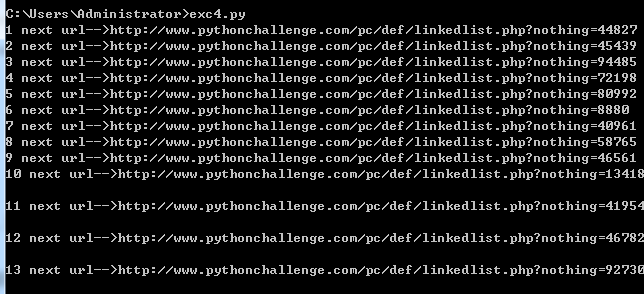
此处省略n行(提示:可能根据你网络连接的好坏,会执行到不同的步数。。)
最后结果
显示访问:
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=16044
提示信息:Yes. Divide by two and keep going.
改下代码nothing=”8022”,继续运行
http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=66831
拿到密码:peak.html
在地址栏这样输入
http://www.pythonchallenge.com/pc/def/peak.html
即通关
第五题
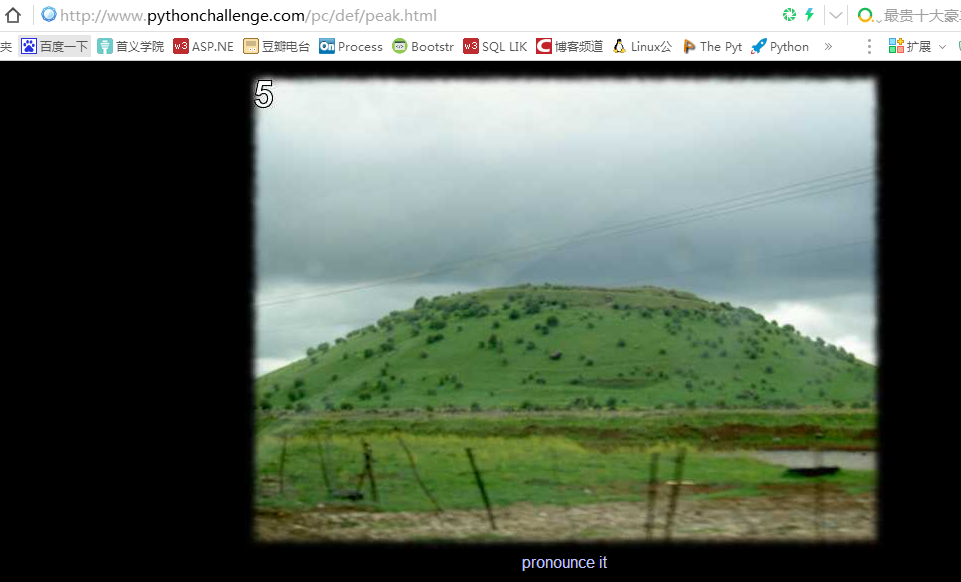
题目分析
一头雾水,查看源码

注意这条提示信息:Peak hell sounds familiar
Peak 听起来跟pickle一样
再点击banner.p
故,这题考的是Python持久化对象,需要用pickle模块解析banner.p里的文档
考察知识点
Python持久化对象pickle模块
http://blog.csdn.net/jurbo/article/details/52204065
代码及结果
在nodepad++中编辑,exc5.py
import pickle
#打开文件
pk_file=open("banner.p","rb")
#将文件反序列化成对象
data=pickle.load(pk_file)
str=""
#对输出做处理
for list in data:
print(list)
for i in list:
str+=i[0]*i[1]
str+='\n'
print (str)将文件反序列化成对象得到的是
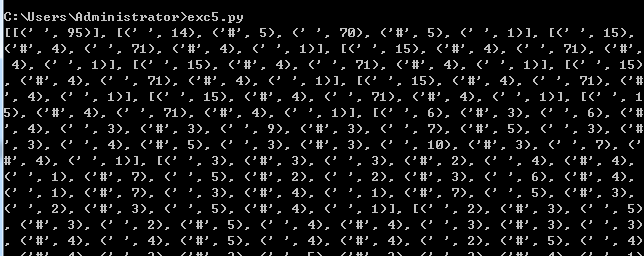
看出这是个列表,如果对这个列表进行处理,应该会出现一个图案
对输出做处理
得到的截图
这是对象里的每个列表
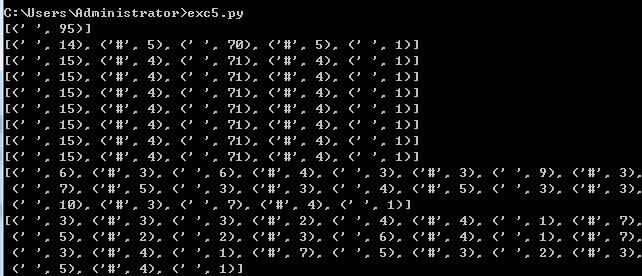
对列表中的字符与数字做处理
得到图案。
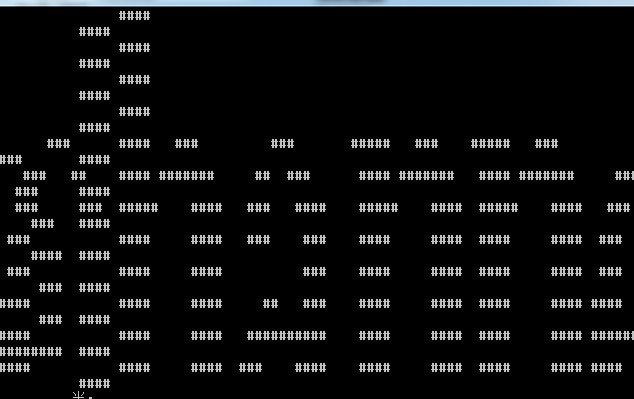
这里我的电脑显示缩略图。其实显示的是channel
输入http://www.pythonchallenge.com/pc/def/channel.html即进入下一关
第六题
题目分析
查看源码

没发现什么线索,不过这一段很可疑

将网址替换成http://www.pythonchallenge.com/pc/def/channel.zip
发现有个文件,下载后打开
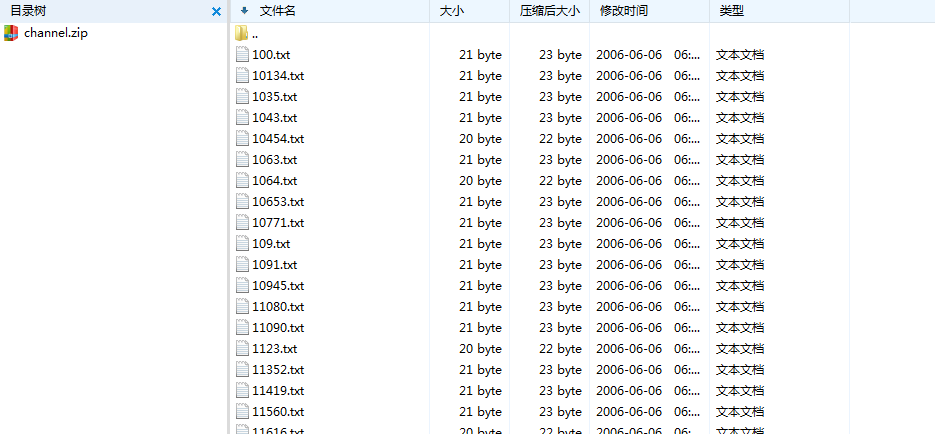
有一大堆的数字命名的文件,随意点开一个都显示
Next nothing is xxxxxx
打开特殊的文件,readme.txt

发现跟第4题一样。也是要找Next nothing is 后面的。只不过这题考察的是对zip文件的处理,而不是网络处理。
考察知识点
zipfile模块
正则表达式
代码及结果
在nodepad++中编辑,exc6.py
#导入对zip文件处理的模块 zipfile
import zipfile,re
#以只读的方式打开zip文件
z=zipfile.ZipFile("channel.zip","r")
#从readme.txt中获取的tip,开始的第一个文件
next="90052.txt"
count=1
while(1):
#读取zip中的文件信息,此时拿到是数据是byte字节数组
infomation=z.read(next)
#因为re.findall需要对字符串数组做操作,所以将其转换为字符串数组
#除了下面这种转换方式,还有另外一种转换bytes.decode(infomation)
infomation=str(infomation,encoding="utf-8")
#根据正则表达式匹配文件中的数字内容,此时拿到的数据是list
result=re.findall("[0-9]",infomation)
#因为要获取数字,所以将匹配得到的list结果转换为string型
convert=''.join(result)
#拼接下一个文件名
next=convert+".txt"
count+=1
#将文件名字输出
print(count,"mext filename is ",next)
结果是:
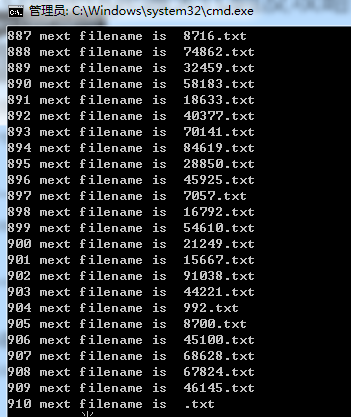
发现在46145.txt中停止了。
点击46145.txt查看
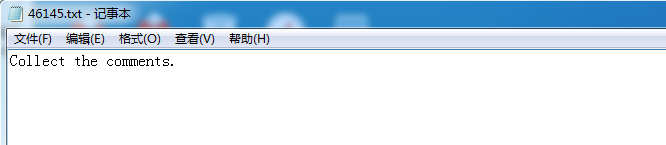
发现叫我们搜集comments。通过学习zipfile模块,我们得知,可以在创建zipfile时,给每个文件添加comments信息。因此代码还要做改动
#导入对zip文件处理的模块 zipfile
import zipfile,re
#以只读的方式打开zip文件
z=zipfile.ZipFile("channel.zip","r")
#从readme.txt中获取的tip,开始的第一个文件
next="90052.txt"
count=1
comments = []
while(1):
#读取zip中的文件信息,此时拿到是数据是byte字节数组
infomation=z.read(next)
#将文件里的comment保存到list中
comments.append(z.getinfo(next).comment)
#因为re.findall需要对字符串数组做操作,所以将byte字节数组转换为字符串数组
#除了下面这种转换方式,还有另外一种转换bytes.decode(infomation)
infomation=str(infomation,encoding="utf-8")
#根据正则表达式匹配文件中的数字内容,此时拿到的数据是list
result=re.findall("[0-9]",infomation)
#因为要获取数字,所以将匹配得到的list结果转换为string型。注意:用join方法的话,里面的参数需要保证所有元素都是string的list
convert=''.join(result)
#拼接下一个文件名
next=convert+".txt"
#计数器加一
count+=1
##将文件名字输出
#print(count,"mext filename is ",next)
end=""
#因为comments是个字节List,因此需要对输出做处理(将List中的每个字节转化为字符串)
for list in comments:
end+=str(list,encoding="utf-8")
#输出comment
print (end)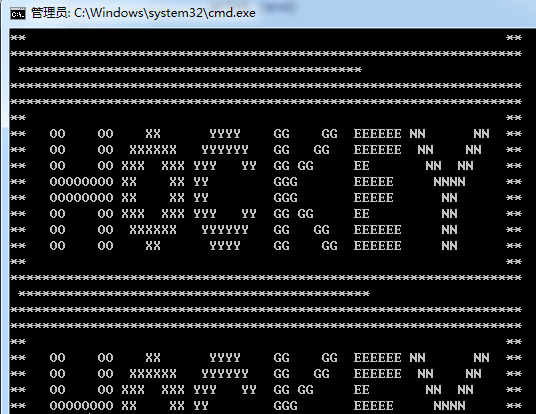
此处看到存的comment均是:hockey
输入http://www.pythonchallenge.com/pc/def/hockey.html
通关~~
鬼。。

说什么:这个是空气上的??仔细查看字母。。(英语不好。。直翻译)
仔细看图片发现是:oxygen
输入http://www.pythonchallenge.com/pc/def/oxygen.html
通关。。这关好多戏啊。。
第七题
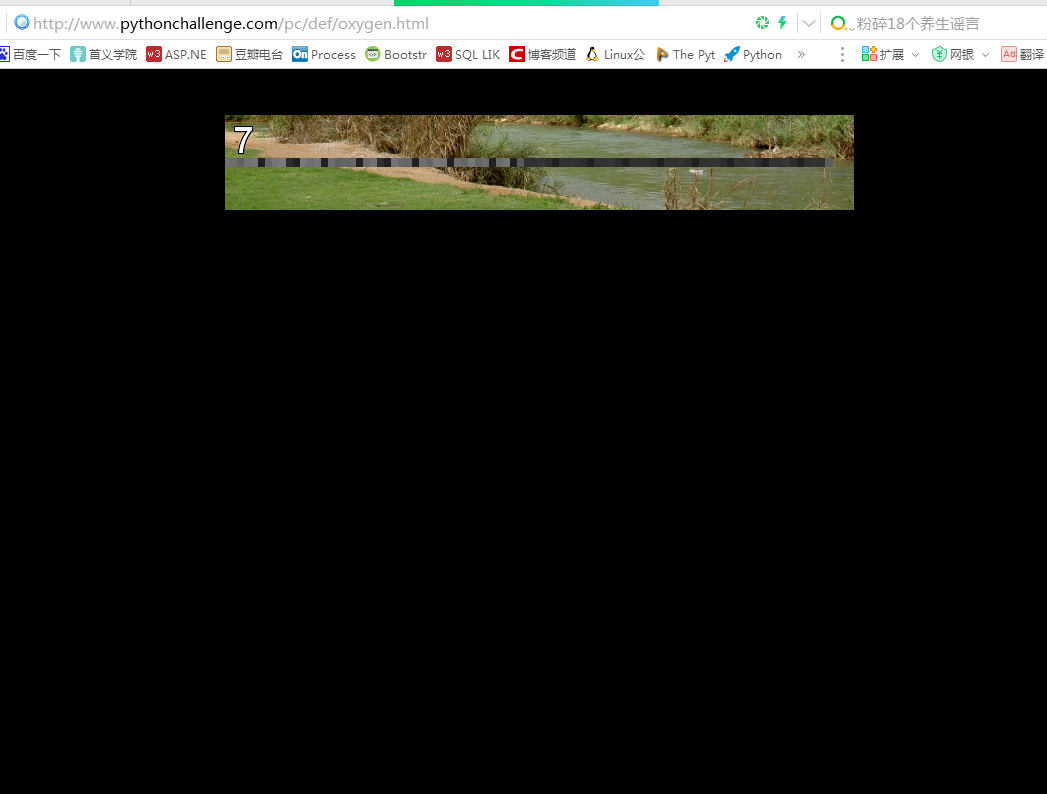
题目分析
除了张图片,啥都没有。按照惯性,查看源码。
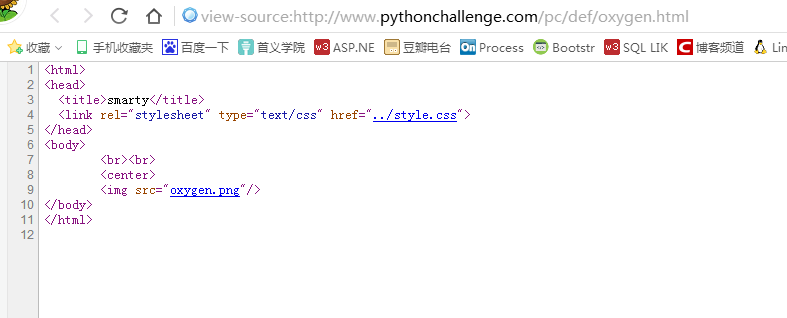
源码中,oxygen.png很可疑。点击进去。还是显示那张图。
仔细观察,发现图片中间有类似于马赛克的东西。这题应该是考的图像解析。
Python 里面最常用的图像操作库是 Image library(PIL)
在百度键入 “Python 图像处理”得到image模块相关~
故此题是考察我们对image模块的应用
考察知识点
Python-Image 基本的图像处理操作(赞)
http://www.aichengxu.com/view/39904Python图形图像处理库的介绍之Image模块
http://onlypython.group.iteye.com/group/wiki/1372-python-graphics-image-processing-library-introduced-the-image-module- Python Imaging Library (PIL)下载
http://www.pythonware.com/products/pil/
代码及结果
在nodepad++中编辑,exc7.py
既然要处理和图片有关的东西,那就应该理解一下PIL库,其中有一个Image模块可以处理图片。用GIMP打开oxygen.png图片,发现其大小为629*95,而灰色区域第一块有5个像素,接着是85个有7个像素的区段,最后是一个8个像素的区段,我们可以从第50行采样。同样我们要注意到,该图片是“RGBA”模式的,也就是说每个像素是有4个数据表示的;通过查阅Image模块的相关资料,我们发现‘L’模式是每个像素由1个在(0,255)区域的数值表示。那么我们就可以把它当做ASCII处理
import urllib,Image,re
file = open('oxygen.png', 'wb')
file.write(urllib.urlopen('http://www.pythonchallenge.com/pc/def/oxygen.png').read())
file.close()
image = Image.open('oxygen.png')
data = image.convert('L').getdata()
message = []
for i in range(3,608,7):
message.append(chr(data[image.size[0]*50+i]))
rusult=''.join(message)
print(result) 运行脚本,得到结果“smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]”。很显然,关键信息包含在[]的9个数值上,转换为ASCII码:
numbers = [105, 110, 116, 101, 103, 114, 105, 116, 121]
word = []
for number in numbers:
word.append(chr(number))
rusult=''.join(word)
print(result) 运行脚本,得到integrity
输入http://www.pythonchallenge.com/pc/def/integrity.html,通关!
第八题
题目分析
查看源码。
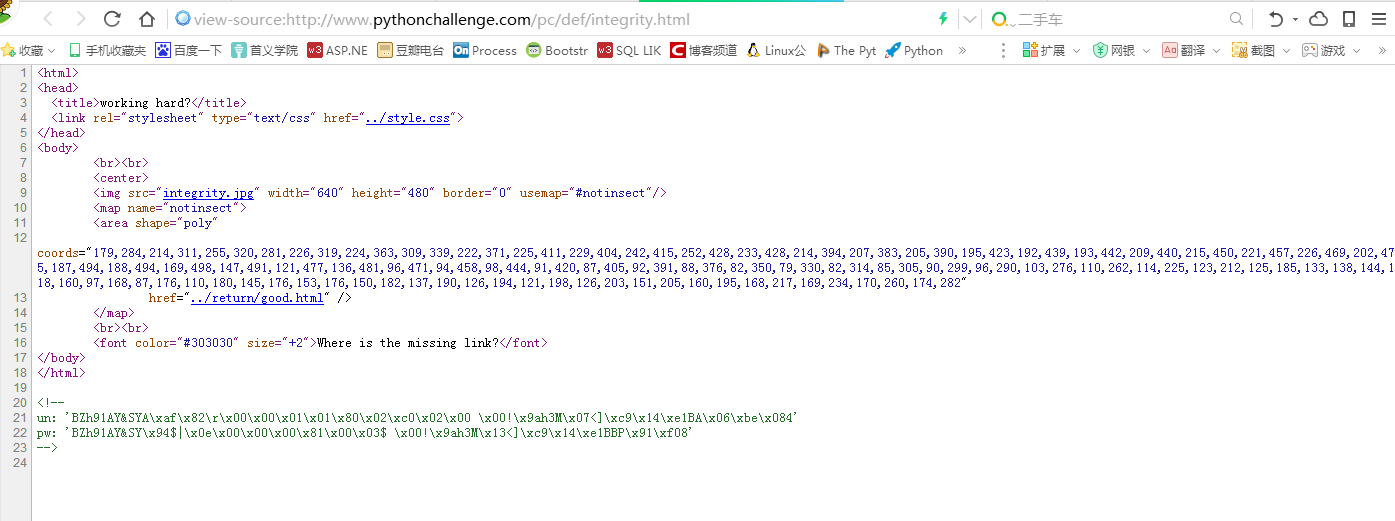
发现这个href=”../return/good.html”很奇怪
点击后跳转
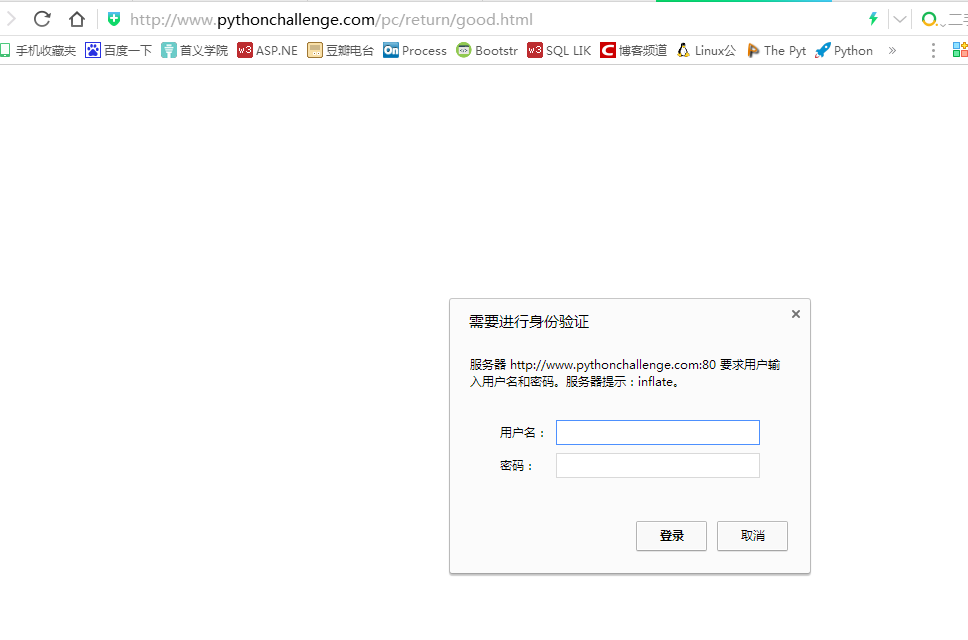
要我们输入用户名和密码。注意刚刚那个源码页面有这个

un(username):是账号 pw(password):是密码
发现这一串字符应该是按照某种规律进行了处理
在两行乱码中,寻找共同处,发现BZh91AY相同。百度后,得到这个是
实际上是bzip2算法的特征,相应的,’PK/x03/x04’ 是zip算法的特征,而’/x25/xD5/b/b ‘则是gzip算法的特征(均是压缩算法)
那么,此题考查的是bz2模块的运用
考察知识点
- python bz2模块
http://www.2cto.com/kf/201509/442875.html - using bz2.decompress in python
http://stackoverflow.com/questions/27503549/using-bz2-decompress-in-python-but-the-answers-different
代码及结果
import bz2
un = 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw = 'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'
print('username:'+bz2.decompress(un))
print('password:'+bz2.decompress(pw)) 输出:’huge’和’file’
通关。















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









