







系列文章目录
文章目录
前言
摘录自B站对应课程笔记
不愧是清华大佬!把Python网络爬虫讲得如此简单明了!从入门到精通保姆级教程(建议收藏)
以下是本篇文章正文内容,下面案例可供参考
一、下载文件和图片
Scrapy 为下载 item 中包含的文件(比如在爬取到产品时,同时也想保存对应的图片)提供了一个可重用的 item pipelines。这写 pipeline 有些共同的地方和结构(我们称之为 media pipeline)。一般来说你会使用 Files Pipelines 或是 Images Pipelines。
1、为什么要选择使用 scrapy 内置的下载文件的方法
1、避免重新下载最近已经下载过的文件。
2、可以方便的指定文件存储的路径。
3、可以将下载的图片转换成通用的格式。比如 png, jpg
4、可以方便的生成缩略图
5、可以方便的检测图片的宽和高,确保他们满足最小的限制。
6、异步下载,效率非常高。
2、下载文件的 Files Pipelines
当使用 Files Pipeliens 下载文件的时候,按照以下步骤来完成:
1、定义好一个 Item, 然后在这个 item 中定义两个属性,分别为 file_urls 以及 files, file_urls 是用来存储需要下载的图片的 url 链接,需要给一个列表。
2、当文件下载完成后,会把文件下载的相关信息存储到 item 的 files 属性中。比如下载路径, 下载的url和文件的校验码等。
3、在配置文件 setting.py 中配置 FILES_STORE ,这个配置是用来设置文件下载下来的路径。
4、启动 pipeline: 在文件 setting.py 中的 ITEM_PIPELINES 设置 scrapy.pipeline.files.FilesPipeline:1 。
3、下载图片的 Images Pipeline:
当使用 Images Pipeline 下载文件的时候,按照以下步骤来完成:
1、定义好一个 Item, 然后在这个 item 中定义两个属性,分别为 image_urls 以及 images 。image_urls 是用来存储需要下载的图片的url链接,需要给一个列表。
2、当文件下载完成后,会把文件下载的相关信息存储到 item 的 images 属性中。比如下载路径、下载的 url 和图片的校验等。
3、在配置文件 setting.py 中配置 IMAGES_STORE, 这个配置是用来设置图片下载下来的路径。
4、启动 pipeline : 在文件 setting.py 中的 ITEM_PIPELINES 设置 scrapy.pipeline.images.ImagesPipeline:1 。
4、汽车之家 CRV 图片下载实战
通过重写 ImagesPipeline 下载 CRV 这个款车的各类图片,代码如下:
setting.py
import os
BOT_NAME = 'crv'
SPIDER_MODULES = ['crv.spiders']
NEWSPIDER_MODULE = 'crv.spiders'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36',
}
ITEM_PIPELINES = {
'crv.pipelines.CrvImagesPipeline': 1,
}
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(os.path.abspath(__file__))), "images")
items.py
import scrapy
class CrvItem(scrapy.Item):
title = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
pipelines.py
import os
from crv import settings
from urllib import request
from scrapy.pipelines.images import ImagesPipeline
class CrvImagesPipeline(ImagesPipeline):
def file_path(self, request, response=None, info=None, *, item=None):
# 这个方法是在图片将要被存储的时候调用,来获取这个图片的存储路径。
category = item["title"]
category_path = os.path.join(settings.IMAGES_STORE, category)
image_name = request.url.split("_")[-1]
image_path = os.path.join(category_path, image_name)
print("image_path ; {}".format(image_path))
return image_path
crv_spider.py
import scrapy
from crv.items import CrvItem
class CrvSpiderSpider(scrapy.Spider):
name = 'crv_spider'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series-s46246/314.html#pvareaid=3454542']
def parse(self, response):
divs = response.xpath("//div[@class='column grid-16']/div")[2:] # 过滤掉1,2 行
for div in divs:
print(div.xpath(".//div[@class='uibox-title']"))
title = div.xpath(".//div[@class='uibox-title']/a/text()").get()
urls = div.xpath(".//ul/li/a/img/@src").getall()
urls = list(map(response.urljoin, urls))
item = CrvItem(title=title, image_urls=urls)
print(item)
yield item
二、下载中间件
下载器中间件是引擎和下载器之间通信的中间件。在这个中间件中我们可以设置代理、更换请求头等来达到反反爬虫的目的。要写下载器中间件,可以在下载器中实现两个方法。一个是 process_request(self, request, spider), 这个方法是在请求发送之前会执行,还有一个是 process_response(self, request, response, spider), 这个方法是数据下载到引擎之前执行。
1、process_request(self, request, spider)
这个方法是下载器在发送请求之前会执行的。一般可以在这个方法里面设置随机代理ip等
1、参数:
request:发送请求的 request对象
spider:发送请求的 spider对象
2、返回值:
返回Node :如果返回None,Scrapy 将继续处理该 request, 执行其他中间件中的相应方法,直到合适的下载器处理函数被调用。
返回Response对象 :Scrapy 将不会调用任何其他的 process_request 方法,将直接返回这个 response对象。已经激活的中间件的 process_response()方法则会在每个 response返回时被调用。
返回 Request对象 :不再使用之前的 request 对象去下载数据,而是根据现在返回的 request 对象返回数据。
如果这个方法中抛出了异常,则会调用 process_exception 方法。
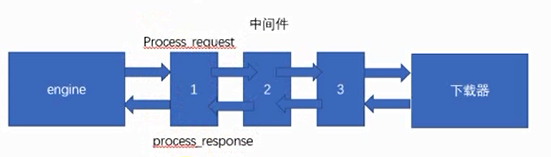
2、process_response(self, request, response, spider)
这个是下载器下载的数据到引擎中间会执行的方法。
1、参数:
request : request对象
response :被处理的 response对象
spider : spider对象
2、返回值:
返回Response对象: 会将这个新的 response 对象传给其他中间件,最终传给爬虫。
返回Request对象:下载器链接被切断,返回的 request 会重新被下载器调度下载。
如果抛出一个异常,那么调用 request 的 errback 方法,如果没有指定这个方法,那么会抛出一个异常
3、随机请求头中间件
爬虫在频繁访问一个页面的时候,这个请求头如果一直保持一致,那么很容易被服务器发现,从而禁止这个请求头的访问。因此我们要在访问这个页面之前随机的更改请求头吗,这样才可以避免爬虫被抓。
随机更改请求头,可以在下载中间件中实现。在请求发送给服务器之前,,随机的选择一个请求头。这样就可以避免总使用一个请求头了。示例代码如下:
setting.py
#打开中间件
DOWNLOADER_MIDDLEWARES = {
'useragent.middlewares.UseragentDownloaderMiddleware': 543,
}
middlewares.py
#随机选择请求头
class UseragentDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
USER_AGENT = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:82.0) Gecko/20100101 Firefox/82.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko",
]
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
user_agent = random.choice(self.USER_AGENT)
request.headers["User-Agent"] = user_agent
return None
httpbin.py
#拿到结果并打印
import scrapy
class HttpbinSpider(scrapy.Spider):
name = 'httpbin'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/user-agent']
def parse(self, response):
ua = response.json()
print("*" * 30)
print(ua)
print("*" * 30)
return scrapy.Request(self.start_urls[0], dont_filter=True)
4、ip代理池中间件
1、购买代理
- 芝麻代理 https://zhimahttp.com/
- 太阳代理 http://http.taiyangruanjian.com/
- 快代理 https://www.kuaidaili.com/
- 讯代理 https://jahttp.zhimaruanjian.com/
2、使用ip代理池
**setting.py **
#打开中间件
ITEM_PIPELINES = {
'useragent.pipelines.UseragentPipeline': 300,
}
middlewares.py
#随机选择请求头
class IpPorxyDownloaderMiddleware(object):
IPPROXY = [
"http://101.18.121.42:9999",
"http://175.44.108.56:9999",
"http://218.88.205.161:3256",
"http://114.99.9.251:1133",
]
def process_request(self, request, spider):
proxy = random.choice(self.IPPROXY)
request.meta['proxy'] = proxy
ipproxy.py
#拿到结果并打印
import scrapy
class IpproxySpider(scrapy.Spider):
name = 'ipproxy'
allowed_domains = ['httpbin.org']
start_urls = ['http://httpbin.org/ip']
def parse(self, response):
ua = response.json()
print("*" * 30)
print(ua)
print("*" * 30)
return scrapy.Request(self.start_urls[0], dont_filter=True)
# 使用的是免费代理,不是很稳定,没能获取到结果
3、独享代理池
使用快代理的测试
class IPProxyDownloadMiddleware(object):
def process_request(self, request,spider):
proxy = '111.111.222.222:8080'
user_password = "123123123:kod231"
request.meta["proxy"] = proxy
#bytes
b64_user_password = base64.b64encode(user_password.encode('utf-8'))
request.headers["Proxy-Authorization"] = "Basic" + b64_user_password.decode('utf-8')
















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











