









损失函数在网络中的作用:
1.计算实际输出和目标之间的差距。
2.为我们更新输出提供一定的依据(反向传播) 。
“损失”什么意思呢? 就是我们的预测值与真实的偏差。损失函数是对这种偏差程度的计算方法。损失函数计算出来的值应当越小网络越好。

一、L1Loss
最简单的L1Loss函数的使用:
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
参数默认即可。
- reduction=“mean” 作用是做预测数据与真实数据做差取平均。reduction="sum"仅计算不取平均
主要为使用时的参数形状需要自己注意修改:
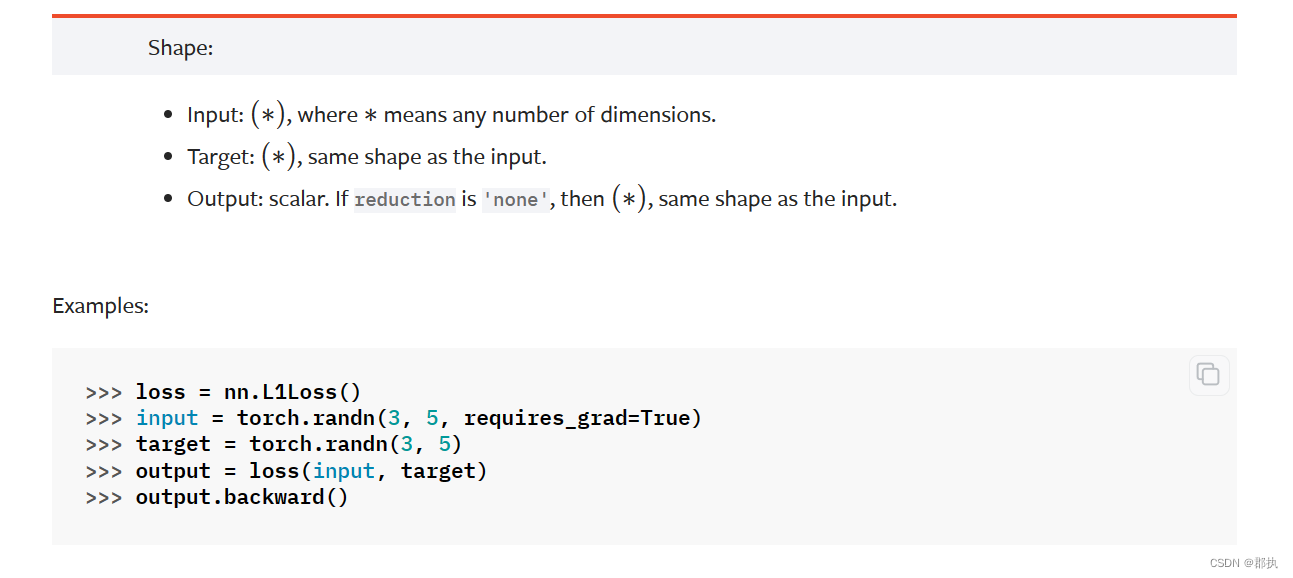
import torch
from torch.nn import L1Loss
input = torch.tensor([1, 2, 3], dtype=torch.float32)
target = torch.tensor([1, 2, 5], dtype=torch.float32)
input = torch.reshape(input, (1, 1, 1, 3))
target = torch.reshape(target, (1, 1, 1, 3))
loss = L1Loss(reduction="sum")
result = loss(input, target)
print(result)
结果:
tensor(0.667)
or
tensor(2.)
二、MSELoss
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
和上述相同,主要为计算两者误差的平方差取平均。
- reduction 可以为mean或sum

loss_mse = MSELoss()
result_mse = loss_mse(input,target)
print(result_mse)
结果:
tensor(1.333)
or reduction="sum"时:
tensor(4.)
三、CrossEntropyLoss
交叉熵损失。主要解决分类问题的损失计算。
l
o
s
s
(
x
,
c
l
a
s
s
)
=
−
log
(
exp
(
x
[
c
l
a
s
s
]
)
∑
j
exp
(
x
[
j
]
)
)
=
−
x
[
c
l
a
s
s
]
+
log
(
∑
j
exp
(
x
[
j
]
)
)
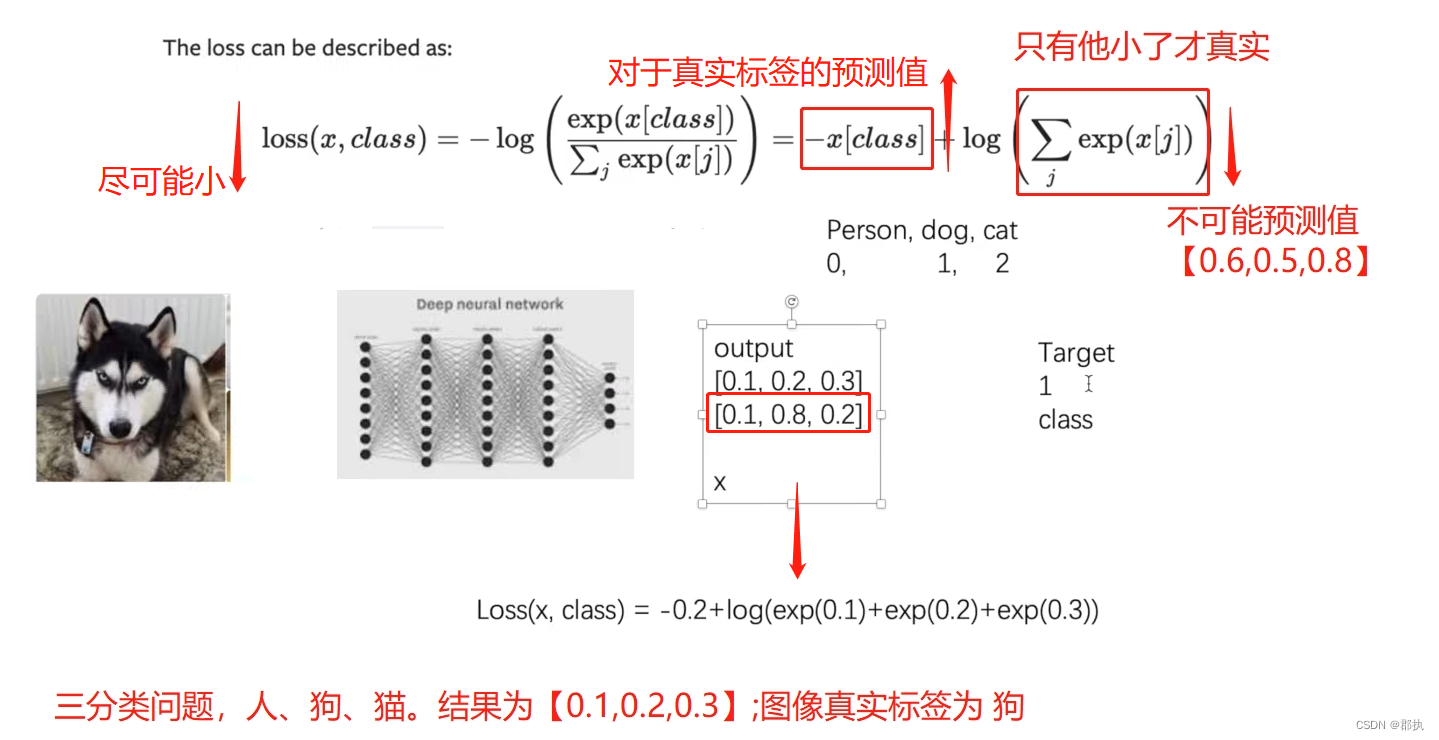
\mathrm{loss}(x,class)=-\log\left(\frac{\exp(x[class])}{\sum_j\exp(x[j])}\right)=-x[class]+\log\left(\sum_j\exp(x[j])\right)
loss(x,class)=−log(∑jexp(x[j])exp(x[class]))=−x[class]+log(j∑exp(x[j]))
公式解释:
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=- 100, reduce=None, reduction='mean', label_smoothing=0.0)

x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
# 调整为参数所需要的结构 N对应batchsize、C对应类别
x = torch.reshape(x, (1, 3))
loss_cross = CrossEntropyLoss()
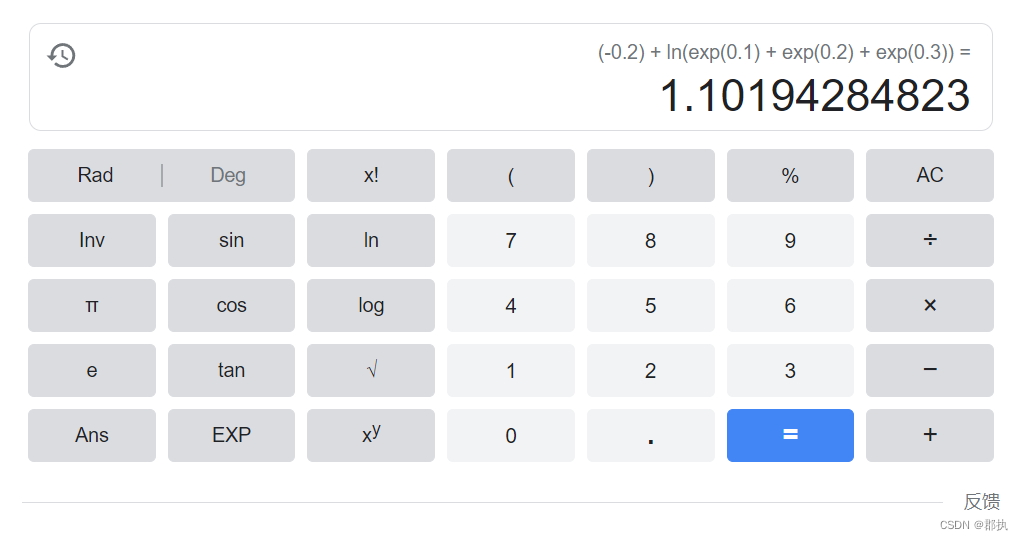
result_cross = loss_cross(x, y)
print(result_cross)
结果:
tensor(1.1019)
CIFRA10神经网络分类的实现
- 使用上一节Sequential中创建的神经网络,传入数据进行预测得到:
- 根据预测结果与实际的类别进行选择合适的损失函数进行修正。
import torchvision.datasets
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
"""
本节接着上面创建的10分类网络去实现自己真实的第一个分类网络!
并能够根据预测结果选择合适的损失函数。
利用损失函数进行一个前向传播进行一个修正卷积进行再次计算。
"""
dataset = torchvision.datasets.CIFAR10("../DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=1)
class MyModule(nn.Module):
def __init__(self):
super().__init__()
self.module1 = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.module1(x)
return x
# 配置交叉熵
loss = nn.CrossEntropyLoss()
mymodule = MyModule()
i = 0
for data in dataloader:
imgs, target = data
outputs = mymodule(imgs)
# print(outputs)
# print(target)
result_loss=loss(outputs,target)
# 反向传播使用loss求完后的数据
result_loss.backward()
print(result_loss)
if i < 0:
break
else:
i -= 1
预测结果与原标签打印:
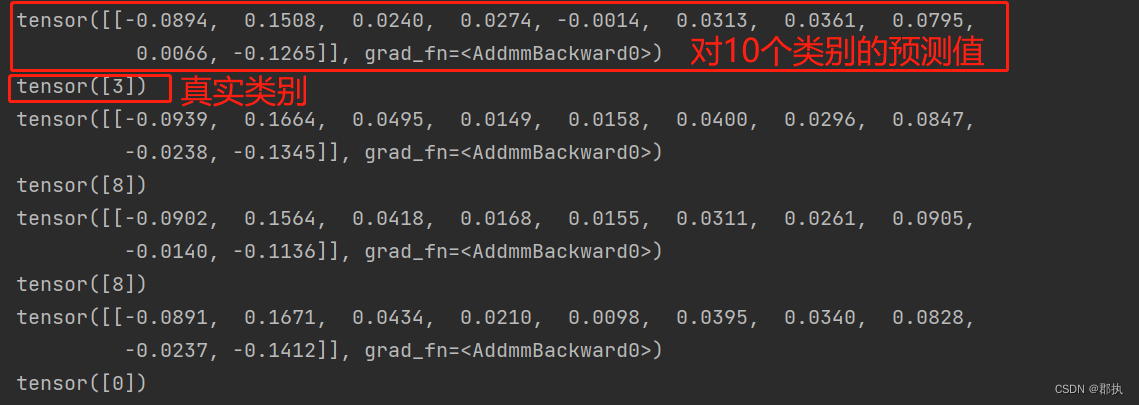
添加损失函数观测出其实际输出与目标之间的差距。

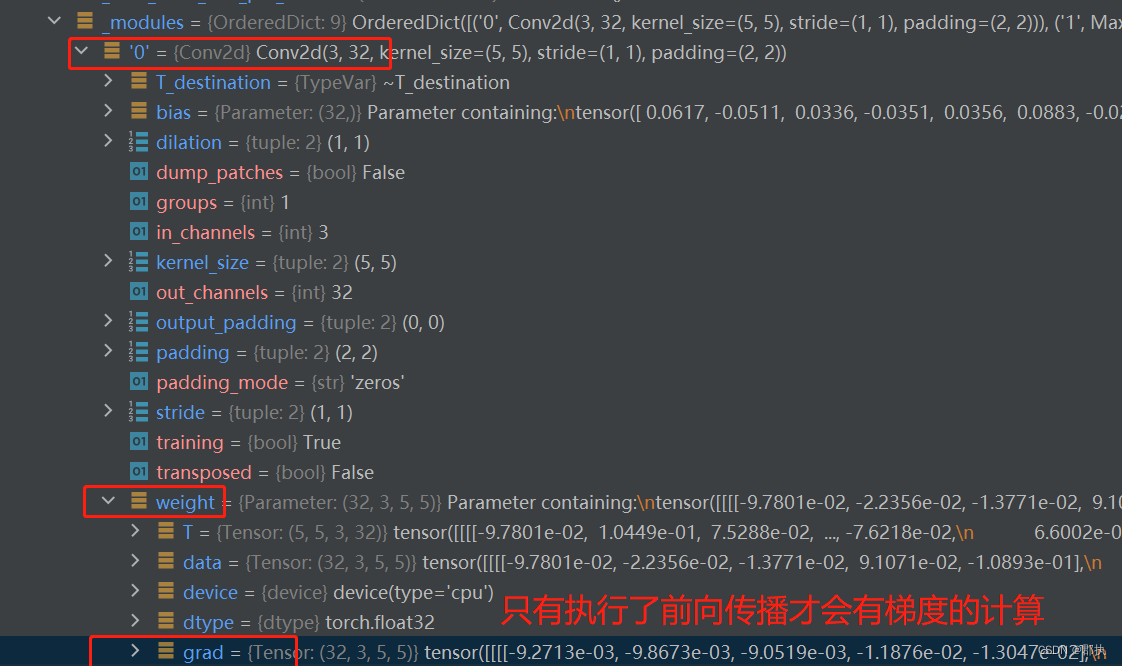
反向传播
即在得到损失函数会对
- 网络中卷积层卷积核中的参数进行变化 一般设置一个grad梯度
- 每个结点每一个要更新的参数都会计算一个梯度。修改参数到达对损失函数降低的作用。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









