







GRAPH ATTENTION NETWORKS图注意力网络 代码详解
代码地址: https://github.com/Diego999/pyGAT
csdn加速后:https://codechina.csdn.net/mirrors/diego999/pygat?utm_source=csdn_github_accelerator
图注意力机制神经网络基本原理和代码解读
readme
Pytorch Graph Attention Network
This is a pytorch implementation of the Graph Attention Network (GAT) model presented by Veličković et. al (2017, https://arxiv.org/abs/1710.10903).
The branch master contains the implementation from the paper.
The branch similar_impl_tensorflow the implementation from the official Tensorflow repository.
Performances
For the branch master, the training of the transductive learning on Cora task on a Titan Xp takes ~0.9 sec per epoch and 10-15 minutes for the whole training (~800 epochs). The final accuracy is between 84.2 and 85.3 (obtained on 5 different runs).
For the branch similar_impl_tensorflow, the training takes less than 1 minute and reach ~83.0.
Sparse version GAT
We develop a sparse version GAT using pytorch.
There are numerically instability because of softmax function.
Therefore, you need to initialize carefully.
To use sparse version GAT, add flag --sparse.
The performance of sparse version is similar with tensorflow.
On a Titan Xp takes 0.08~0.14 sec.
Requirements
pyGAT relies on Python 3.5 and PyTorch 0.4.1 (due to torch.sparse_coo_tensor).
Issues/Pull Requests/Feedbacks
Don’t hesitate to contact for any feedback or create issues/pull requests.
补充知识
scipy.sparse的一些整理
numpy.genfromtxt读取本地文件
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset), dtype=np.dtype(str))
第一项为 要读取的文件,文件名,列表或生成器
dtype转换数据类型, 不设置dtype,输出数据类型为nan
delimiter=’,'表示数据由逗号分隔
skip_header关键字可以设置为整数,表示跳过文件开头对应的行数
csr_matrix压缩稀疏矩阵
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
np.identity(n, dtype=None)生成方阵
获取方阵,也即标准意义的单位阵
返回的是nxn的主对角线为1,其余地方为0的数组
{c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)}
生成对应 class 的 独热码
map(func, seq1[, seq2,…]) 对seq运用fun
map(classes_dict.get, labels)
将函数func作用于这个seq的每个元素上,并得到一个新的seq
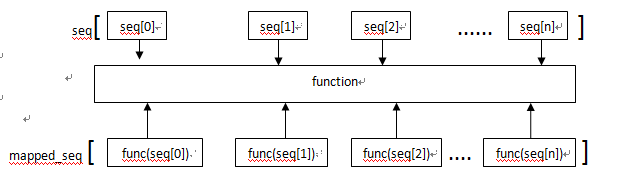
函数func函数会作用于seq中的每个元素,得到func(seq[n])组成的列表
把字典get这个功能对labels使用 相当于获得 key为label 获得的value
.flatten()折叠成一维的数组
返回一个折叠成一维的数组。但是该函数只能适用于numpy对象,即array或者mat,普通的list列表是不行的。a是个矩阵或者数组,a.flatten()就是把a降到一维,默认是按横的方向降
eg:
>>> a
array([[1, 2],
[3, 4],
[5, 6]])
>>> a.flatten()
array([1, 2, 3, 4, 5, 6])
sp.coo_matrix 采用三元组(row, col, data)的形式存储稀疏邻接矩阵
n行,m列存了data[i],其余位置皆为0.
>>> from scipy.sparse import coo_matrix
>>> coo_matrix((3, 4), dtype=np.int8).toarray()
array([[0, 0, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 0]], dtype=int8)
>>>
>>> row = np.array([0, 3, 1, 0])
>>> col = np.array([0, 3, 1, 2])
>>> data = np.array([4, 5, 7, 9])
>>> coo_matrix((data, (row, col)), shape=(4, 4)).toarray()
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
建立对称邻接矩阵(有向图转无向图)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
计算例子:
sp.eye 生成单位矩阵
from scipy import *
print "--------------3x3 对角为1的矩阵,元素的类型默认为 整型------------------"
print eye(3)
print "--------------3x3 对角为1的float矩阵------------------"
print eye(3,3)
print "--------------3x4 对角为1的矩阵------------------"
print eye(3,4)
print "--------------3x4 对角为1的矩阵------------------"
print eye(3,4,0)
print "--------------3x3 从第二列对角为1的矩阵------------------"
print eye(3,4,1)
print "--------------3x3 从第三列对角为1的矩阵------------------"
print eye(3,4,2)
--------------3x3 从第三列对角为1的矩阵------------------
[[ 0. 0. 1. 0.]
[ 0. 0. 0. 1.]
[ 0. 0. 0. 0.]]
print "--------------3x3 从第四列对角为1的矩阵------------------"
print eye(3,4,3)
print "--------------3x3 对角为1的矩阵,元素的类型为 int 整型------------------"
print eye(3,3,0,dtype=int)
print "--------------3x3 对角为1的矩阵,元素的类型为 float 整型------------------"
print eye(3,3,0,dtype=float)
sp.diags 生成对角矩阵
from scipy.sparse import diags
>>> diagonals = [[1, 2, 3, 4], [1, 2, 3], [1, 2]]
# 使用diags函数,该函数的第二个变量为对角矩阵的偏移量,
0:代表不偏移,就是(0,0)(1,1)(2,2)(3,3)...这样的方式写
k:正数:代表像正对角线的斜上方偏移k个单位的那一列对角线上的元素。
-k:负数,代表向正对角线的斜下方便宜k个单位的那一列对角线上的元素,
由此看下边输出
>>> diags(diagonals, [0, -1, 2]).toarray()
array([[1, 0, 1, 0],
[1, 2, 0, 2],
[0, 2, 3, 0],
[0, 0, 3, 4]])
Broadcasting of scalars is supported (but shape needs to be
specified):
>>> diags([1, -2, 1], [-1, 0, 1], shape=(4, 4)).toarray()
array([[-2., 1., 0., 0.],
[ 1., -2., 1., 0.],
[ 0., 1., -2., 1.],
[ 0., 0., 1., -2.]])
If only one diagonal is wanted (as in `numpy.diag`), the following
works as well:
>>> diags([1, 2, 3], 1).toarray()
array([[ 0., 1., 0., 0.],
[ 0., 0., 2., 0.],
[ 0., 0., 0., 3.],
[ 0., 0., 0., 0.]])
GCN之邻接矩阵标准化
torch.nn.init.xavier_uniform_
torch.nn.init.xavier_uniform_是一个服从均匀分布的Glorot初始化器
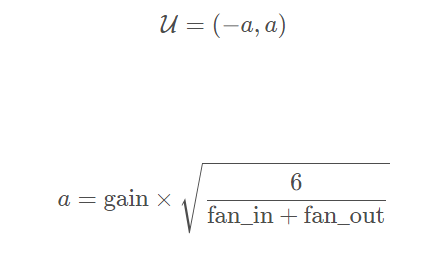
pygat-master
参考资料 pytorch框架下—GCN代码详细解读
data-cora数据集介绍
readme
This directory contains the a selection of the Cora dataset (www.research.whizbang.com/data).
该目录包含Cora数据集的选择
The Cora dataset consists of Machine Learning papers.
Cora数据集由机器学习论文组成
These papers are classified into one of the following seven classes
这些论文分为以下七个类别之一:
Case_Based基于案例的
Genetic_Algorithms遗传算法
Neural_Networks神经网络
Probabilistic_Methods概率方法
Reinforcement_Learning强化学习
Rule_Learning规则学习
Theory理论
The papers were selected in a way such that in the final corpus every paper cites or is cited by atleast one other paper. There are 2708 papers in the whole corpus.
论文的选择方式是,在最终的语料库中,每一篇论文都引用或被至少一篇其他论文引用。全文共有2708篇论文。
After stemming and removing stopwords we were left with a vocabulary of size 1433 unique words. All words with document frequency less than 10 were removed.
在词干和删除停止词之后,我们留下了一个1433个独特单词的词汇表。所有文档频率小于10的单词都被删除
THE DIRECTORY CONTAINS TWO FILES:
该目录包含两个文件
.content file
The .content file contains descriptions of the papers in the following format:
.content文件包含以下格式的论文描述
<paper_id> <word_attributes>+ <class_label>
The first entry in each line contains the unique string ID of the paper followed by binary values indicating whether each word in the vocabulary is present (indicated by 1) or absent (indicated by 0) in the paper. Finally, the last entry in the line contains the class label of the paper.
每行中的第一个条目包含论文的唯一字符串ID,后面是二进制值,指示词汇表中的每个单词是存在(用1表示)还是不存在(用0表示)。最后,行中的最后一个条目包含论文的类标签
.cites file
The .cites file contains the citation graph of the corpus. Each line describes a link in the following format:
.cites文件包含语料库的引用图。每一行以下列格式描述一个链接
<ID of cited paper> <ID of citing paper>
Each line contains two paper IDs. The first entry is the ID of the paper being cited and the second ID stands for the paper which contains the citation. The direction of the link is from right to left. If a line is represented by "paper1 paper2" then the link is "paper2->paper1".
每行包含两个paper ID。第一个条目是被引用论文的ID,第二个ID代表包含引文的论文。链接的方向是从右到左。如果一条线用“paper1 paper2”表示,则链接为“paper2 ->paper1”。
train.py
from __future__ import division
from __future__ import print_function
import os
import glob
import time
import random
import argparse
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from utils import load_data, accuracy
from models import GAT, SpGAT
# Training settings
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False, help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False, help='Validate during training pass.')
parser.add_argument('--sparse', action='store_true', default=False, help='GAT with sparse version or not.')
parser.add_argument('--seed', type=int, default=72, help='Random seed.')
parser.add_argument('--epochs', type=int, default=10000, help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.005, help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4, help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=8, help='Number of hidden units.')
parser.add_argument('--nb_heads', type=int, default=8, help='Number of head attentions.')
parser.add_argument('--dropout', type=float, default=0.6, help='Dropout rate (1 - keep probability).')
parser.add_argument('--alpha', type=float, default=0.2, help='Alpha for the leaky_relu.')
parser.add_argument('--patience', type=int, default=100, help='Patience')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
# 同时满足
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
# Load data
adj, features, labels, idx_train, idx_val, idx_test = load_data()
# Model and optimizer
if args.sparse:
model = SpGAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
else:
model = GAT(nfeat=features.shape[1],
nhid=args.hidden,
nclass=int(labels.max()) + 1,
dropout=args.dropout,
nheads=args.nb_heads,
alpha=args.alpha)
optimizer = optim.Adam(model.parameters(),
lr=args.lr,
weight_decay=args.weight_decay)
if args.cuda:
model.cuda()
features = features.cuda()
adj = adj.cuda()
labels = labels.cuda()
idx_train = idx_train.cuda()
idx_val = idx_val.cuda()
idx_test = idx_test.cuda()
features, adj, labels = Variable(features), Variable(adj), Variable(labels)
train
def train(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(features, adj)
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
#NLLLoss 负对数似然损失函数,用于处理多分类问题,输入是对数化的概率值。
acc_train = accuracy(output[idx_train], labels[idx_train])
loss_train.backward()
optimizer.step()
if not args.fastmode:
# Evaluate validation set performance separately,分离评估验证集的性能
# deactivates dropout during validation run.在验证运行期间禁用dropout 。
model.eval()
output = model(features, adj)
loss_val = F.nll_loss(output[idx_val], labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss_train.data.item()),
'acc_train: {:.4f}'.format(acc_train.data.item()),
'loss_val: {:.4f}'.format(loss_val.data.item()),
'acc_val: {:.4f}'.format(acc_val.data.item()),
'time: {:.4f}s'.format(time.time() - t))
return loss_val.data.item()
compute_test()
def compute_test():
model.eval()
output = model(features, adj)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.data.item()),
"accuracy= {:.4f}".format(acc_test.data.item()))
Train model
t_total = time.time()
loss_values = []
bad_counter = 0
best = args.epochs + 1
best_epoch = 0
for epoch in range(args.epochs):
loss_values.append(train(epoch))
torch.save(model.state_dict(), '{}.pkl'.format(epoch))
if loss_values[-1] < best:
best = loss_values[-1]
best_epoch = epoch
bad_counter = 0
else:
bad_counter += 1
if bad_counter == args.patience:
break
#删除储存的多余pkl
files = glob.glob('*.pkl') #* 返回当前路径下的所有pkl文件路径
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb < best_epoch:
os.remove(file)
#只保留best
files = glob.glob('*.pkl')
for file in files:
epoch_nb = int(file.split('.')[0])
if epoch_nb > best_epoch:
os.remove(file)
print("Optimization Finished!")
print("Total time elapsed: {:.4f}s".format(time.time() - t_total))
# Restore best model
print('Loading {}th epoch'.format(best_epoch))
model.load_state_dict(torch.load('{}.pkl'.format(best_epoch)))
# Testing
compute_test()
utils.py
import numpy as np
import scipy.sparse as sp
import torch
encode_onehot
def encode_onehot(labels):
# The classes must be sorted before encoding to enable static class encoding.必须在编码之前对类进行排序,以启用静态类编码
# In other words, make sure the first class always maps to index 0.换句话说,确保第一类始终映射到索引0
classes = sorted(list(set(labels)))
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in enumerate(classes)} #变成独热码
labels_onehot = np.array(list(map(classes_dict.get, labels)), dtype=np.int32)
return labels_onehot
load_data
def load_data(path="./data/cora/", dataset="cora"):
"""Load citation network dataset (cora only for now)"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset), dtype=np.dtype(str))
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32)
labels = encode_onehot(idx_features_labels[:, -1])#最后一列为label
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32) #第一列
idx_map = {j: i for i, j in enumerate(idx)} #idx值对应排序序号
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset), dtype=np.int32) #第一列是被引用 第二列是引用 的idx
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())), dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), shape=(labels.shape[0], labels.shape[0]), dtype=np.float32)
# build symmetric adjacency matrix 建立对称邻接矩阵
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj) #公式
features = normalize_features(features)
adj = normalize_adj(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
adj = torch.FloatTensor(np.array(adj.todense()))
#todense([order, out]):返回稀疏矩阵的np.matrix形式
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
#np.where()[0] 表示行索引,np.where()[1]表示列索引
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
normalize_adj 、normalize_features
def normalize_adj(mx):
"""Row-normalize sparse matrix 行规范化稀疏矩阵"""
rowsum = np.array(mx.sum(1))
r_inv_sqrt = np.power(rowsum, -0.5).flatten()
r_inv_sqrt[np.isinf(r_inv_sqrt)] = 0.
r_mat_inv_sqrt = sp.diags(r_inv_sqrt)
return mx.dot(r_mat_inv_sqrt).transpose().dot(r_mat_inv_sqrt)
def normalize_features(mx):
"""Row-normalize sparse matrix"""
rowsum = np.array(mx.sum(1)) #求行和
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
accuracy
def accuracy(output, labels):
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
layers.py
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
GraphAttentionLayer

class GraphAttentionLayer(nn.Module):
"""
Simple GAT layer, similar to https://arxiv.org/abs/1710.10903
带有attention计算的网络层
参数:in_features 输入节点的特征数F
参数:out_features 输出的节点的特征数F'
参数:dropout
参数:alpha LeakyRelu激活函数的斜率
参数:concat
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(GraphAttentionLayer, self).__init__()
self.dropout = dropout
self.in_features = in_features #输入特征数
self.out_features = out_features #输出特征数
self.alpha = alpha # 激活斜率 (LeakyReLU)的激活斜率
self.concat = concat #用来判断是不是最后一个attention # if this layer is not last layer,
self.W = nn.Parameter(torch.empty(size=(in_features, out_features))) #建立一个w权重,用于对特征数F进行线性变化
nn.init.xavier_uniform_(self.W.data, gain=1.414)#对权重矩阵进行初始化 服从均匀分布的Glorot初始化器
self.a = nn.Parameter(torch.empty(size=(2*out_features, 1))) #计算函数α,输入是上一层两个输出的拼接,输出的是eij,a的size为(2*F',1)
nn.init.xavier_uniform_(self.a.data, gain=1.414)
self.leakyrelu = nn.LeakyReLU(self.alpha) #激活层
#前向传播过程
def forward(self, h, adj):
'''
参数h:表示输入的各个节点的特征矩阵
参数adj :表示邻接矩阵
'''
Wh = torch.mm(h, self.W) # h.shape: (N, in_features), Wh.shape: (N, out_features)
#线性变化特征的过程,Wh的size为(N,F'),N表示节点的数量,F‘表示输出的节点的特征的数量
e = self._prepare_attentional_mechanism_input(Wh)
zero_vec = -9e15*torch.ones_like(e) #生成一个矩阵,size为(N,N)
attention = torch.where(adj > 0, e, zero_vec)
#对于邻接矩阵中的元素,>0说明两种之间有边连接,就用e中的权值,否则表示没有边连接,就用一个默认值来表示
attention = F.softmax(attention, dim=1)
#做一个softmax,生成贡献度权重
attention = F.dropout(attention, self.dropout, training=self.training)
#根据权重计算最终的特征输出。
h_prime = torch.matmul(attention, Wh)
if self.concat:
return F.elu(h_prime) #做一次激活
else:
return h_prime
def _prepare_attentional_mechanism_input(self, Wh):
'''
#下面是self-attention input ,构建自我的特征矩阵
#matmul 的size为(N,1)表示eij对应的数值
#e的size为(N,N),每一行表示一个节点,其他各个节点对该行的贡献度
'''
# Wh.shape (N, out_feature)
# self.a.shape (2 * out_feature, 1)
# Wh1&2.shape (N, 1)
# e.shape (N, N)
Wh1 = torch.matmul(Wh, self.a[:self.out_features, :]) #矩阵乘法
Wh2 = torch.matmul(Wh, self.a[self.out_features:, :])
# broadcast add
e = Wh1 + Wh2.T
return self.leakyrelu(e)
#打印输出类名称,输入特征数量,输出特征数量
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
SpecialSpmmFunction 对稀疏区域的反向传播函数
class SpecialSpmmFunction(torch.autograd.Function):
"""Special function for only sparse region backpropataion layer.对稀疏区域的反向传播函数"""
@staticmethod
def forward(ctx, indices, values, shape, b):
assert indices.requires_grad == False
a = torch.sparse_coo_tensor(indices, values, shape)
ctx.save_for_backward(a, b)
ctx.N = shape[0]
return torch.matmul(a, b)
@staticmethod
def backward(ctx, grad_output):
a, b = ctx.saved_tensors
grad_values = grad_b = None
if ctx.needs_input_grad[1]:
grad_a_dense = grad_output.matmul(b.t())
edge_idx = a._indices()[0, :] * ctx.N + a._indices()[1, :]
grad_values = grad_a_dense.view(-1)[edge_idx]
if ctx.needs_input_grad[3]:
grad_b = a.t().matmul(grad_output)
return None, grad_values, None, grad_b
SpecialSpmm
class SpecialSpmm(nn.Module):
def forward(self, indices, values, shape, b):
return SpecialSpmmFunction.apply(indices, values, shape, b)
SpGraphAttentionLayer
class SpGraphAttentionLayer(nn.Module):
"""
Sparse version GAT layer, similar to https://arxiv.org/abs/1710.10903
"""
def __init__(self, in_features, out_features, dropout, alpha, concat=True):
super(SpGraphAttentionLayer, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.alpha = alpha
self.concat = concat
self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))
nn.init.xavier_normal_(self.W.data, gain=1.414)
self.a = nn.Parameter(torch.zeros(size=(1, 2*out_features)))
nn.init.xavier_normal_(self.a.data, gain=1.414)
self.dropout = nn.Dropout(dropout)
self.leakyrelu = nn.LeakyReLU(self.alpha)
self.special_spmm = SpecialSpmm()
def forward(self, input, adj):
dv = 'cuda' if input.is_cuda else 'cpu'
N = input.size()[0]
edge = adj.nonzero().t()
h = torch.mm(input, self.W)
# h: N x out
assert not torch.isnan(h).any()
# Self-attention on the nodes - Shared attention mechanism
edge_h = torch.cat((h[edge[0, :], :], h[edge[1, :], :]), dim=1).t()
# edge: 2*D x E
edge_e = torch.exp(-self.leakyrelu(self.a.mm(edge_h).squeeze()))
assert not torch.isnan(edge_e).any()
# edge_e: E
e_rowsum = self.special_spmm(edge, edge_e, torch.Size([N, N]), torch.ones(size=(N,1), device=dv))
# e_rowsum: N x 1
edge_e = self.dropout(edge_e)
# edge_e: E
h_prime = self.special_spmm(edge, edge_e, torch.Size([N, N]), h)
assert not torch.isnan(h_prime).any()
# h_prime: N x out
h_prime = h_prime.div(e_rowsum)
# h_prime: N x out
assert not torch.isnan(h_prime).any()
if self.concat:
# if this layer is not last layer,
return F.elu(h_prime)
else:
# if this layer is last layer,
return h_prime
def __repr__(self):
return self.__class__.__name__ + ' (' + str(self.in_features) + ' -> ' + str(self.out_features) + ')'
models.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from layers import GraphAttentionLayer, SpGraphAttentionLayer
class GAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
"""Dense version of GAT."""
"""
参数1 :nfeat 输入层数量
参数2: nhid 输出特征数量
参数3: nclass 分类个数
参数4: dropout dropout概率
参数5: alpha 激活函数的斜率
参数6: nheads 多头部分
"""
super(GAT, self).__init__()
self.dropout = dropout
self.attentions = [GraphAttentionLayer(nfeat, nhid, dropout=dropout, alpha=alpha, concat=True) for _ in range(nheads)]
#根据多头部分给定的数量声明attention的数量
#将多头的各个attention作为子模块添加到当前模块中
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
#最后一个attention层,输出的是分类
self.out_att = GraphAttentionLayer(nhid * nheads, nclass, dropout=dropout, alpha=alpha, concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj))
return F.log_softmax(x, dim=1)
class SpGAT(nn.Module):
def __init__(self, nfeat, nhid, nclass, dropout, alpha, nheads):
"""Sparse version of GAT."""
super(SpGAT, self).__init__()
self.dropout = dropout
self.attentions = [SpGraphAttentionLayer(nfeat,
nhid,
dropout=dropout,
alpha=alpha,
concat=True) for _ in range(nheads)]
for i, attention in enumerate(self.attentions):
self.add_module('attention_{}'.format(i), attention)
self.out_att = SpGraphAttentionLayer(nhid * nheads,
nclass,
dropout=dropout,
alpha=alpha,
concat=False)
def forward(self, x, adj):
x = F.dropout(x, self.dropout, training=self.training)
x = torch.cat([att(x, adj) for att in self.attentions], dim=1)
x = F.dropout(x, self.dropout, training=self.training)
x = F.elu(self.out_att(x, adj))
return F.log_softmax(x, dim=1)
visualize_graph.py
from graphviz import Digraph
import torch
import models
def make_dot(var, params):
""" Produces Graphviz representation of PyTorch autograd graph
Blue nodes are the Variables that require grad, orange are Tensors
saved for backward in torch.autograd.Function
Args:
var: output Variable
params: dict of (name, Variable) to add names to node that
require grad (TODO: make optional)
"""
param_map = {id(v): k for k, v in params.items()}
print(param_map)
node_attr = dict(style='filled',
shape='box',
align='left',
fontsize='12',
ranksep='0.1',
height='0.2')
dot = Digraph(node_attr=node_attr, graph_attr=dict(size="12,12"))
seen = set()
def size_to_str(size):
return '('+(', ').join(['%d'% v for v in size])+')'
def add_nodes(var):
if var not in seen:
if torch.is_tensor(var):
dot.node(str(id(var)), size_to_str(var.size()), fillcolor='orange')
elif hasattr(var, 'variable'):
u = var.variable
node_name = '%s\n %s' % (param_map.get(id(u)), size_to_str(u.size()))
dot.node(str(id(var)), node_name, fillcolor='lightblue')
else:
dot.node(str(id(var)), str(type(var).__name__))
seen.add(var)
if hasattr(var, 'next_functions'):
for u in var.next_functions:
if u[0] is not None:
dot.edge(str(id(u[0])), str(id(var)))
add_nodes(u[0])
if hasattr(var, 'saved_tensors'):
for t in var.saved_tensors:
dot.edge(str(id(t)), str(id(var)))
add_nodes(t)
add_nodes(var.grad_fn)
return dot
inputs = torch.randn(100, 50).cuda()
adj = torch.randn(100, 100).cuda()
model = models.SpGAT(50, 8, 7, 0.5, 0.01, 3)
model = model.cuda()
y = model(inputs, adj)
g = make_dot(y, model.state_dict())
g.view()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









