










 这篇论文介绍了一种新的多分辨率哈希编码技术,用于加速神经图形基元的训练和渲染。通过使用可训练的特征向量数组,该方法能够在不牺牲质量的情况下显著减少浮点运算和内存访问,适用于图像合成、神经符号距离函数、神经辐射缓存和NeRF等多个任务。编码的自适应性和并行性使其在GPU上实现快速训练和渲染,能够在几秒钟内训练出高质量的模型。
这篇论文介绍了一种新的多分辨率哈希编码技术,用于加速神经图形基元的训练和渲染。通过使用可训练的特征向量数组,该方法能够在不牺牲质量的情况下显著减少浮点运算和内存访问,适用于图像合成、神经符号距离函数、神经辐射缓存和NeRF等多个任务。编码的自适应性和并行性使其在GPU上实现快速训练和渲染,能够在几秒钟内训练出高质量的模型。
目录
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
3 MULTIRESOLUTION HASH ENCODING
5.1 Gigapixel Image Approximation
5.4 Neural Radiance and Density Fields (NeRF)
Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
基于多分辨率哈希编码的即时神经图形基元
论文地址:https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
项目地址:https://github.com/NVlabs/instant-ngp
项目主页:https://nvlabs.github.io/instant-ngp/

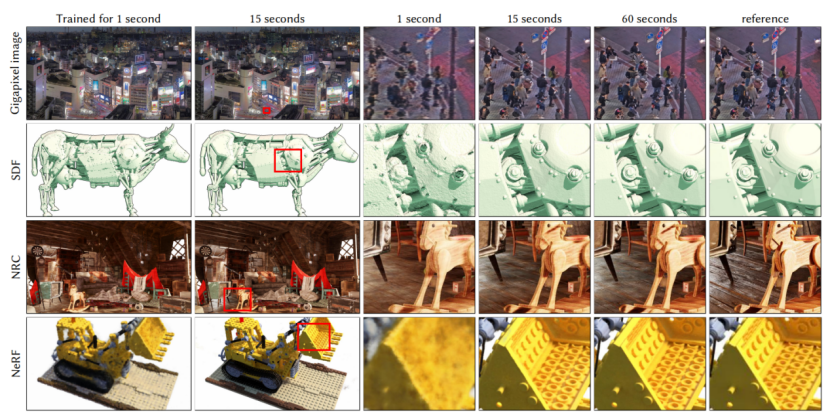 图1。我们演示了在一个GPU上对多个任务进行神经图形基元的即时训练。在千亿像素的图像中,
图1。我们演示了在一个GPU上对多个任务进行神经图形基元的即时训练。在千亿像素的图像中,
我们用神经网络表示一个十亿像素的图像。SDF在三维空间中学习一个有符号的距离函数,其零水平集代表一个二维曲面。神经辐射缓存(NRC)[Mulleretal.2021]采用了一种经过实时训练的神经网络,该神经网络可以缓存昂贵的照明计算。最后,NeRF[Mildenhall等人2020]使用2维图像及其相机姿态重建体积辐射和密度场,该场使用ray marching可视化。在所有任务中,我们的编码及其高效实现都提供了明显的好处:快速训练、高质量和简单性。我们的编码是与任务无关的:我们在所有任务中使用相同的实现和超参数,并且只改变哈希表的大小,从而权衡质量和性能。照片©TrevorDobson(CCBY-NC-ND2.0)
由完全连接的神经网络参数化的神经图形基元,进行训练和评估的成本很高。我们通过一种通用的新输入编码versatile new input encoding来降低这一成本,它允许在不牺牲质量的情况下使用一个更小的网络,从而显著减少了浮点运算和内存访问操作的数量:一个小的神经网络由可训练特征向量的多分辨率哈希表multiresolution hash table来增强,其值通过随机梯度下降进行优化。多分辨率结构允许网络消除哈希碰撞的歧义 disambiguate hash collisions,创建一个易于在现代gpus上并行化的简单架构。我们利用这种并行性通过使用完全融合的CUDA内核fully-fused CUDA kernels来实现整个系统来,其重点是最小化浪费的带宽和计算操作。我们实现了几个数量级的综合加速,使我们能够在几秒钟内训练高质量的神经图形基元,并在1920×1080的分辨率下在10毫秒内进行渲染。
附加的关键字和短语:图像合成,神经网络,编码,哈希,gpu,并行计算,函数近似
1 INTRODUCTION
计算机图形基元Computer graphics primitives基本上由参数化外观parameterize appearance的数学函数表示。数学表示的质量和性能特征对于视觉保真度至关重要:我们希望表示能够保持快速和紧凑,同时捕获高频、局部细节。由多层感知器(MLPs)表示的函数,用作神经图形基元,已证明符合这些标准(不同程度),例如作为形状表示 as representations of shape [Martel等2021;公园等2019]和辐射场[刘等2020;米尔登霍尔等2020;Muller等2020,2021]。
这些方法的重要共同点是一种将神经网络输入映射到高维空间的编码,这是从紧凑模型中提取高近似质量的关键。这些编码中最成功的是可训练的、特定任务的数据结构[Liu等2020;高川等2021],它们承担了很大一部分的学习任务。这使得可以使用更小、更高效的MLPs成为可能。然而,这种数据结构依赖于启发式和结构修改 heuristics and structural modifications(如剪枝、分裂或合并),这可能会使训练过程复杂化,将方法限制为特定的任务,或限制gpus的性能,因为控制流control flow和指针追逐pointer chasing非常昂贵。
我们通过多分辨率哈希编码 multiresolution hash encoding来解决这些问题,它是自适应的和高效的,独立于任务。它只由两个值配置——参数的数量T和预期的最佳分辨率Nmax——经过几秒钟的训练,在各种任务上产生最先进的质量(图1)。
与任务无关的自适应性和效率的关键是哈希表的多分辨率层次结构multiresolution hierarchy:
- 自适应:我们将一串网格映射到相应的固定大小的特征向量数组。在粗分辨率下,从网格点到数组条目有一个1:1的映射。在精细分辨率下,数组被视为一个哈希表,并使用空间哈希函数进行索引,其中多个网格点为每个数组条目起别名。这种哈希碰撞导致碰撞训练梯度达到平均水平,这意味着最大的梯度——那些与损失函数最相关的梯度——将占主导地位。因此,哈希表自动对具有最重要精细细节的稀疏区域进行优先考虑。与之前的工作不同,在训练期间的任何时候都不需要对数据结构进行结构性更新。
- 高效性:我们的哈希表查找是O(1)的,不需要控制流。这可以很好地映射到现代gpu,避免了树形遍历中固有的执行分歧 execution divergence和串行指针追逐serial pointer-chasing。可以并行查询所有分辨率的哈希表。
我们在四个具有代表性的任务中验证了我们的多分辨率哈希编码(见图1):
- Gigapixel image十亿像素图像:MLP学习从2D坐标到高分辨率图像的RGB颜色的映射。
- Neural signed distance functions神经符号距离函数 (SDF):MLP学习从3D坐标到到曲面的距离的映射。
- Neural radiance caching神经辐射缓存(NRC):MLP从蒙特卡罗路径示踪器中学习给定场景的5D光场。
- Neural radiance and density fields神经辐射和密度场(NeRF):MLP从图像观测和相应的透视变换中学习给定场景的3D密度和5D光场。
接下来,我们首先回顾之前的神经网络编码(第2节),然后描述我们的编码(第3节)及其实现(第4节),最后是我们的实验(第5节)和第5节)的讨论(第6节)。
2 BACKGROUND AND RELATED WORK
早期将机器学习模型的输入编码到高维空间的例子包括独热编码one-hot encoding[Harris和Harris2013]和内核技巧the kernel trick[狄奥多里迪斯2008],这样,复杂的数据排列就可以实现线性可分。
对于神经网络,输入编码已被证明在循环结构的注意组件attention components of recurrent architectures中有用[Gehring等2017],随后,transformers [Vaswani等2017],它们帮助神经网络识别它当前正在处理的位置。Vaswani等人[2017]将标量位置![]() 编码为
编码为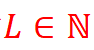 正弦和余弦函数的多分辨率序列
正弦和余弦函数的多分辨率序列

这已被应用于计算机图形学中,以编码NeRF算法中的空间方向变化的光场和体积密度[Mildenhall等人,2020]。该光场的五个维度使用上述公式进行独立编码;这后来被扩展到随机定向的平行波前randomly oriented parallel wavefronts [Tancik等人2020]和详细水平滤波level-of-detail filtering [Barron等人2021]。我们将把这个编码家族称为频率编码frequency encodings。值得注意的是,频率编码之后的线性变换已经被用于其他计算机图形任务,如近似能见度函数 approximating the visibility function [Annen等人,2007;Jansen和Bavoil,2010]。
Muller等人[2019;2020]提出了一种a continuous variant 连续变体of the one-hot encoding based on rasterizing 栅格化 a kernel,即one-blob encoding,它可以在有限域内以单尺度为代价获得比频率编码更精确的结果。
Parametric encodings参数编码。最近,通过参数编码模糊了经典数据结构和神经方法之间的界限,取得了最先进的结果。其思想是在辅助数据结构中安排额外的可训练参数(beyond权重和偏差),如网格[Chabra等2020;Jiang等2020;刘等2020;Mehta等2021;彭等2020a;孙等2021;Yu等2021a]或树[高川等2021],并根据输入向量x∈Rd查找和(选择性地)插入这些参数。这种安排用更大的内存占用换取更小的计算成本:对于通过网络向后传播的每个梯度,完全连接的MLP网络中的每个权重都必须更新,对于可训练的输入编码参数(“特征向量”),只有非常小的数量受到影响。例如,使用特征向量的三次插值的三维网格,对于每个样本反向传播到编码,只需要更新8个这样的网格点。通过这种方式,尽管参数编码的参数总数比固定的输入编码要高得多,但在训练期间,更新所需的FLOPs和内存访问的数量并没有显著增加。通过减少MLP的大小,这种参数模型通常可以被训练为在不牺牲近似质量的情况下更快地收敛。
另一种参数化方法使用域Rd的树形细分tree subdivision,其中一个大型的辅助坐标编码器神经网络auxiliary coordinate encoder neural network(ACORN)[Marteletal.2021]被训练在x附近的叶节点中输出密集的特征网格。这些密集的特征网格,大约有10 000 个条目,然后被线性插值,如Liu等人[2020]。与之前的参数编码相比,这种方法往往会产生更大程度的自适应性,尽管计算成本更大,只有当足够多的输入x进入每个叶节点时才能摊销amortized。

图2。演示了用于存储可训练特征嵌入的不同编码和参数化数据结构的重构质量。使用我们的快速NeRF实现(第5.4节)对每个配置进行了11 000 步的训练,只改变输入编码。每张图像的数量、可训练参数(MLP权重+编码参数)、训练时间和重建精度(PSNR)如图所示。我们的编码(e)具有相似的可训练参数总数,比频率编码(b)训练速度超过8×faster,由于参数更新的稀疏性和更小的MLP。增加参数的数量(f)进一步提高了重建的精度,而不显著增加训练时间。
Sparse parametric encodings稀疏参数编码,虽然现有的参数编码往往比它们的非参数编码前辈产生更高的精度,但它们在效率和多功能性方面也有缺点。可训练特征的密集网格Dense grids of trainable features比神经网络的权值neural network weights消耗更多的内存。为了说明权衡和激励我们的方法,图2显示了几种不同编码对神经辐射场重建质量的影响。在没有任何所有(a)的输入编码的情况下,网络只能学习一个相当平滑的位置函数,导致光场的近似较差。频率编码(b)允许相同的中等大小的网络(8个隐藏层,每一个256层宽)来更准确地表示场景。中间的图像(c)将一个较小的网络与R16中1283个三边早期插值特征向量trilinearly interpolated feature vectors的密集网格配对,总共有3360万个可训练参数。由于每个样本只影响8个网格点,因此每个样本可以有效地更新大量可训练的参数。
然而,密集的网格在两方面都是浪费的。首先,它为空白区域分配尽可能多的特征,就像它为表面附近的区域一样。参数的数量随着O(N3)的速度增长而增长,而感兴趣的可见表面的表面积仅随着O(N2)的速度增长而增长。在这个例子中,网格的分辨率为1283,但只有53 807 (2.57%)的单元格接触到可见表面。
- 自然场景表现出平滑性,促使人们使用多分辨率分解[Chibane等人,2020年;Hadadan等人,2021年]。图2(d)显示了使用一种编码的结果,其中插值的特征存储在8个同位置网格co-located grids中,分辨率从163到1733。这些被连接起来以形成网络的输入。尽管参数的数量不到(c)的一半,但重建质量是相似的。
如果感兴趣的表面是先验已知的,数据结构如八叉树[竹川等2021]或稀疏网格[Chabra等2020;基班等2020;哈达丹等2021;江等2020;刘等2020;彭等2020a]可用于剔除密集网格中未使用的特征。然而,在NeRF设置中,表面只在训练过程中出现。NSVF[Liu等人2020]和一些同时进行的作品[Sun等人2021;Yu等人2021a]采用多阶段、粗糙到精细的策略,将特征网格的区域逐步细化和剔除。虽然有效,但这导致了一个更复杂的训练过程,其中稀疏数据结构必须定期更新。
我们的方法-图2(e,f)-结合了这两种想法来减少浪费。我们将可训练的特征向量存储在一个紧凑的哈希表中,其大小是一个超参数T,可以调整参数的数量来交换重建质量。它不依赖于任何空间数据结构、训练过程中的渐进修剪、或编码场景几何的先验知识。与(d)中的多分辨率网格示例类似,我们使用多个以不同分辨率索引的单独哈希表,它们的插值输出在通过MLP之前被连接起来。尽管参数少了20倍,但重构质量与密集网格编码相当。
与之前使用空间哈希 spatial hashing[Teschner等人2003]进行三维重建[Nießner等人2013]不同,我们没有通过探测probing、桶bucketing或链接chaining等典型方法明确处理哈希函数的碰撞。相反,我们依赖于神经网络来学习消除哈希碰撞本身的歧义,避免控制流发散,降低实现复杂性和提高性能。另一个性能好处是哈希表的可预测内存布局,它与所表示的数据无关。虽然良好的缓存行为通常很难通过类似树的数据结构实现,但我们的哈希表可以针对缓存大小等低级架构细节进行微调。
3 MULTIRESOLUTION HASH ENCODING
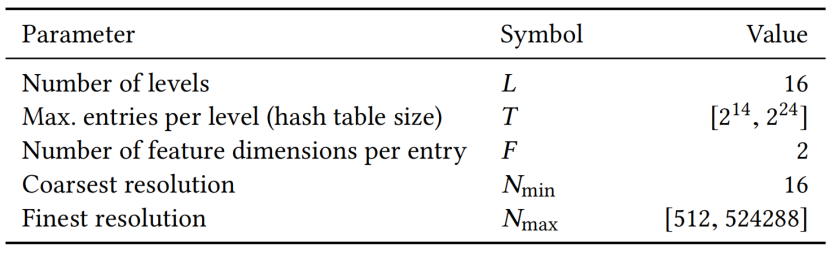
表1。哈希编码参数及其典型值。只有哈希表的大小T和max.分辨率Nmax需要调优到用例。
给定一个完全连接的神经网络![]() ,我们感兴趣的是其输入
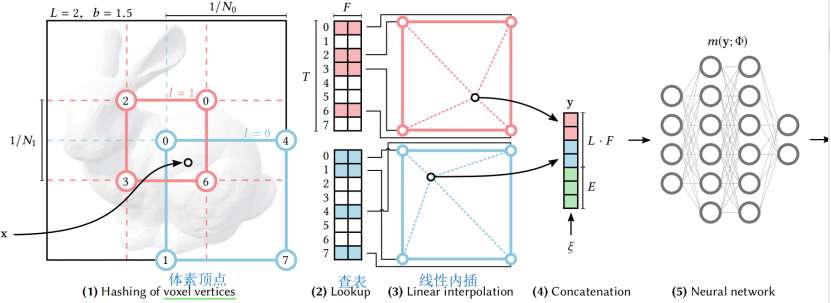
,我们感兴趣的是其输入![]() 的编码。它可以在广泛的应用中提高近似质量和训练速度,而不会产生显著的性能开销。我们的神经网络不仅有可训练的权值参数Φ,而且还有可训练的编码参数θ。这些被排列成L级,每个级别包含维度为F的T个特征向量。这些超参数的典型值如表1所示。图3说明了在我们的多分辨率哈希编码中执行的步骤。
的编码。它可以在广泛的应用中提高近似质量和训练速度,而不会产生显著的性能开销。我们的神经网络不仅有可训练的权值参数Φ,而且还有可训练的编码参数θ。这些被排列成L级,每个级别包含维度为F的T个特征向量。这些超参数的典型值如表1所示。图3说明了在我们的多分辨率哈希编码中执行的步骤。






性能与质量。选择哈希表大小提供了性能、内存和质量之间的权衡。T值越高,质量就越高,性能也就越低。在T中,内存占用是线性的,而质量和性能倾向于亚线性缩放scale sub-linearly。我们在图4中分析了T的影响,其中我们报告了三个神经图形基元的大范围T值的测试误差与训练时间。我们建议从业者使用T来调整编码到他们所期望的性能特征。
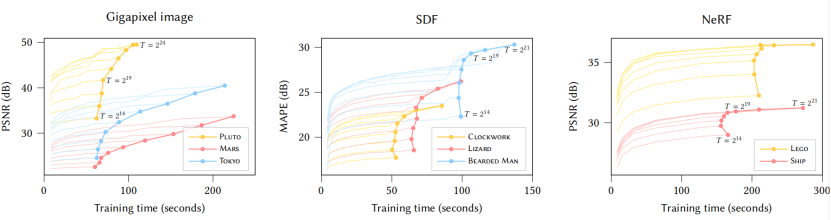
图4。主要曲线绘制了不同哈希表大小T的训练时间内的测试误差,这决定了可训练编码参数的数量。增加T可以改善重建,但代价是更高的内存使用和较慢的训练和推理。在T>219 上可以看到一个性能悬崖,我们的RTX 3090 GPU的缓存被过度订阅(对于SDF和NeRF尤其可见)。该图还显示了模型随着时间的收敛性,直到最终状态。这突出显示了仅仅在几秒钟后就已经获得了高质量的结果。收敛性的跳跃(在SDF训练结束时最明显)是由学习速率衰减引起的。对于NeRF和千像素图像,训练在31 000 步后完成,对于SDF在11 000 步后完成。
超参数L(级别数)和F(特征维数)也在质量和性能上进行了权衡,我们对图5中近似恒定数量的可训练编码参数θ进行了分析。在这个分析中,我们发现(F=2,L=16)在我们所有的应用中都是一个有利的帕累托最优Pareto optimum,所以我们在所有其他结果中使用这些值,并将它们推荐给从业者。
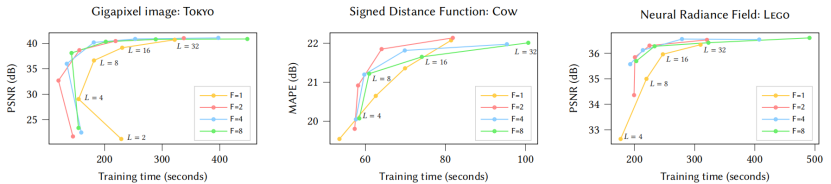
图5。哈希表级别的数量L是变化的,特征维度F的值固定,训练期间的测试误差。为了保持一个大致相等的可训练参数计数,SDF和NeRF根据F·T·L=224 设置哈希表大小T,而十亿像素的图像使用228。由于(F=2,L=16)接近于所有应用程序的最佳性能和质量(左上角),因此我们在所有结果中都使用了这种配置。F=1在我们的RTX 3090 GPU上是很慢的,因为原子的半精度积累atomic half-precision accumulation只对二维向量有效,而对标量不有效。对于NeRF和数千像素的图像,训练在31 000 步后完成,而SDF在11 000 步后完成。
隐式哈希碰撞解决方案Implicit hash collision resolution。这种编码在存在哈希冲突时能够忠实地重建场景,这可能显得违反直觉。它成功的关键在于,不同的分辨率水平有不同的优势,并相互补充。较粗的级别,因此编码作为一个整体,是单射的——也就是说,它们不会发生任何碰撞。然而,它们只能代表场景的低分辨率版本,因为它们提供的特性是从一个广泛间隔的点网格中线性插值的。相反,由于精细的网格分辨率,精细的级别可以捕获小的特性,但会遭受许多冲突——也就是说,不同的点hash到同一表条目2【注意,具有相等整数网格坐标⌊xl ⌋的附近输入x不被认为是碰撞;当两个具有不同整数坐标的点发生对同一表索引进行hash时,就会发生冲突。】。幸运的是,这种碰撞是伪随机分散的,统计上不太可能在一个给定点的每个层次上同时发生。
当训练样本以这种方式碰撞时,它们的梯度为平均。考虑到这些样本的最终重建的重要性很少是相等的。例如,辐射场可见表面上的一个点将对重建图像有很大的贡献(具有高能见度和高密度,这两项会成倍地影响反向传播梯度的大小),导致其表条目的巨大变化,而空格中的一个点碰巧引用同一条目将会有很多较小的重量。因此,更重要的样本的梯度主导了碰撞平均值,而有问题的别名表条目 the aliased table entry in question自然会以这样一种方式进行优化,以反映更高加权点的需要;不那么重要的点的最终输出将被多分辨率层次结构中的其他级别校正。
在线适应性Online adaptivity。请注意,如果输入x的分布在训练期间随时间变化,例如,如果它们集中在一个小区域,那么更精细的网格级别将经历更少的碰撞,并且可以学习到更准确的函数。换句话说,多分辨率哈希编码自动适应训练数据分布,继承了基于树的编码的好处[Takikawaetal.2021],没有特定任务的数据结构维护,可能导致训练过程中的离散跳跃。我们的应用程序之一,在第5.3节中的神经辐射缓存,不断地适应动画视点和3D内容,极大地受益于这个特性。
d线性插值d-linear interpolation。插入查询的哈希表条目可以确保编码enc(x;θ)和通过链规则其与神经网络m(enc(x;θ);Φ)的组成 by the chain rule its composition with the neural network是连续的。如果没有插值,网络输出中就会出现网格对齐的不连续点,这将导致不希望出现的块状外观。人们可能希望有高阶的光滑性,例如在近似偏微分方程时。计算机图形的一个具体例子是符号距离函数,在这种情况下,梯度∂m(enc(x;θ);Φ)/∂x,表面法线,理想情况下也应该是连续的。对于这个案例,我们在附录A中提供了一种低成本的方法。
4 IMPLEMENTATION
为了演示多分辨率哈希编码的速度,我们在CUDA中实现了它,并将其与 tiny-cuda-nn框架的快速全融合mlp集成[Muller2021]。3【我们还尝试了在Python(TensosorFlow[Abadietal.2015])中实现,但发现很难优化所需的哈希函数的动态索引。手工制作的内核的执行速度10×faster】我们发布了多分辨率哈希编码的源代码,作为对Muller[2021]的更新,以及https://github.com/NVlabs/instant-ngp上与神经图形基元相关的源代码。
Performance considerations性能考虑。为了优化推理和反向传播性能,我们以一半精度的速度存储哈希表条目(每个条目2字节)。此外,根据Micikevicius等人[2018],我们还维护了参数的主副本,用于稳定的混合精度参数更新。
为了优化使用GPU的缓存,我们逐级评估哈希表:当处理一批输入位置时,我们安排计算来查找所有输入的多分辨率哈希编码的第一级,然后是所有输入的第二级,以此类推。因此,在任何给定的时间内,只有少量的连续哈希表必须驻留在缓存中,这取决于GPU上可用的并行性的程度。重要的是,这种计算结构自动很好地利用了可用的缓存和并行性来实现广泛的哈希表大小T。
在我们的硬件上,只要哈希表的大小保持在T≤2 19 以下,编码的性能就会大致保持不变。超过此阈值后,性能将开始显著下降;请参见图4。这可以用我们的NVIDIA RTX 3090GPU的6 MB L2缓存来解释,它对于2·T·F>6·2 20 [F=6]的单个哈希表来说就太小了。
每次查找的最优特征维数F取决于GPU体系结构。一方面,在前面提到的流方法中,少数F有利于缓存局部性,但另一方面,大的F通过允许F宽的向量加载指令F -wide vector load instructions而有利于内存一致性。F=2在我们的GPU上提供了最好的成本质量权衡,我们在所有的实验中都使用了它;见图5。
MLP architecture。在所有的任务中,除了我们后面将描述的NeRF之外,我们使用了一个带有两个隐藏层的MLP,其宽度为64个神经元和校正线性单元(ReLU)激活函数。损失和输出激活的选择是特定于任务的,并将在各自的小节中详细介绍。
Initialization。我们根据Glorot和Bengio[2010]初始化神经网络的权值,以提供贯穿整个神经网络层的激活及其梯度的合理尺度。我们使用均匀分布U(−10−4,10−4)初始化哈希表条目,以提供少量的随机性,同时鼓励初始预测接近于零。这种初始化在我们所有的任务中都很好。我们还尝试了各种不同的分布,包括零初始化,所有这些都导致了一个非常略差的初始收敛速度。哈希表似乎对初始化方案具有鲁棒性。
Training。我们通过应用Adam[Kingma和Ba2014]来联合训练神经网络的权值和哈希表条目,其中我们设置了β1=0.9,β2=0.99,ϵ=10−15。β1和β2的选择只有很小的差异,但当ϵ=10−15的梯度是稀疏和弱的情况下,可以显著加速哈希表项的收敛。为了防止长时间训练后的差异,我们对神经网络权值应用弱L2正则化(因子10−6),但不应用于哈希表条目hash table entries。
最后,我们跳过了梯度恰好为0的哈希表项的Adam步骤。当梯度稀疏时,这节省了∼10%的性能,这是T≫BatchSize的常见情况。尽管这种启发式违反了Adam背后的一些假设,但我们没有观察到收敛性的退化。
Non-spatial input dimensions 非空间输入尺寸ξ ∈ RE 。多分辨率哈希编码的目标是相对较低维的空间坐标。我们所有的实验都在2D或3D中进行。然而,在学习光场时,向神经网络中输入辅助维度ξ ∈ RE,如视觉方向和材料参数,往往是有用的。在这种情况下,辅助维度可以用已建立的技术进行编码,这些技术的成本不会与维数呈超线性比例;我们使用神经辐射缓存中的单斑点编码[Mullere人2019][Muller等人2021]和NeRF中的球谐基础,类似于并行工作[Verbin等人2021;Yu等人2021a]。
5 EXPERIMENTS
为了突出编码的多功能性和高质量,我们将其与之前四种不同的计算机图形基元的编码进行了比较,这些编码受益于编码空间坐标。
5.1 Gigapixel Image Approximation
学习2D图像坐标到RGB颜色的映射已成为测试模型表示高频细节能力的流行基准[Martel等人2021年;Muller等人2019年;锡茨曼等人2020年;Tancik等人2020年]。最近在自适应坐标网络adaptive coordinate networks(ACORN)方面的突破[Marteletal.2021]在以最小的尺度拟合高达10亿像素的高保真度图像时,显示出了令人印象深刻的结果。我们将多分辨率哈希编码定位在同一任务上,并在几秒到几分钟内收敛到高保真图像(图4)。
相比之下,在图1中的东京全景图中,ACORN经过36.9小时的训练后,其PSNR值为38.59dB。使用相似数量的参数(T=2 24),我们的方法在2.5分钟的训练后达到了相同的PSNR,在4min后达到41.9dB的峰值。图6显示了我们的模型中包含的用在另一个图像上的各种哈希表大小T的细节级别。
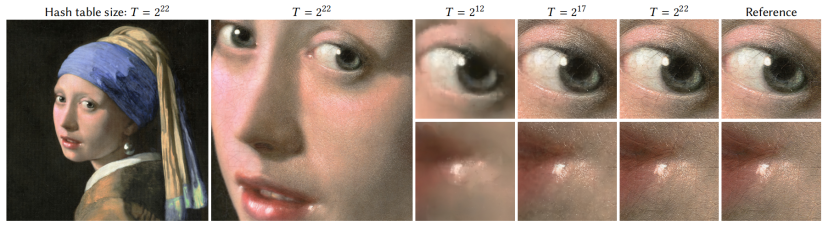
图6。用我们的多分辨率哈希编码近似出一个分辨率为20 000 ×23 466 (469M RGB像素)的RGB图像。当哈希表大小T为2 12 、2 17和2 22 时,所示的模型分别有117k、2.7M和47.5M的可训练参数。最后一个模型仅为输入自由度的3.4%,就实现了29.8dB的重构PSNR。“戴珍珠耳环的女孩”翻新©KooroshOrooj(CCBY-SA4.0)
很难直接比较我们的编码性能和ACORN;∼10的一个因素 a factor of ∼10 stems来自于我们使用的完全融合的CUDA内核,由tiny-cuda-nn框架提供[Muller2021]。输入编码允许使用比ACORN小得多的MLP,这占了剩下的10×-100×加速10×–100× speedup的大部分。也就是说,我们相信多分辨率哈希编码的最大的附加值是它的简单性。ACORN依赖于场景的自适应细分adaptive subdivision作为学习课程的一部分,这对我们的编码都不是必要的。
5.2 Signed Distance Functions
有符号距离函数(SDFs),其中 一个3D形状 表示 为 位置x 的零水平集 the zero level-set函数,被用于许多应用,包括模拟、路径规划、三维建模和视频游戏。DeepSDF [Park等人,2019年]使用一个大型的MLP来表示SDFs。Takikawa等人[2021](NGLOD)通过将一个更小的MLP与一个可训练特征向量的八叉树相结合,在质量和速度上都取得了最先进的成果。为了允许在性能和质量方面进行有意义的比较,我们在我们的框架中实现了NGLOD的一个优化版本。附录B描述了相关的实施细节,以及与SDFs的实时训练有关的细节。

图7。神经符号距离函数在四个场景上训练了11 000 步。频率编码[米尔登霍尔等人,2020年]努力捕捉这些复杂模型的尖锐细节。NGLOD[Takikawa等人,2021]获得了最高的视觉质量,代价是只训练近距离八叉树细胞内的SDF。我们的哈希编码在“并集上的交集”(IoU)方面表现出类似的数字质量 numeric quality,并且可以在场景的边界框中的任何地方进行计算。然而,它也显示出了视觉上不希望出现的表面粗糙度,我们将其归因于随机分布的哈希碰撞。有胡子的男人©OliverLaric(CCBY-NC-SA2.0)
在图7中,我们将NGLOD与我们的多分辨率哈希编码进行了比较。我们还展示了频率编码的直接应用[米尔登霍尔等人,2020年],以提供一个基线。通过使用针对参考形状而定制的数据结构,NGLOD获得了最高的视觉重建质量。然而,即使没有这样一个专用的数据结构,我们的编码在g-IoU4【g-IoU是被比较的一对形状的相交和联合的体积比;我们通过比较场景边界框内均匀分布的1.28亿点的SDFs的符号来衡量它。】度量方面接近于NGLOD的保真度,具有相似的性能和内存成本。在最佳网格分辨率的尺度上,哈希碰撞可见为不希望的表面粗糙度,并且不会随着训练时间的延长而消失。然而,SDF在训练量内的任何地方都有定义,而NGLOD只在八叉树中定义(即靠近表面)。这允许使用某些SDF渲染技术,如来自少量地表距离样本off-surface distance samples的近似软阴影approximate soft shadows [Evans2006],如相邻图所示。

5.3 Neural Radiance Caching
在神经辐射缓存中[Mulleretal.2021],MLP的任务是从特征缓冲区中预测逼真的像素颜色;见图8。MLP是对每个像素都独立运行的(即模型不是卷积的),因此特征缓冲区可以被视为包含三维坐标x以及附加特征的每个像素的特征向量。因此,我们可以直接将我们的多分辨率哈希编码应用于x,同时将所有附加特征作为辅助编码维度ξ,与编码位置连接,使用与Muller等人相同的编码[2021]。我们将我们的工作集成到Muller等人的神经辐射缓存的实现,因此参考他们的论文的实现细节。

图8。神经辐射缓存应用的总结[Mulleretal.2021]。MLP m(enc(x;θ);Φ) 的任务是从每个像素的特征缓冲区独立预测逼真的像素颜色。除其他变量外,特征缓冲区包含世界空间位置x,我们建议用我们的方法进行编码。神经辐射缓存是一个特别具有挑战性的应用程序,因为它在实时渲染过程中被在线监督。训练数据是一组从摄像机视图中不断产生的稀疏光路径。因此,神经网络和编码并不学习从特征到颜色的一般映射,而是它们不断地过度适应当前环境的形状和光线。为了支持动画内容,训练的预算只有每帧一毫秒。
对于逼真的渲染,神经辐射缓存通常只查询间接的路径贡献,这掩盖了其在第一次反射后的重建误差。相比之下,我们想强调神经辐射缓存的误差,从而通过使用我们的多分辨率哈希编码可以获得改进,因此我们直接在第一个路径顶点可视化神经辐射缓存。

图9。神经辐射缓存[Mulleretal.2021]从多分辨率哈希编码中获得了大大改进的质量,只有轻微的性能损失:1920×1080px的分辨率为133帧对147帧。为了演示多分辨率哈希与之前的三角形波编码的在线自适应性,我们展示了平滑摄像机运动的屏幕截图,从遥远的场景视图(左)开始,然后放大到复杂阴影的近距离视图(右)。在整个只需要几秒钟的摄像机运动过程中,神经辐射缓存不断地从稀疏的摄像机路径中学习,使缓存能够在摄像机暂时观察到的内容的尺度上学习(“过度拟合”)复杂的细节
图9显示,与Muller等人[2021]的三角波编码相比,我们的编码结果更清晰,同时只产生0.7ms的轻微性能开销,将1920×1080px的帧率从147帧率降低到133FPS。值得注意的是,神经辐射缓存是在渲染过程中从后台运行的路径跟踪器在线训练的,这意味着0.7ms的开销包括我们编码的训练和运行时成本。
5.4 Neural Radiance and Density Fields (NeRF)
在NeRF设置中,体积形状volumetric shape用空间(3D)密度函数和空间方向(5D)发射函数表示,我们用类似于Mildenhall等人[2020]的神经网络结构来表示。我们以与Mildenhall等人相同的方式训练模型:通过由已知相机姿态的2D RGB图像驱动的可微射线探测器 differentiable ray marcher进行反向传播。
Model Architecture。与其他三个应用程序不同的是,我们的NeRF模型由两个连接的mlp组成:一个密度MLP,然后是一个颜色MLP[米尔登霍尔等人,2020]。密度MLP将哈希编码的位置y=enc(x;θ)映射到16个输出值,第一个我们将其视为对数空间密度。颜色MLP添加了与视图相关的颜色变化。它的输入是 下面 的连接
- 密度MLP的16个输出值
- 观察方向投影到球面谐波基的前16个系数上(即达到4度)。这是一个在单位向量上的自然频率编码。
它的输出是一个RGB颜色三联体,我们可以在训练数据具有低动态范围(sRGB)时使用sigmoid激活,或者在它具有高动态范围(线性HDR)时使用指数exponential激活。我们更喜欢HDR训练数据,因为它更接近于物理光传输。这带来了许多优势,正如在同时的工作中也注意到的那样[mild等人2021]。
根据图10中的分析,我们的结果是用1隐层密度MLP和2隐层颜色MLP生成的,两者都是64个神经元宽。
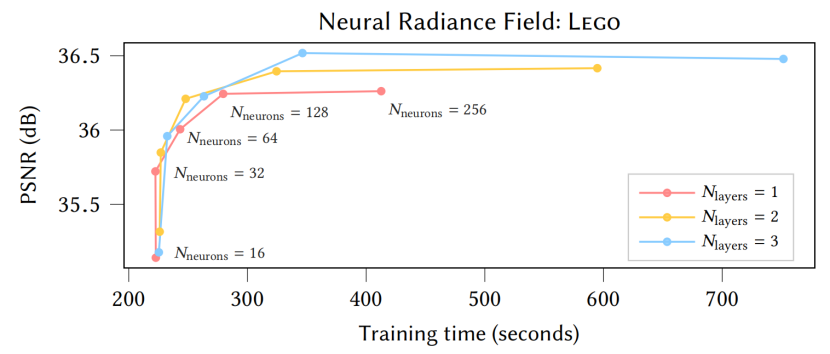
图10。MLP大小对乐高场景中测试误差与训练时间(31 000 个训练步)的影响。其他场景的行为几乎完全相同。每条曲线代表不同的MLP深度,其中颜色MLP有Nlayers隐藏层,密度MLP有1个隐藏层;我们没有观察到随着更深的密度MLPs的改善。这些曲线扫描了密度和颜色mlp的宽度(每个隐藏层中的神经元数量),从16到256。根据分析,我们选择Nlayers=2和Nneurons =64。
Accelerated ray marching。当沿着光线进行训练和渲染时,我们希望放置样本,使它们对图像的贡献有所一致,从而最大限度地减少计算的浪费。因此,我们通过保持一个粗糙地标记空空间和非空空间 coarsely marks empty vs. nonempty space的占用网格,将样本集中在表面附近。在大型场景中,我们另外将占用网格级联,并沿射线呈指数分布而不是均匀分布。附录C详细描述了这些程序。
在高分辨率下,合成的甚至真实场景可以在几秒内训练,并以60帧/秒渲染,而不需要缓存MLP输出[Garbin等2021;MLP等2021;Yu等2021b]。这种高性能使得它可以通过每像素对多个光线的强力跟踪brute-force tracing of multiple rays per pixel来添加诸如抗锯齿 anti-aliasing、运动模糊 motion blur和景深 depth of field等效果,如图12所示。
Comparison with direct voxel lookups。图11显示了一个消融,我们用单一线性矩阵乘法 a single linear matrix multiplication替换整个神经网络,本着(尽管不相同)并发基于直接体素的NeRF concurrent direct voxel-based NeRF的精神[Sun等人2021;Yu等人2021a]。虽然线性层能够再现与视图相关的效应,但与MLP相比,其质量明显受到了影响,MLP能够更好地捕获镜面效应,并解决插值多分辨率哈希表(表现为高频伪影)之间的哈希碰撞。幸运的是,由于MLP的小尺寸和高效的实现,它只比线性层贵15%。

图12。NeRF重建的模块化合成器和大型自然360场景。左边的图像花了5秒,在一个RTX 3090 GPU上以1080p的速度积累了128个样本,允许蛮力离焦效果 brute force defocus effects。右边的图像是在同一GPU上以每秒10帧运行的交互会话。

图11。在学习NeRF时,通过线性变换(没有神经网络)和MLP来传递我们的编码结果。这些模型被训练1min。MLP允许解决镜面细节,并减少由哈希碰撞引起的背景噪声。由于MLP的小尺寸和高效的实现,它只贵15%——非常值得显著改进的质量
Comparison with high-quality offline NeRF。与高质量的离线NeRF的比较。在表2中,我们将多分辨率哈希编码的峰值信噪比(PSNR)与NeRF[米尔登霍尔等2020]、mip-NeRF[Barron等2021]和NSVF[Liu等2020]进行了比较,这些都需要小时的训练。相比之下,我们列出了我们的方法经过1s到5min训练后的结果。我们的PSNR在15秒的训练后与NeRF和NSVF竞争,在5min的训练后与mip-NeRF竞争(尽管稍差)。
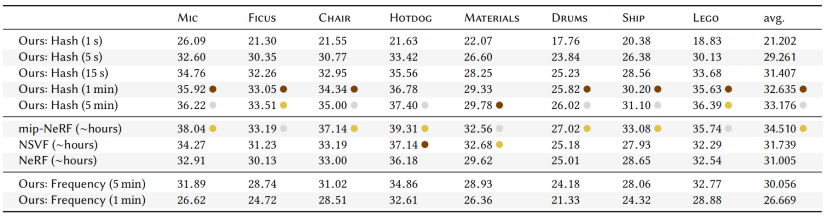
表2。我们的多分辨率哈希编码的峰值信噪比(PSNR)与 NeRF[米尔登霍尔等人2020]、mip-NeR [Barron等人2021]和NSVF [Liu等人2020],它们需要∼小时的训练。为了演示我们的方法的快速训练,我们列出了它经过1s到5min训练后的结果。对于每个场景,我们用金牌、银牌和铜牌来标记误差最小的方法。最后,为了演示我们的性能在多大程度上来自我们的哈希编码和我们实现的其他组件,我们评估了一个在框架中接近原始NeRF(“Ours: Frequency”)的体系结构。在训练∼5分钟后,它接近NeRF的质量,但在训练5s-15s后,它优于我们的完整方法。
一方面,我们的方法在具有高几何细节的场景中表现最好,如榕树Ficus和乐高,实现了所有方法中最好的PSNR。另一方面,mip-NeRF和NSVF在具有复杂的、依赖于视图的反射的场景上优于我们的方法,如材料;我们将此归因于更小的MLP,我们必须使用这些MLP来获得比这些竞争实现的几个数量级的加速。
最后,为了演示我们的性能在多大程度上来自于有效的实现和多分辨率的哈希编码,我们评估了一个近似于在我们的框架内实现的原始NeRF(“Ours: Frequency”)的体系结构。在训练∼5分钟后,它接近原始NeRF的质量,这验证了它的正确实现,但在训练更短的时间(5秒-15秒)后,我们的多分辨率哈希编码优于它。
6 DISCUSSION AND FUTURE WORK
Concatenation vs. reduction.串联vs.减少。在编码的最后,我们连接而不是减少(例如,通过求和)从每个分辨率中获得的F维特征向量。我们更喜欢连接有两个原因。首先,它允许对每个分辨率进行独立的、完全并行的处理。其次,将被编码的结果y的维数从LF降维到F可能太小,无法编码有用的信息。虽然F可以按比例增加,但它将使编码更加昂贵。
然而,我们认识到,可能有一些应用中,减少是有利的,例如当神经网络明显比编码更昂贵时,在这种情况下,增加F所增加的计算成本可能是不显著的。因此,我们主张默认情况下的连接,而不是作为一个硬性的规则。在我们的应用程序中,连接,加上F=2总是产生迄今为止最好的结果。
Microstructure due to hash collisions由哈希碰撞引起的微观结构。我们的编码的显著因素是少量的“颗粒状”微观结构,在学习的符号距离函数上最为明显(图1和图7)。颗粒度是MLP无法完全补偿的哈希碰撞的结果。我们相信,通过我们的编码在sdf上实现最先进的质量的关键将是找到一种克服这种微观结构的方法,例如通过过滤哈希表查找或通过在损失之前施加额外的平滑性。
Learning the hash function学习哈希函数。虽然我们目前优化哈希表的条目,但可以在将来也优化哈希函数。两种可能的途径是:(i)开发适于解析微分的连续哈希公式,或者(ii)应用能够有效探索离散函数空间的进化优化算法。
Generative setting生成设置。参数输入编码在生成设置中使用时,通常会将其特征排列在密集的网格中,然后由单独的生成网络填充,通常是CNN,如StyleGAN[Chan等2021;DeVries等2021;Peng等2020b]。我们的哈希编码增加了额外的复杂性,因为特征没有通过输入域以规则模式排列;也就是说,特征与规则的点网格不是双射的bijective。我们让未来的工作来决定如何最好地克服这一困难。
Other applications其他应用程序。我们感兴趣的是将多分辨率哈希编码应用于其他需要精确、高频拟合的低维任务。频率编码起源于transformer网络的注意机制[Vaswanietal.2017]。我们希望像我们这样的参数编码能够在基于注意力的任务中得到有意义的改进。
异质体积密度场Heterogenous volumetric density fields,如存储在VDB[博物馆2013,2021]数据结构中的云和烟雾,通常包括外部的空空间、内部的固体核心以及体积表面的稀疏细节。这使得它们非常适合我们的编码。在本文一起发布的代码中,我们包含了一个初步的实现,它直接从体积路径示踪器volumetric path tracer的噪声输出适合辐射和密度场。最初的结果很有希望,如图13所示,我们打算在未来的工作中进一步追求这个方向。

图13。从实时路径跟踪数据中训练NeRF云模型(b)的初步结果。在32ms范围内,我们的模型的一个1024×1024图像令人信服地接近于离线渲染的地面真实(a).我们的模型比运行相同时间(c).的GPU路径跟踪器显示出更少的噪声云数据是©华特迪士尼动画工作室(CCBY-SA3.0)
7 CONCLUSION
许多图形问题依赖于特定于任务的数据结构来利用手头问题的稀疏性或平滑性。我们的多分辨率哈希编码提供了一个实用的基于学习的替代方案,它自动专注于相关的细节,独立于任务。它的低开销允许它甚至被用于时间紧张的设置,如在线训练和推理。在神经网络输入编码的背景下,它是一个下降的drop-in替代,例如将NeRF加速了几个数量级,并匹配并发非神经三维重建技术concurrent non-neural 3D reconstruction techniques的性能。
在任何情况下,缓慢的计算过程,从 光线映射lightmap到神经网络的训练,都可能导致长迭代时间导致的令人沮丧的工作流 frustrating workflows[恩德顿和Wexler2011]。我们已经证明,以秒为单位的单gpu训练时间是可以达到的,允许神经方法应用于以前可能被忽略的地方。

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









